This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Anish has been a Lead DataScience consultant for various Fortune 500 customers for a long time and has helped over 2000 employees into the DataScience profession. Introduction Anish Mahapatra has is conducting an interactive DataHour session with us.
This article was published as a part of the DataScience Blogathon. Introduction Back in 2000, people used to purchase groceries from their local hypermarts. However, in the last 20 years, several online e-commerce stores have been launched.
The Web/e-Commerce tidal wave also brought a lot of hype and FOMO, which ultimately led to the Internet bubble burst (the dot-com crash) in the early 2000’s. That had and continues to have a very big and long-lasting impact. Are we heading for another round of hype / high hopes / exhilaration / FOMO / crash and burn with AI?
million people have been directly affected by natural disasters since 2000. Even though natural events such as floods, earthquakes or hurricanes are inevitable, I believe that their impact can be mitigated through the application of data and analytics. Data is the Fuel; DataScience is the Engine. Help from IBM.
Big data can be useful for all of these aspects of your campaign. PPC Hero talked about the evolving role of datascience in PPC. By carefully structuring your campaigns with big data, you can benefit from profitable PPC campaigns that deliver long-standing results for your business.
Other techniques include simple re-sampling, where the minority class is continuously re-sampled until the number of obtained observations matches the size of the majority class, and focused under-sampling, where the discarded observations from the majority class are carefully selected to be away from the decision boundary (Japkowicz, 2000).
Exploratory datascience and visualization: Access Iceberg tables through auto-discovered CDW connection in CML projects. Our imported flights table now contains the same data as the existing external hive table and we can quickly check the row counts by year to confirm: year _c1. 9 2000 5683047. …. 1 2008 7009728.
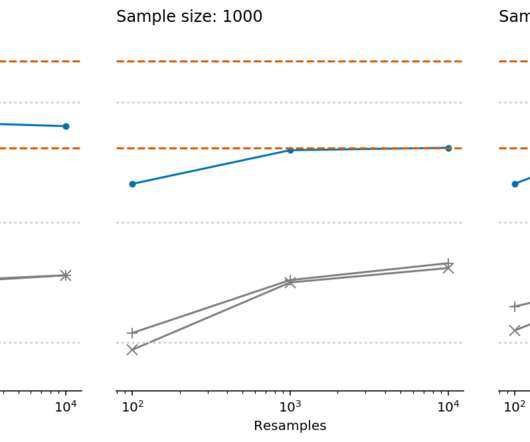
The output from running this function with the default arguments is plotted below. The output from running this function with the default arguments is plotted below. when asked to generate 95% CIs.
In 2000, Netflix offered Blockbuster a partnership, but the home movie provider turned it down. To reduce the impact of cognitive biases, use datascience tools that: Generate explanations for each AI decision. Do not rely on self-reporting, opinions, assertions about AI reliability, or a claimed lack of reliability.
Today’s enterprise datascience teams have one of the most challenging, yet most important roles to play in your business’s ML strategy. With almost all of the Fortune 500 and a majority of the Global 2000 relying on Cloudera for their most important data assets, Cloudera’s Machine Learning product (CML) is the way enterprises do ML.
xlarge 8 vCPUs / 24 GB 4 vCPUs / 12 GB 40 tasks (default) Up to 2000 mw1.2xlarge 16 vCPUs / 48 GB 8 vCPUs / 24 GB 80 tasks (default) Up to 4000 With the introduction of these larger environments, your Amazon Aurora metadata database will now use larger, memory-optimized instances powered by AWS Graviton2.
Datascience teams in industry must work with lots of text, one of the top four categories of data used in machine learning. That’s excellent for supporting really interesting workflow integrations in datascience work. Usually it’s human-generated text, but not always.
Suppose we want to compare the literate data of a country across decades. Let the number of literate people increased by 5000 in 2010-2020 whereas 3500 in 2000-2010. This statement may sound confusing so let us see an example!!! But we also note that the population growth in 2010-2020 is 3 times the other decade.
This blog aims to answer two questions: What is a universal data distribution service? Why does every organization need it when using a modern data stack? In the modern data stack, there is a diverse set of destinations where data needs to be delivered. This presents a unique set of challenges.
For example, due to computerization and algorithmic trading, Goldman Sachs decreased the number of people trading stocks from 600 to 2, from 2000 to 2016. By analyzing vast amounts of data, we unveil patterns and correlations that were previously hidden. The law of big numbers reinforces the reliability and accuracy of our analyses.
