This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Now you can author data preparation transformations and edit them with the AWS Glue Studio visual editor. The AWS Glue Studio visual editor is a graphical interface that enables you to create, run, and monitor dataintegration jobs in AWS Glue. Let’s move on to the next step and query the table.
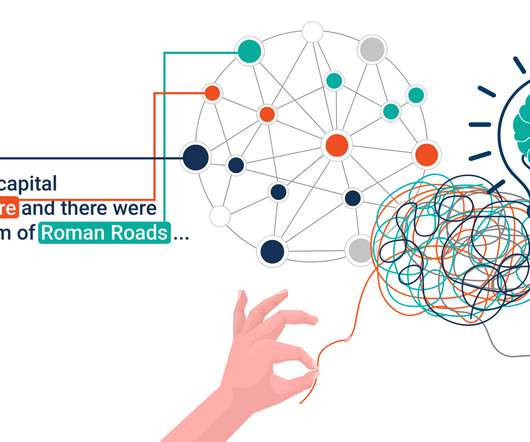
For efficient drug discovery, linked data is key. The actual process of dataintegration and the subsequent maintenance of knowledge requires a lot of time and effort. The post What Does 2000 Year Old Concrete Have to Do with Knowledge Graphs? appeared first on Ontotext.
In the modern data stack, there is a diverse set of destinations where data needs to be delivered. The newer “extract/load” tools seem to focus primarily on cloud data sources with schemas. Universal Developer Accessibility: Data distribution is a dataintegration problem and all the complexities that come with it.
Weaving the Semantic Web with Semantic Annotations and Linked Open Data. Ontotext was founded in 2000 with the Semantic Web in its genes and we had the chance to be part of the community of its pioneers. We rather see it as a new paradigm that is revolutionizing enterprise dataintegration and knowledge discovery.
But it is eminently possible that you were exposed to inaccurate data through no human fault.”. He goes on to explain: Reasons for inaccurate data. Integration of external data with complex structures. Big data is BIG. Metadata is the descriptions, definitions, and contextual information about your data.
Streaming ingestion from Amazon MSK into Amazon Redshift, represents a cutting-edge approach to real-time data processing and analysis. Amazon MSK serves as a highly scalable, and fully managed service for Apache Kafka, allowing for seamless collection and processing of vast streams of data. For MCU count per worker , choose 1.
In the modern data stack, there is a diverse set of destinations where data needs to be delivered. The newer “extract/load” tools seem to focus primarily on cloud data sources with schemas. Universal Developer Accessibility: Data distribution is a dataintegration problem and all the complexities that come with it.
On June 18th, Cloudera provided an exclusive preview of these capabilities, and more, with the introduction of Cloudera Data Platform (CDP), the industry’s first enterprise data cloud. Over 2000 customers and partners joined us in this live webinar featuring a first-look at our upcoming cloud-native CDP services.
AWS Glue is a serverless dataintegration service that makes it straightforward to discover, prepare, move, and integratedata from multiple sources for analytics, machine learning (ML), and application development. split(',') glue_jobname = Variable.get("glue_job_dag.glue_job_name").strip()
Ontotext started in 2000 as an R&D lab, led by now CEO Atanas Kiryakov, becoming one of the pioneers of the Semantic Web. Data sourcing – knowledge graphs enable deeper insights to be gained from distributed data. Domain knowledge must be linked to that data, requiring substantial ETL and dataintegration work.
Ontotext started in 2000 as an R&D lab, led by now CEO Atanas Kiryakov, becoming one of the pioneers of the Semantic Web. Data sourcing – knowledge graphs enable deeper insights to be gained from distributed data. Domain knowledge must be linked to that data, requiring substantial ETL and dataintegration work.
That is why we have used GraphDB , Ontotext Platform and our significant expertise in semantic dataintegration to show how we can improve the quality of ENTSO-E Transparency data and develop flexible analytics by leveraging the knowledge graph approach. Let’s take a closer look.
Talend Talend is an open-source dataintegration platform that provides a range of software and services suitable for big data, dataintegration, data management, data quality, cloud storage, and enterprise application integration. Less complex administration. High security and governance.
