This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
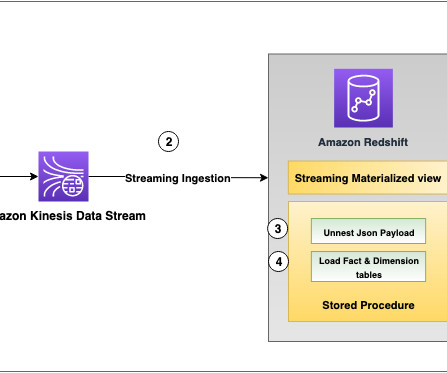
Amazon Redshift is a fully managed, AI-powered cloud datawarehouse that delivers the best price-performance for your analytics workloads at any scale. This will take a few minutes to run and will establish a query history for the tpcds data. Choose Run all on each notebook tab. Add your schema to the path.
This blog is intended to give an overview of the considerations you’ll want to make as you build your Redshift datawarehouse to ensure you are getting the optimal performance. This results in less joins between the metric data in fact tables, and the dimensions. So let’s dive in! OLTP vs OLAP.
The general availability covers Iceberg running within some of the key data services in CDP, including Cloudera DataWarehouse ( CDW ), Cloudera Data Engineering ( CDE ), and Cloudera Machine Learning ( CML ). Cloudera Data Engineering (Spark 3) with Airflow enabled. 9 2000 5683047. …. 1 2008 7009728.
And then I moved from Madison, Wisconsin to San Francisco in 2000, to chase the dotcom dream. After having rebuilt their datawarehouse, I decided to take a little bit more of a pointed role, and I joined Oracle as a database performance engineer. Let’s talk about big data and Apache Impala. Michael Moreno: Nice!
Cloudera DataWarehouse (CDW) running Hive has previously supported creating materialized views against Hive ACID source tables. release and the matching CDW Private Cloud Data Services release, Hive also supports creating, using, and rebuilding materialized views for Iceberg table format.
You can have multiple internal applications such as databases, datawarehouses, or other systems where DNS names are not publicly resolvable. You can now use MSK Connect to privately connect with databases, datawarehouses, and other resources in your VPC to comply with your security needs.
This integration simplifies the authentication and authorization process for Amazon Redshift users using Query Editor V2 or Amazon Quicksight , making it easier for them to securely access your datawarehouse. Note: Your organization’s IdC instance must be in the same region as the Amazon Redshift datawarehouse you’re connecting to.
Amazon Redshift is a fully managed, scalable cloud datawarehouse that accelerates your time to insights with fast, easy, and secure analytics at scale. Tens of thousands of customers rely on Amazon Redshift to analyze exabytes of data and run complex analytical queries, making it the widely used cloud datawarehouse.
The company, listed on both the National Stock Exchange and the Bombay Stock Exchange, operates three amusement parks in Kochi, Bengaluru, and Hyderabad that were set up in 2000, 2005, and 2016, respectively, and plans to open two more amusement parks in the near future, in Chennai and Bhubaneswar. One pulse sends 150 bytes of data.
In the modern data stack, there is a diverse set of destinations where data needs to be delivered. The newer “extract/load” tools seem to focus primarily on cloud data sources with schemas. This presents a unique set of challenges. and don’t necessarily have schemas.
This led to the birth of separate systems for reporting: the enterprise datawarehouse. For the first time, the focus of a system became business questions, where data was denormalized. A shift emerged around 2000 with the initial discussions regarding digital transformation.
Amazon Redshift Serverless makes it easy to run and scale analytics in seconds without the need to set up and manage datawarehouse clusters. Customers use their preferred SQL clients to analyze their data in Redshift Serverless. An Redshift Serverless datawarehouse. If you don’t have one, you can sign up for one.
In fact, in a 2019 edition of Industrial Management & Data Systems, a research team led by Yu Nie noted that prior to the year 2000, there were only six chief data officers in the world. Clearly, data is becoming more important to organizations. This is one approach to solving the challenge of data silos.
In the modern data stack, there is a diverse set of destinations where data needs to be delivered. The newer “extract/load” tools seem to focus primarily on cloud data sources with schemas. This presents a unique set of challenges. and don’t necessarily have schemas.
