This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon EMR on EC2 , Amazon EMR Serverless , Amazon EMR on Amazon EKS , Amazon EMR on AWS Outposts and AWS Glue all use the optimized runtimes. This is a further 32% increase from the optimizations shipped in Amazon EMR 7.1 The following table summarizes the metrics. Metric Amazon EMR 7.5 Metric Amazon EMR 7.5
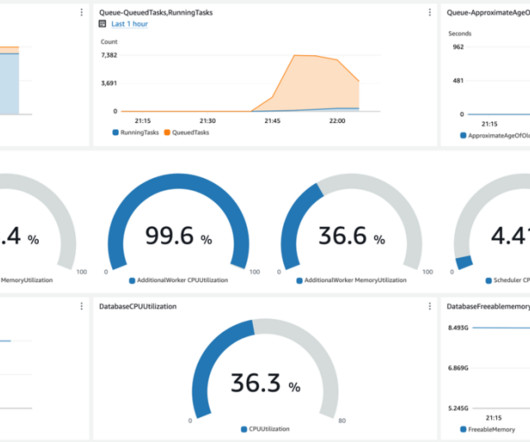
We have launched job worker metrics in Amazon CloudWatch for EMR Serverless. This feature allows you to monitor vCPUs, memory, ephemeral storage, and disk I/O allocation and usage metrics at an aggregate worker level for your Spark and Hive jobs. This post is part of a series about EMR Serverless observability.
Executive recruiters working in the Global 2000 will tell you that the “hot ask” of organizations seeking high-end IT leaders today is for “transformational leaders.” Operations is really, really hard, and really, really underappreciated, and really, really poorly understood, until it doesn’t work.”
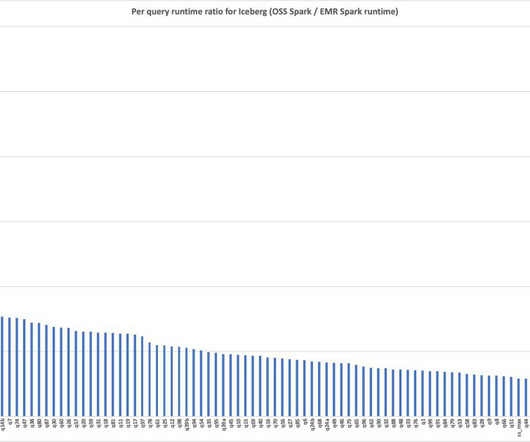
times faster with Amazon EMR runtime for Apache Spark , we detailed some of the optimizations, showing a runtime improvement of 4.5 However, many of the optimizations are geared towards DataSource V1, whereas Iceberg uses Spark DataSource V2. We have added eight new optimizations incrementally since the Amazon EMR 6.15
The current state of IT operations misses the mark on sustainability objectives, in part because IT has historically been evaluated on other metrics. As we size HPE GreenLake, we’re looking at workloads and optimizing hardware so you can see significant space, power, carbon emission, and equipment reduction.”.
The Amazon EMR runtime for Apache Spark is a performance-optimized runtime that is 100% API compatible with open source Apache Spark. Amazon EMR on EC2 , Amazon EMR Serverless , Amazon EMR on Amazon EKS , and Amazon EMR on AWS Outposts all use this optimized runtime, which is 4.5 The cost metric can provide us with additional insights.
The current state of IT operations misses the mark on sustainability objectives, in part because IT has historically been evaluated on other metrics. As we size HPE GreenLake, we’re looking at workloads and optimizing hardware so you can see significant space, power, carbon emission, and equipment reduction.”.
the weight given to Likes in our video recommendation algorithm) while $Y$ is a vector of outcome measures such as different metrics of user experience (e.g., Experiments, Parameters and Models At Youtube, the relationships between system parameters and metrics often seem simple — straight-line models sometimes fit our data well.
xlarge 8 vCPUs / 24 GB 4 vCPUs / 12 GB 40 tasks (default) Up to 2000 mw1.2xlarge 16 vCPUs / 48 GB 8 vCPUs / 24 GB 80 tasks (default) Up to 4000 With the introduction of these larger environments, your Amazon Aurora metadata database will now use larger, memory-optimized instances powered by AWS Graviton2.
Google Ads was launched in October 2000 and has gone through some significant changes and improvements in the past 17 years. If your keywords are not optimized for maximum performance, or have not been well considered, the likelihood is you will generate poor results. Keywords sit at the core of all PPC advertising campaigns.