FineReport supports broad data sources from almost all mainstream databases through simple operations. The picture below displays the data sources that FineReport can connect to. The easy and fast dataintegration enables the users to generate a more comprehensive data analysis report. Data Visualization.
This inefficiency highlights the need to streamline processes and improve data management, including automated dataintegration. Our findings echo this insight, with the overwhelming majority of Oracle ERP finance teams (98%) experiencing dataintegration challenges.
Maintain a Single Source of Truth Ensuring dataintegrity is of utmost importance during migration. Centralizing your data into a single source of truth helps maintain accurate, up-to-date information accessible to all stakeholders.
These are valid fears, as companies that have already completed their cloud migrations reported integration challenges and user skills gaps as their largest hurdles during implementation, but with careful planning and team training, companies can expect a smooth transition from on-premises to cloud systems.
Additionally, fostering a culture of data literacy by training teams on data standards and best practices ensures that everyone contributes to maintaining a high standard of dataintegrity, positioning the organization for long-term success. The Simba Story: Advancing Leadership in Data Connectivity Download Now 4.
Managing DataIntegrity. Before rolling the new process out, the company needed to address dataintegrity, a normal stage in any new software implementation project. Following the dataintegrity phase, the company focused on setting up the correct processes and on rightsizing the project.
And for financial data, integrate and pull directly from your existing ERP to create reports. Assisting with the creation and dissemination of board reports is just one aspect that board management software covers. Users can also often schedule meetings, share minutes, and provide insights beyond what’s on the page.
Data mapping is essential for integration, migration, and transformation of different data sets; it allows you to improve your data quality by preventing duplications and redundancies in your data fields. Data mapping helps standardize, visualize, and understand data across different systems and applications.
It streamlines dataintegration, ensures real-time access to accurate information, enhances collaboration, and provides the flexibility needed to adapt to evolving ERP systems and business requirements.
Thorough data preparation and control act as the foundation, allowing finance teams to leverage the full power of Oracle’s AI and transform their financial operations, now or in the future. These tools excel at dataintegration, consolidating information from various financial systems (ERP, CRM, legacy) into a central hub.
Leaning on Master Data Management (MDM), the creation of a single, reliable source of master data, ensures the uniformity, accuracy, stewardship, and accountability of shared data assets. With Power ON’s user management features, you can enhance collaboration and ensure robust data governance.
Batch processing pipelines are designed to decrease workloads by handling large volumes of data efficiently and can be useful for tasks such as data transformation, data aggregation, dataintegration , and data loading into a destination system. What is the difference between ETL and data pipeline?
This fragmented EPM landscape leads to serious dataintegration issues, as incompatible formats and structures complicate the consolidation and analysis of financial data. Our research highlights this challenge, revealing that 98% of finance teams face difficulties with dataintegration.
This fragmented software landscape creates significant dataintegration challenges due to incompatible data formats, structures, and systems, making it difficult to consolidate and analyze data effectively. When your data is siloed between departments or business functions, the view of your organization grows muddled.
Unable to collaborate effectively, your team will struggle to promptly respond to leadership needs and custom data queries required to navigate your business through troubled waters. Limited data accessibility: Restricted data access obstructs comprehensive reporting and limits visibility into business processes.
PIM’s dataintegration tools also enable you to blend PIM data with other data sources such as Google Analytics and financial data to provide actionable insights into your product performance.
3) Data Fragmentation and Inconsistency Large organizations often grapple with disparate, ungoverned data sets scattered across various spreadsheets and systems. This fragmentation results in the lack of a reliable, single source of truth for budget data, making it challenging to maintain dataintegrity and consistency.
This allows for immediate integration of actuals into forecasts and reports, ensuring your analysis is always up-to-date and based on the latest information. Seamless DataIntegration : insightsoftware EPM automates dataintegration and consolidation, eliminating your need for manual manipulation.
Reduced Accuracy and Control: Your team may be forced to rely on outdated or inaccurate data if they lack the ability to build custom reports and verify dataintegrity. Decision Paralysis: Without access to the right data at the right time, you will struggle to make confident decisions.
. • Finance teams may find it challenging to gain insights from disparate data sources, hindering their ability to identify trends, risks, and opportunities on time. Addressing these challenges often requires investing in dataintegration solutions or third-party dataintegration tools.