2000 years ago, HIPAA could be summed up in four words: keep your mouth shut. But all of this information is scattered throughout multiple layers of the healthcare data ecosystem. The data capture layer includes EHRs, mobile devices, wearables and data entry from clinical trials. Alas, that time is long gone. .
These performance issues can be mitigated by storing your data entities outside the box, in your own database (BYOD). Even though Microsoft provides over 2000 out-of-the-box data entities, most customers spend significant amounts of time and money to customize their data entities. Costly and Time-Consuming.
Watch our first video to learn how Snowflake has the built-in capability to record details about every query and how to use query tags to tag each query with up to 2000 characters of text. To help you better understand the ins and outs of using Snowflake and its unique features, we’ve developed a demo series called Sirius About Snowflake.
Create the AWS Glue Data Catalog database The AWS Glue Data Catalog contains references to data that is used as sources and targets of your extract, transform, and load (ETL) jobs in AWS Glue. To create your datawarehouse or data lake, you must catalog this data.
Why focus on the Global 2000 accounts? Therefore, Cloudera’s plan is to meet customers where they are today with their enterprise data platforms. The goal is to focus on helping customers that already have a datawarehouse and want to move quickly to incorporate machine learning models in a lifecycle manner. Bottom Line.
Since the year 2000, new discoveries are coming at a fast and furious pace in many technology sectors, including software, material science, neuroscience, and genetics. We live in an age of unprecedented speed and breadth of technological change.
That was the Science, here comes the Technology… A Brief Hydrology of Data Lakes. This is where the observant reader will see the concept of Convergent Evolution playing out in the data arena as well as the Natural World. This is the essence of Convergent Evolution. In Closing.
It definitely depends on the type of data, no one method is always better than the other. For a large volume of structured data, for example, a customer master or datawarehouse, where there are many stakeholders in your organization who need to see different subsets, tokenization is generally better. This stuff works.
Organisations need to ensure that they can not only locate all relevant personal data about the individual, but also have the ability to extract or delete that data upon request and in a timely manner. When the world waited with bated breath for the clocks to tick over to 2000, very few computer failures were reported.
The Impact of Tariffs on Equipment Leasing: What Businesses Need to Know Watch Now " * " indicates required fields This field is hidden when viewing the form Select Your Closest Time Zone -- Select One -- This field is hidden when viewing the form Platform * First Choice Second Choice Third Choice Use Case * -- Select One -- I'm a current user (..)
Certent: Agile Disclosure Management for the Busy CFO Download Now: " * " indicates required fields This field is hidden when viewing the form Select Your Closest Time Zone -- Select One -- This field is hidden when viewing the form Platform * First Choice Second Choice Third Choice Use Case * -- Select One -- I'm a current user and updating (..)
Certent: Agile Disclosure Management for the Busy CFO Download Now: " * " indicates required fields This field is hidden when viewing the form Select Your Closest Time Zone -- Select One -- This field is hidden when viewing the form Platform * First Choice Second Choice Third Choice Use Case * -- Select One -- I'm a current user and updating (..)
Certent: Agile Disclosure Management for the Busy CFO Download Now: " * " indicates required fields This field is hidden when viewing the form Select Your Closest Time Zone -- Select One -- This field is hidden when viewing the form Platform * First Choice Second Choice Third Choice Use Case * -- Select One -- I'm a current user and updating (..)
Certent: Agile Disclosure Management for the Busy CFO Download Now: " * " indicates required fields This field is hidden when viewing the form Select Your Closest Time Zone -- Select One -- This field is hidden when viewing the form Platform * First Choice Second Choice Third Choice Use Case * -- Select One -- I'm a current user and updating (..)
Unlocking the Power of AI in Logi Symphony Watch Now " * " indicates required fields Hidden Select Your Closest Time Zone -- Select One -- Hidden Platform * First Choice Second Choice Third Choice Use Case * -- Select One -- I'm a current user and updating my application I'm a current user and interested in expanding usage I'm new here and (..)
Yes No Job Title This field is hidden when viewing the form Industry Primary Financial System -- Select One -- Deltek Epicor Infor JD Edwards Microsoft MRI Software NetSuite Oracle Other Sage SAP SYSPRO Viewpoint Financial System Version -- Select One -- 24SevenOffice A+ AARO AccountEdge Accounting CS Accountmate Acumatica Alere Anaplan Aptean Assist (..)