1000 Series 2000 Series 3000 Series 5000 Series, except the S55XX Click & Style Philips does recommend placing the shaving heads every 12 months of use. Philips Norelco SH30 Box Below is pictures of the box. These shaving heads work with many Philips Norelco shavers.
On June 18th, Cloudera provided an exclusive preview of these capabilities, and more, with the introduction of Cloudera Data Platform (CDP), the industry’s first enterprise data cloud. Over 2000 customers and partners joined us in this live webinar featuring a first-look at our upcoming cloud-native CDP services.
This blog aims to answer two questions: What is a universal data distribution service? Why does every organization need it when using a modern data stack? In the modern data stack, there is a diverse set of destinations where data needs to be delivered. This presents a unique set of challenges.
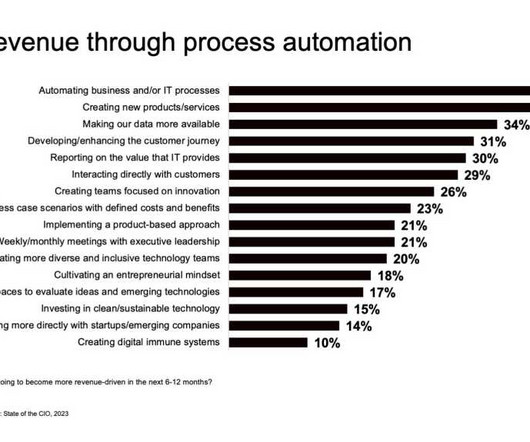
“Growth, profitability, productivity, and engagement are all now part of the CIO role that 20 years ago was all about internal operations,” says Herlihy, who has been an IT executive since landing his first CIO position in 2000. Revenue takes center stage Herlihy’s vision for top IT leadership is not an anomaly.
Datascience experiment result and performance analysis, for example, calculating model lift. Don’t forget even for your datascience use cases you can leverage Impala as a fast data cruncher with the awesome pandas dataframe feature of the Impyla library or as part of the Ibis framework.
Now, consider the relevance of the knowledge gained from a degree achieved in 2000 in an IT related discipline. If you look at the culture and fabric of information technology, it doesn’t take long to recognize that it has been changing rapidly and that change is faster and more intense than ever. How much has changed since then?
In fact, in a 2019 edition of Industrial Management & Data Systems, a research team led by Yu Nie noted that prior to the year 2000, there were only six chief data officers in the world. Clearly, data is becoming more important to organizations. The role of the chief data officer.
Dot Com Boom: For those that don’t know, around 2000 the WWW became popular and many new web companies were formed. Though when the dot com boom came everything changed! We hired all sorts of people from many backgrounds – most of them turned out to be amazing coders. It was awesome… until it wasn’t.
Due to multiple changes to the scale of the values depicted on the vertical axis, “Results Pages” values, which reflect search query volume, at the rightward end of the plot (corresponding to July 2004) are 2000 times larger than the values depicted at the leftward end (corresponding to November 1998). 2000): 451-476. [6] 2014): 276.
Want to advance your career in DataScience and Artificial Intelligence? deepaugmentusage AutoML for Data Augmentation was originally published in Insight Data on Medium, where people are continuing the conversation by highlighting and responding to this story. DeepAugment takes 4.2 x2large instance.
Leveraging data to replace the ‘gut feel’ on which too many business decisions are made enables change practitioners to separate perceptions from reality and decide which processes need the most focus. This Index proved that in almost 2000 companies, organizational health is closely linked to performance.
For a more contrived but impressive illustration of DBSCAN’s capabilities, let’s consider a toy example informally known as the “half-moons” dataset where each data point belongs to one of the two “half-moons”. from sklearn.datasets import make_moons #moons_X: Data, moon_y: Labels moons_X, moon_y = make_moons(n_samples = 2000).
Use customer lifetime value data to segment customers and tailor offerings to meet their desires and goals. Two very important things happened during the economic slowdown of the mid to late 2000’s.
About the authors: Neha Kumar is a member of the Solutions Team at Periscope Data by Sisense, providing architecture guidance and technical support for enterprise customers. Outside of work, Neha is pursuing a Masters in Information and DataScience from UC Berkeley and enjoys dancing and painting.
