This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Impala Optimizations for Small Queries. We’ll discuss the various phases Impala takes a query through and how small query optimizations are incorporated into the design of each phase. Query optimization in databases is a long standing area of research, with much emphasis on finding near optimal query plans.
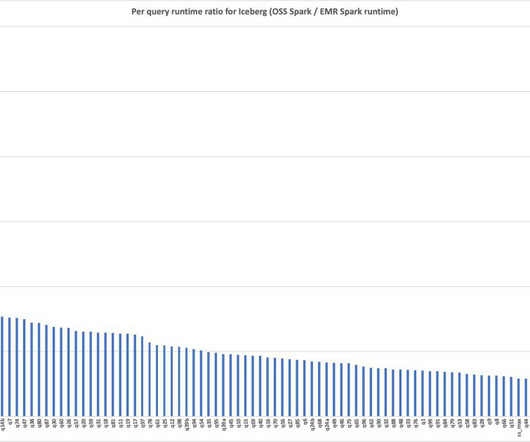
Amazon EMR on EC2 , Amazon EMR Serverless , Amazon EMR on Amazon EKS , Amazon EMR on AWS Outposts and AWS Glue all use the optimized runtimes. This is a further 32% increase from the optimizations shipped in Amazon EMR 7.1 In this post, we demonstrate the performance benefits of using the Amazon EMR 7.5 with Iceberg 1.6.1 q14b-v2.13,q15-v2.13,q16-v2.13,
Knowledge graphs enable content, data and knowledge-centric enterprises to improve repeated monetization of their assets by optimizing their reuse and repurposing as well as creating new products such as books, apps, reports, journal articles, content, and data feeds. The post What Does 2000 Year Old Concrete Have to Do with Knowledge Graphs?
With Amazon Q, you can spend less time worrying about the nuances of SQL syntax and optimizations, allowing you to concentrate your efforts on extracting invaluable business insights from your data. Refer to Easy analytics and cost-optimization with Amazon Redshift Serverless to get started. For this post, we use Redshift Serverless.
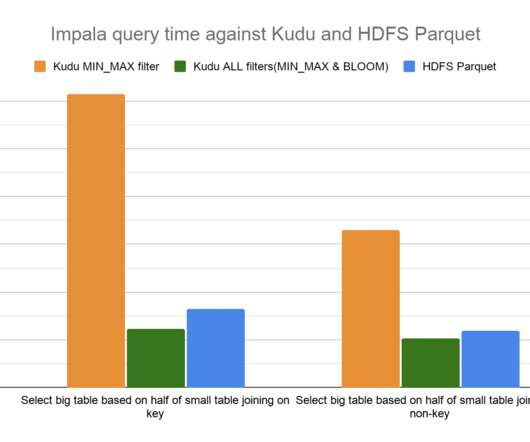
Pushing down column predicate filters to Kudu allows for optimized execution by skipping reading column values for filtered out rows and reducing network IO between a client, like the distributed query engine Apache Impala, and Kudu. One of the ways Apache Kudu achieves this is by supporting column predicates with scanners. Join Queries.
For example, underutilization of vCPUs or memory can reveal resource wastage, allowing you to optimize worker sizes to achieve potential cost savings. Optimize resource utilization When running Spark jobs, you often start with the default configurations. The second job took 4 minutes, 54 seconds.
For twenty years, from approximately 1980 to 2000, the primary objective of IT strategy was to solicit funding. years) is becoming the optimal temporal “chunk” inside which to do career and strategic planning. The most important questions about the future are who will we be and when will we be.
Executive recruiters working in the Global 2000 will tell you that the “hot ask” of organizations seeking high-end IT leaders today is for “transformational leaders.” Operations is really, really hard, and really, really underappreciated, and really, really poorly understood, until it doesn’t work.”
If the relationship of $X$ to $Y$ can be approximated as quadratic (or any polynomial), the objective and constraints as linear in $Y$, then there is a way to express the optimization as a quadratically constrained quadratic program (QCQP). However, joint optimization is possible by increasing both $x_1$ and $x_2$ at the same time.
More companies are using data analytics to optimize their business models in creative ways. Some of the ways that data analytics can help companies improve their logistics include: Optimizing transportation routes Improving shipment schedules Reducing errors with delivery and pickup. Optimized inventory management.
Image SEO is optimizing the images on your website for search engines. Optimize Image File Sizes Improperly sized images can greatly slow down the loading time of a webpage. Since image SEO and page speed are closely related, it’s important to compress images properly to optimize them for search engines. What Is Image SEO?
