This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
million people have been directly affected by natural disasters since 2000. Even though natural events such as floods, earthquakes or hurricanes are inevitable, I believe that their impact can be mitigated through the application of data and analytics. Data is the Fuel; DataScience is the Engine. Help from IBM.
Datascience experiment result and performance analysis, for example, calculating model lift. Exhaustive cost-based query planning depends on having up to date and reliable statistics which are expensive to generate and even harder to maintain, making their existence unrealistic in real workloads.
Suppose we want to compare the literate data of a country across decades. Let the number of literate people increased by 5000 in 2010-2020 whereas 3500 in 2000-2010. Statistics Essential for Dummies by D. Rumsey Statistical Reasoning Course by Stanford Ligunita Introduction to the Practice of Statistics by D.
Today’s enterprise datascience teams have one of the most challenging, yet most important roles to play in your business’s ML strategy. With almost all of the Fortune 500 and a majority of the Global 2000 relying on Cloudera for their most important data assets, Cloudera’s Machine Learning product (CML) is the way enterprises do ML.
The output from running this function with the default arguments is plotted below. The output from running this function with the default arguments is plotted below. when asked to generate 95% CIs.
Due to multiple changes to the scale of the values depicted on the vertical axis, “Results Pages” values, which reflect search query volume, at the rightward end of the plot (corresponding to July 2004) are 2000 times larger than the values depicted at the leftward end (corresponding to November 1998). Forecasting data and methods". [2]
Analyze is a process that you can run in Redshift that will scan all of your tables, or a specified table, and gathers statistics about that table. These statistics are used to guide the query planner in finding the best way to process the data. Conclusion.
If $Y$ at that point is (statistically and practically) significantly better than our current operating point, and that point is deemed acceptable, we update the system parameters to this better value. Biostatistics, 1(1):27-34, 03 2000. [2] Journal of Statistical Software, 56(1):1-56, 2014. [5] Testing Statistical Hypotheses.
That was the Science, here comes the Technology… A Brief Hydrology of Data Lakes. Even back then, these were used for activities such as Analytics , Dashboards , Statistical Modelling , Data Mining and Advanced Visualisation. This is the essence of Convergent Evolution.
1]" Statistics, as a discipline, was largely developed in a small data world. Data was expensive to gather, and therefore decisions to collect data were generally well-considered. Implicitly, there was a prior belief about some interesting causal mechanism or an underlying hypothesis motivating the collection of the data.
On the other hand, fledgling products often have neither the statistical power to identify the effects of small incremental changes, nor the luxury to contemplate small improvements. 0.71% Non-EDM users (2,000 impressions): Treatment Impressions Sales Conversion Rate Delta From Control [Artist Title] (control) 2000 80 4.00±0.86%
We try use the Bake-Offs as a platform for data for good. Rather than just using some solely fun data like football/ soccer statistics – go Mo Salah! – this year, we used population health data. Last year we did loneliness and happiness data. The United States grew the least at only 2% from 2000 to 2016.
We explored these questions and more at our Bake-Offs and Show Floor Showdowns at our Data and Analytics Summit in Orlando with 4,000 of our closest D&A friends and family. The first featured analytics and BI platform Gartner Magic Quadrant leaders while the other showcased high interest datascience and machine learning platforms.
Data pipelines are designed to automate the flow of data, enabling efficient and reliable data movement for various purposes, such as data analytics, reporting, or integration with other systems. There are many types of data pipelines, and all of them include extract, transform, load (ETL) to some extent.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



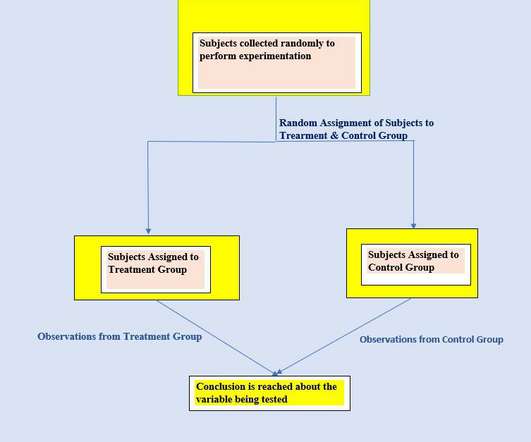

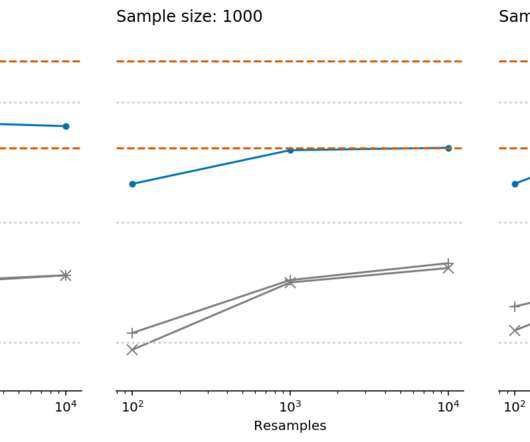

















Let's personalize your content