The original 30 books of the ITIL were first condensed in 2000 (when ITIL V2 was launched) to seven books, each wrapped around a facet of IT management. ITIL 4, the latest iteration of the ITIL framework, maintains the original focus with a stronger emphasis on fostering an agile and flexible IT department. What’s in the ITIL?
McKinsey recently surveyed 2000 businesses and found that 83% of high-tech/media/telecom, 76% of banking, and more than 50% of consumer companies identified as continuous improvement organizations. There is good reason for these results.
This blog is intended to give an overview of the considerations you’ll want to make as you build your Redshift data warehouse to ensure you are getting the optimal performance. Think of it like something that houses the metrics used to power daily, weekly, or monthly business KPIs. roll-ups of many rows of data). Sort & Dist Keys.
In fact, in a 2019 edition of Industrial Management & Data Systems, a research team led by Yu Nie noted that prior to the year 2000, there were only six chief data officers in the world. The role is a relative newcomer to the boardroom. Clearly, data is becoming more important to organizations.
For example, with those open source licenses we can download their text, parse, then compare similarity metrics among them: In [12]: pairs = [?. ["mit", "asl"],?. ["asl", "bsd"],?. ["bsd", "mit"] ?]? ?for …. One common use case for natural language work is to compare texts. for a, b in pairs:?.
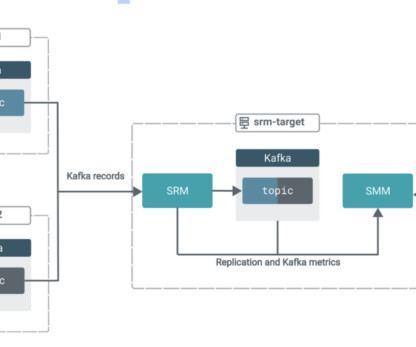
Businesses often need to aggregate topics because it is essential for organizing, simplifying, and optimizing the processing of streaming data. This property specifies the cluster that the SRM service role will gather replication metrics from (i.e. Notice that the tool will produce 2000 records. Set this to: 8. Let’s replicate.
Using table and column statistics, the coordinator produces an optimized distributed query plan – a relational operator tree – with parallelizable query fragments. The key metric for admission control is the query’s MEM_LIMIT : the admitted maximum per host memory consumption of the query.
There is no golden metric for everyone, we are all unique snowflakes! :). and tell you what are the best key performance indicators (metrics) for them. In the past I’ve shared a cluster of metrics that small, medium and large businesses can use as a springboard…. If you want to play along. Don’t read what I’ve chosen.
Instead of continuing to deploy their attention optimization algorithms for their users’ and suppliers’ benefit, the tech giants began to use them to favor themselves. From 2000 to 2011, the percentage of US adults using the internet had grown from about 60% to nearly 80%. But over time, something went very wrong.
Discuss approaches for optimizing the performance of deep reinforcement learning agents. The Optimal Policy. represents a particular, optimal policy (out of all the potential ? Thus, as a computational shortcut, we’ll describe the Q- learning approach for estimating what the optimal action a in a given situation might be.
Such decisions involve an actual hypothesis test on specific metrics (e.g. Often, an established product will have an overall evaluation criterion (OEC) that incorporates trade-offs among important metrics and between short- and long-term success. The metrics to measure the impact of the change might not yet be established.
Life insurance needs accurate data on consumer health, age and other metrics of risk. All assets need to be optimally leveraged for maximum business value while also being protected from misuse, whether there was malicious intent or not, and this needs to be the responsibility of whomever is responsible for that asset in the company.
With more features come more potential post hoc hypotheses about what is driving metrics of interest, and more opportunity for exploratory analysis. Looking at metrics of interest computed over subpopulations of large data sets, then trying to make sense of those differences, is an often recommended practice (even on this very blog).
A chief executive officer (CEO) key performance indicator (KPI) or metric is a relative performance measure that a CEO will use to make informed decisions. By monitoring financial, operational, and staffing metrics, a CEO is able to identify the strengths and weaknesses of a company and leverage these to their advantage.
Non-profit metrics quantify the organization’s many endeavours in extending its impact on society. How to choose the right non-profit metrics? There are hundreds of metrics to choose from, and if they are not vetted properly, the organization could end up with too few or too many KPIs. What are non-profit KPIs?