Queries containing joins, filters, projections, group-by, or aggregations without group-by can be transparently rewritten by the Hive optimizer to use one or more eligible materialized views. Materialized views can be partitioned on one or more columns. This can potentially lead to orders of magnitude improvement in performance.
By 2025, IDC research shows, 90% of the Global 2000 will bring their sustainability mandates to the IT agenda, insisting on use of reusable materials in hardware supply chains, carbon neutrality targets for IT facilities, and lower energy use as prerequisites for doing business.
The Broadcom Expert Advantage Partner Program reflects the resulting commitment to simplify what is needed to create an optimal VMware Cloud Foundation cloud environment at scale, regardless of whether an organization is just embarking on its cloud journey or perfecting a sophisticated cloud environment.
The AI delivers suggestions of the best draft picks and bans to optimize win chances, and during the draft, it visualizes the predictions and provides the current winning probability after each pick and ban. They built the solution on SAP Business Technology Platform (SAP BTP) and store 1.6 TB of game data from past games in SAP HANA cloud.
By 2025, IDC expects Global 2000 companies to devote more than 40% of their core IT budgets to AI-related activities , with worldwide AI spending predicted to exceed $500 billion by 2027. To do so, we need to first ask ourselves three key questions: Question #1: How will we use AI to meet our specific business objectives?
The Amazon EMR runtime for Apache Spark is a performance-optimized runtime that is 100% API compatible with open source Apache Spark. Amazon EMR on EC2 , Amazon EMR Serverless , Amazon EMR on Amazon EKS , and Amazon EMR on AWS Outposts all use this optimized runtime, which is 4.5 times faster than Apache Spark 3.5.1 and EMR 7.1.
times faster with Amazon EMR runtime for Apache Spark , we detailed some of the optimizations, showing a runtime improvement of 4.5 However, many of the optimizations are geared towards DataSource V1, whereas Iceberg uses Spark DataSource V2. We have added eight new optimizations incrementally since the Amazon EMR 6.15
By 2025, IDC research shows, 90% of the Global 2000 will bring their sustainability mandates to the IT agenda, insisting on use of reusable materials in hardware supply chains, carbon neutrality targets for IT facilities, and lower energy use as prerequisites for doing business.
Google Ads was launched in October 2000 and has gone through some significant changes and improvements in the past 17 years. If your keywords are not optimized for maximum performance, or have not been well considered, the likelihood is you will generate poor results. Keywords sit at the core of all PPC advertising campaigns.
It is no surprise to CIO.comreaders that IT/digital efficacy is not optimally measured. It is perplexing and troubling that IT/digital communication — in most enterprises — is essentially unmeasured. Communication should not be an afterthought. Communication professionals suggest that before you start a project, you write the press release.
As an example, multinational customers use Longview’s Operational Transfer Pricing (OTP) solution to perform analytics, run scenario analyses, and then build, execute, and manage intercompany transactions and optimize the tax impact across operations in different tax jurisdictions. About Longview.
We are focused on unpicking them, really analyzing them to understand what they tell us about Games optimization.”. In fact, the IOC is currently undertaking a series of workshops in LA to really understand the different data partnerships that it needs to build in order to optimize the opportunities when LA hosts in 2028. “We’re
It utilizes Bayesian optimization for discovering data augmentation strategies tailored to your image dataset. To address this problem, Google published AutoAugment last year, which discovers optimized augmentations for the given dataset using reinforcement learning. DeepAugment is an AutoML tool focusing on data augmentation.
But Donagh Herlihy , the company’s chief digital and information officer, has a corporate-level solution to help each individual store determine “the sweet spot of pricing” to optimize profitability for that restaurant. For Herlihy, identifying ways to drive revenue growth is all in a day’s work for modern tech execs.
The company, listed on both the National Stock Exchange and the Bombay Stock Exchange, operates three amusement parks in Kochi, Bengaluru, and Hyderabad that were set up in 2000, 2005, and 2016, respectively, and plans to open two more amusement parks in the near future, in Chennai and Bhubaneswar. at a crossroads.
When they wrote computer programs in the 1960s, they should have realized that using only two digits to signify the year had the potential to cause havoc when we reached the year 2000! Many systems charge on a usage or storage basis, making optimizing what you transfer a move that not only saves migration time but makes good financial sense.)