Jet Analytics is a robust Business Intelligence (BI) solution that complements Jet Reports with a datawarehouse and advanced analytics capabilities. It includes pre-built projects, cubes, and data models, as well as a suite of ready-to-run reports and dashboards. We designed Jet Analytics for operational efficiency.
Certent: Agile Disclosure Management for the Busy CFO Download Now: " * " indicates required fields This field is hidden when viewing the form Select Your Closest Time Zone -- Select One -- This field is hidden when viewing the form Platform * First Choice Second Choice Third Choice Use Case * -- Select One -- I'm a current user and updating (..)
Atlas for Dynamics 365 Download Now: " * " indicates required fields Hidden Select Your Closest Time Zone -- Select One -- Hidden Platform * First Choice Second Choice Third Choice Use Case * -- Select One -- I'm a current user and updating my application I'm a current user and interested in expanding usage I'm new here and interested in evaluating (..)
Hubble Best Practices: Descriptions, Drilldown, and Report Packs Watch Now " * " indicates required fields Hidden Select Your Closest Time Zone -- Select One -- Hidden Platform * First Choice Second Choice Third Choice Use Case * -- Select One -- I'm a current user and updating my application I'm a current user and interested in expanding usage (..)
Navigating Compliance and Security in Data Connectivity Download Now: " * " indicates required fields Hidden Select Your Closest Time Zone -- Select One -- Hidden Platform * First Choice Second Choice Third Choice Use Case * -- Select One -- I'm a current user and updating my application I'm a current user and interested in expanding usage (..)
Simplify Your Hybrid Cloud ERP Approach with Spreadsheet Server Download Now: " * " indicates required fields Hidden Select Your Closest Time Zone -- Select One -- Hidden Platform * First Choice Second Choice Third Choice Use Case * -- Select One -- I'm a current user and updating my application I'm a current user and interested in expanding (..)
Complex Tax Compliance With a Single Source of Truth Download Now: " * " indicates required fields Hidden Select Your Closest Time Zone -- Select One -- Hidden Platform * First Choice Second Choice Third Choice Use Case * -- Select One -- I'm a current user and updating my application I'm a current user and interested in expanding usage I'm (..)
The key components of a data pipeline are typically: Data Sources : The origin of the data, such as a relational database , datawarehouse, data lake , file, API, or other data store. This can include tasks such as data ingestion, cleansing, filtering, aggregation, or standardization.
Smoother Reporting With the Power of Your ERP and the Familiarity of Excel Download Now: " * " indicates required fields Hidden Select Your Closest Time Zone -- Select One -- Hidden Platform * First Choice Second Choice Third Choice Use Case * -- Select One -- I'm a current user and updating my application I'm a current user and interested (..)
Info-Tech Data Quadrant: Business Intelligence & Analytics Enterprise Download Now: " * " indicates required fields This field is hidden when viewing the form Select Your Closest Time Zone -- Select One -- This field is hidden when viewing the form Platform * First Choice Second Choice Third Choice Use Case * -- Select One -- I'm a current (..)
Bridging the Skills Gap: Empowering Your Team with Hubble Watch Now " * " indicates required fields This field is hidden when viewing the form Select Your Closest Time Zone -- Select One -- This field is hidden when viewing the form Platform * First Choice Second Choice Third Choice Use Case * -- Select One -- I'm a current user and updating (..)
This requires finance teams to manually move the relevant data into a tool that allows them to manipulate and present the data in an understandable way. This may involve loading data into a datawarehouse. In this scenario, producing reports becomes a time-intensive, demanding task.
Creating operational reports using Microsoft Power BI requires significant technical skills and investment in a datawarehouse to transform data into an optimal format for operational reporting, which loses the immediacy of the data and makes it more difficult to drill into transactional data to answer follow-up questions.
Mastering Pixel-Perfect Reporting with Logi Symphony Watch Now " * " indicates required fields Hidden Select Your Closest Time Zone -- Select One -- Hidden Platform * First Choice Second Choice Third Choice Use Case * -- Select One -- I'm a current user and updating my application I'm a current user and interested in expanding usage I'm new (..)
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content