Biostatistics, 1(1):27-34, 03 2000. [2] If you do try this out, please let us know how it goes in the comments. References [1] Andrew Gelman. Should we take measurements at an intermediate design point? 2] Nist / sematech. e-handbook of statistical methods: Summary tables of useful fractional factorial designs , 2018 [3] Ulrike Groemping.
That was the Science, here comes the Technology… A Brief Hydrology of Data Lakes. One of the early promises of a Data Lake approach was that – once all relevant data had been ingested – this would be directly leveraged by Data Scientists to derive insight.
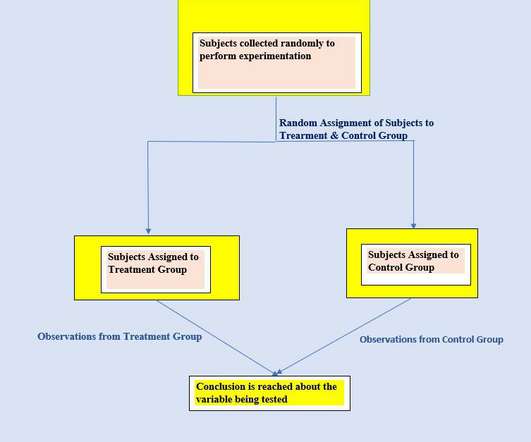
Suppose a data scientist works at The Hill Climber, a climbing shop in the Himalayas. She wants to evaluate the performance of the Ice Axe 2000. She finds these axes to be in very good shape after controlling for age, and concludes that the Ice Axe 2000 can be recommended on the basis of its durability.
The United States grew the least at only 2% from 2000 to 2016. Don’t miss the DataScience and Machine Learning Bake-Off on September 15th at 1:pm EDT. In 2016, life expectancy in the United States (78.5) was almost 4yrs less than the average of all other countries combined (82). To register and find the replay click here.
We explored these questions and more at our Bake-Offs and Show Floor Showdowns at our Data and Analytics Summit in Orlando with 4,000 of our closest D&A friends and family. The first featured analytics and BI platform Gartner Magic Quadrant leaders while the other showcased high interest datascience and machine learning platforms.
Look Forward to Enhanced Data Access With Fabric Improvements Microsoft recently introduced Fabric, a data management and analytics powerhouse that offers data movement, datascience, real-time analytics, and business intelligence within a single platform.
Data pipelines are designed to automate the flow of data, enabling efficient and reliable data movement for various purposes, such as data analytics, reporting, or integration with other systems. There are many types of data pipelines, and all of them include extract, transform, load (ETL) to some extent.
Enhanced Skill Development: Building your own software allows your application team to develop new skills in datascience, machine learning, and analytics. Higher Costs: In-house development incurs costs not only in terms of hiring or training datascience experts but also in ongoing maintenance, updates, and potential debugging.
The solution offers data movement, datascience, real-time analytics, and business intelligence within a single platform. Microsoft recently introduced a comprehensive analytics solution for its enterprise customers, Microsoft Fabric.
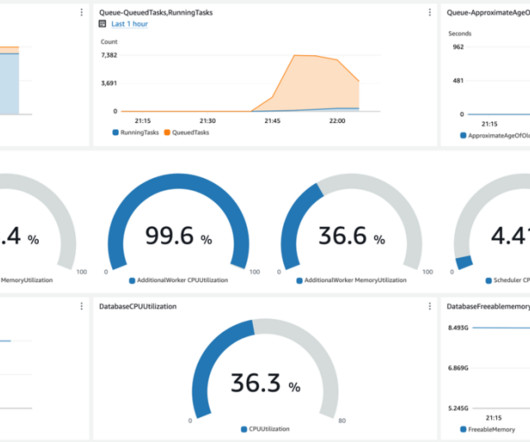
Scott Rigney is a Senior Technical Product Manager with AWS and has expertise in analytics, datascience, and machine learning. He is passionate about building software products that enable enterprises to make data-driven decisions and drive innovation. He is responsible for building software artifacts to help customers.
We did two Bake-Offs at the Gartner Data and Analytics Summit in London last week. The first featured analytics and BI platform Gartner Magic Quadrant leaders while the other showcased high interest datascience and machine learning platforms. In 2000, the Netherlands had 8.5
Based on Kaggle’s State of DataScience Survey 2017 (Sample size: 10,153). The text in the above exhibit is not that clear [2] , so here are the 20 top challenges [3] faced by those running DataScience teams in human-readable form: #. Dirty Data. Lack of DataScience talent in the organization.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content