DataIntegrity Maintenance: Data cleansing processes detect and rectify dataintegrity issues, such as duplicate entries or conflicting data. This proactive approach mitigates concerns regarding data reliability and fosters trust in the information.
Your accounting team faces the challenge of harmonizing data from various software systems. They need to be able to drill into journals, balances, sub-ledger accounting, and transactions to find and quickly fix reconciliation or dataintegrity issues, which can be maintained throughout.
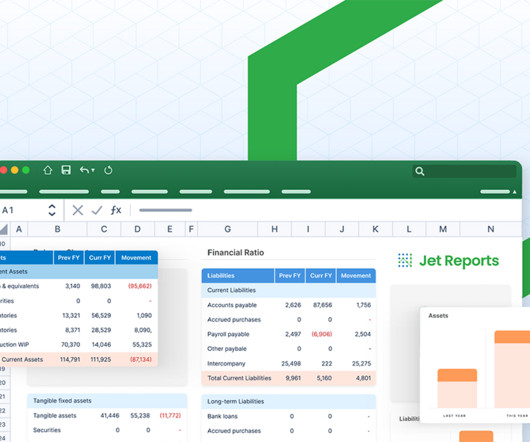
Maintain dataintegrity: Preserve the accuracy of your financial data. This allows you to reuse your existing NAV reports, saving time and money on report rebuilding. By leveraging Jet Reports for your move from NAV to BC, you can: Minimize downtime: Ensure a smooth transition to BC.
Certent Disclosure Management’s Microsoft integration allows you to drill into content lineage, providing a clear path of how data has evolved. You can see where variables come from and how they are being used, putting you in charge of your data. Reduce Disclosure Risk. Certent Disclosure Management 24.2:
Apache Iceberg is an open table format for huge analytic datasets designed to bring high-performance ACID (Atomicity, Consistency, Isolation, and Durability) transactions to big data.
First Name * Last Name * Phone Number Company Name * Job Title Hidden Industry Primary Financial System -- Select One -- Deltek Epicor Infor JD Edwards Microsoft MRI Software NetSuite Oracle Other Sage SAP Viewpoint Financial System Version -- Select One -- 24SevenOffice A+ AARO AccountEdge Accounting CS Accountmate Acumatica Alere Anaplan Aptean Assist (..)
First Name * Last Name * Phone Number Company Name * Job Title Hidden Industry Primary Financial System -- Select One -- Deltek Epicor Infor JD Edwards Microsoft MRI Software NetSuite Oracle Other Sage SAP SYSPRO Viewpoint Financial System Version -- Select One -- 24SevenOffice A+ AARO AccountEdge Accounting CS Accountmate Acumatica Alere Anaplan Aptean (..)
First Name * Last Name * Phone Number Company Name * Job Title Hidden Industry Primary Financial System -- Select One -- Deltek Epicor Infor JD Edwards Microsoft MRI Software NetSuite Oracle Other Sage SAP Viewpoint Financial System Version -- Select One -- 24SevenOffice A+ AARO AccountEdge Accounting CS Accountmate Acumatica Alere Anaplan Aptean Assist (..)
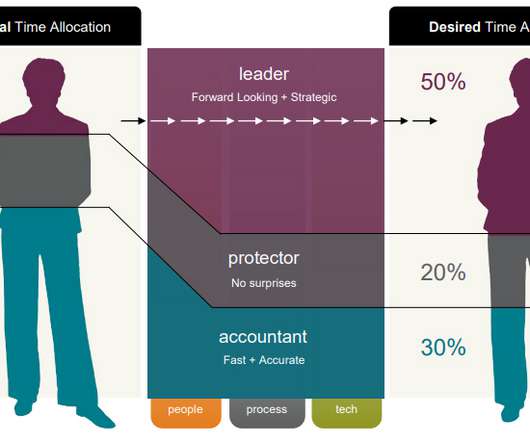
Deep data capabilities allow your CFO to find and analyze both financial and operational information by looking up a set of dimensions that are specific to your business. Near Real-Time DataIntegration with Your Systems and Built-in Forecasting Modules.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content