An accounting Key Performance Indicator (KPI) or metric is an explicitly defined and quantifiable measure that the accounting industry uses to gauge its overall long-term performance. Error Resolution Time – This accounting metric tracks the time it takes to correct an error when it is identified. What is an Accounting KPI? Learn More.
Inventory KPIs and metrics are crucial aspects of the reporting process. Why Inventory KPIs and Metrics Are Essential for Reporting? Tracking inventory KPIs and metrics allows businesses to identify areas in their business that need improvement and attention. You can run this metric over days, weeks, months, or years.
Non-profit metrics quantify the organization’s many endeavors in extending its impact on society. How to choose the right non-profit metrics? There are hundreds of metrics to choose from, and if they are not vetted properly, the organization could end up with too few or too many KPIs. What is a kpi?
Non-profit metrics quantify the organization’s many endeavours in extending its impact on society. How to choose the right non-profit metrics? There are hundreds of metrics to choose from, and if they are not vetted properly, the organization could end up with too few or too many KPIs. What are non-profit KPIs?
KPIs are a select few metrics that provide insight on the operation of all entities contributing to the supply chain. Metrics help supply chain management track its progress in achieving its goals and respond quickly if needed. Measurable: Is your metric quantifiable? That’s where KPI monitoring comes into play.
A Tax Key Performance Indicator (KPI) or metric is a clearly defined quantifiable measure that an organization, or business, uses to measure the success of its Tax Function over time. Since every organization has its own manner of operation, the KPIs or metrics used for tax will vary from one organization to another.
The constituents cannot hold their government responsible without having access to periodic reporting on key performance metrics. They indicate the expected level of performance by attaching a target to each metric. Cross-sectional metrics : Ensure that you have KPIs for every department within the organization.
An operational key performance indicator (KPI) or metric is a measure that a company uses to evaluate its performance. By monitoring operational metrics, a company is able to identify growth opportunities and build on its strengths. COO KPIs are metrics that the COO uses to gauge the performance of all departments within the company.
Data Exposure Risks Public AI models require training on external data, exposing sensitive dashboards, proprietary metrics, and client information to unknown entities. This partnership ensures that your analytics are not just connected but optimized for the best possible value. Dashboards need actionable insights, not guesswork.
If the operating theme for finance teams in 2024 was “automate workflows and optimize costs to drive value,” then the operating theme for 2025 is shaping up to be, “stay the course.” Add in continuing geopolitical instability, and it’s easy to see why operating plans for 2025 are unlikely to look significantly different from 2024 plans.
With its ability to integrate seamlessly with Oracle ERPs on-prem and in the cloud, Spreadsheet Server facilitates real-time data access and reporting, providing a single, unified view of critical business metrics. This transparency helps maintain trust and facilitates smoother transitions.
Teams will be focused on key performance metrics like return on assets (ROA), revenue growth rate, and gross profit margin. This shift underlines the escalating need for finance teams to optimize the use of existing assets and investments to maximize returns.
To assess how your analytics offerings impact your competitiveness and revenue opportunities, take these steps: Monitor Key Metrics: Track metrics such as customer churn rate, feature adoption, and customer lifetime value to understand the impact of your current analytics.
Financial modeling involves combining key accounting, finance, and business metrics to build an abstract representation, or model, of a company’s financial situation. Aside from budgeting and forecasting, the FP&A team is also tasked with decision-making support and special projects such as market research and process optimization.
As a result, end users can better view shared metrics (backed by accurate data), which ultimately drives performance. When treating a patient, a doctor may wish to study the patient’s vital metrics in comparison to those of their peer group. They can also create custom calculations and metrics, and build new data visualizations.
The constituents cannot hold their government responsible without having access to periodic reporting on key performance metrics. They indicate the expected level of performance by attaching a target to each metric. Cross-sectional metrics : Ensure that you have KPIs for every department within the organization.
The constituents cannot hold their government responsible without having access to periodic reporting on key performance metrics. They indicate the expected level of performance by attaching a target to each metric. Cross-sectional metrics : Ensure that you have KPIs for every department within the organization.
Organizations that use ERP and EPM software are often more successful at supply chain management, as these solutions provide integrated platforms for data management, process automation, demand planning, supply chain optimization, performance monitoring, and collaboration. How Does Supply Chain Management Work?
Product managers rely on these analytics platforms to track metrics, analyze key performance indicators (KPIs), and visualize the end user’s experience with the product. With this information, they can identify areas for improvement, optimize the user experience, and ultimately drive greater success for the product. Who benefits?
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content