NAME=Customer Name 2000,MKTSEGMENT=Market Segment 9},source=Struct{version=1.9.5.Final,connector=mysql,name=salesdb-server,ts_ms=1678099992174,snapshot=last,db=salesdb,table=CUSTOMER,server_id=0,file=binlog.000001,pos=43298383,row=0},op=r,ts_ms=1678099992174} NAME=Customer Name 2000,MKTSEGMENT=Market Segment 9},after=Struct{CUST_ID=2000.0,NAME=Customer
However, based on the 2000+ enterprise customers that Cloudera works with, more than half the data they need to source from is born outside the cloud (on-prem, edge, etc.) In the modern data stack, there is a diverse set of destinations where data needs to be delivered. This presents a unique set of challenges.
xlarge 8 vCPUs / 24 GB 4 vCPUs / 12 GB 40 tasks (default) Up to 2000 mw1.2xlarge 16 vCPUs / 48 GB 8 vCPUs / 24 GB 80 tasks (default) Up to 4000 With the introduction of these larger environments, your Amazon Aurora metadata database will now use larger, memory-optimized instances powered by AWS Graviton2.
Over 2000 customers and partners joined us in this live webinar featuring a first-look at our upcoming cloud-native CDP services. Enterprises can auto-scale and optimize to meet the demands of workloads. Cloudera shared a comprehensive overview and demonstration of the all-new Cloudera Data Platform (CDP).
On the other hand, the development rates in countries like the USA and Canada can be as high as $150-$2000 per hour. Moreover, choosing Russian programmers is the most optimal option for businesses working on a limited budget. This makes outsourcing to a development agency the most optimum option for digital platform development.
McKinsey recently surveyed 2000 businesses and found that 83% of high-tech/media/telecom, 76% of banking, and more than 50% of consumer companies identified as continuous improvement organizations. There is good reason for these results.
They are one of the few construction groups certified under ISO 9001:2000 quality management system, having a turnover of above USD 225 Mn in the fiscal year 2007-08. Client has to its credit many prestigious projects in the Industrial, Power, Institutional & Infrastructure sectors across India. Download the Case study.
This performance-optimized runtime offered by Amazon EMR makes your Spark jobs run fast and cost-effectively. In response to this need, starting from EMR 6.10, we have introduced a new feature that lets you use the optimized EMR runtime while submitting and managing Spark jobs through either Spark Operator or spark-submit.
However, based on the 2000+ enterprise customers that Cloudera works with, more than half the data they need to source from is born outside the cloud (on-prem, edge, etc.) In the modern data stack, there is a diverse set of destinations where data needs to be delivered. This presents a unique set of challenges.
And by late 2024, 70% of the Global 2000 will focus on reducing the process time between events and decision-making to gain a competitive advantage. QAD recently announced the launch of its Industrial Transformation Platform, an initiative aimed at optimizing people, processes and systems in manufacturing and supply chain scenarios.
The original 30 books of the ITIL were first condensed in 2000 (when ITIL V2 was launched) to seven books, each wrapped around a facet of IT management. ITIL 4, the latest iteration of the ITIL framework, maintains the original focus with a stronger emphasis on fostering an agile and flexible IT department. What’s in the ITIL?
Ontotext was founded in 2000 with the Semantic Web in its genes and we had the chance to be part of the community of its pioneers. Taking a closer look at these applications, we see two main perspectives from which the Web is becoming increasingly semantic. Weaving the Semantic Web with Semantic Annotations and Linked Open Data.
With a goal to optimize end-to-end processes and accelerate the organization’s digital journey, they looked for more efficient ways to execute all the manual and time-consuming financial forecasting process across their decentralized R&D business units. Trusted by customers.
With over 2000 products and a channel-focused Supply Chain planning approach, our Client wanted accurate Supply Chain Forecast for optimal product-availability within 8-week lead-times. In CPG, which is highly promotion driven, competitive and seasonal, this could make or break a business.
Businesses often need to aggregate topics because it is essential for organizing, simplifying, and optimizing the processing of streaming data. Notice that the tool will produce 2000 records. After the producer is finished with creating the topic and producing the 2000 records, the topic is immediately replicated.
This blog is intended to give an overview of the considerations you’ll want to make as you build your Redshift data warehouse to ensure you are getting the optimal performance. Amazon describes the dense storage nodes (DS2) as optimized for large data workloads and use hard disk drives (HDD) for storage. Sort & Dist Keys.
We hear about digital efficiency, digital workplace, and digital optimization. After a few years, by the early 2000’s – these channels were no longer ‘new’ media. Today, everything is “digital”. ERP is now part of a digital platform. Digital has become everything to everyone everywhere – or so it would sometimes seem.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content