This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
TL;DR LLMs and other GenAI models can reproduce significant chunks of training data. Researchers are finding more and more ways to extract training data from ChatGPT and other models. And the space is moving quickly: SORA , OpenAI’s text-to-video model, is yet to be released and has already taken the world by storm.
Still, CIOs should not be too quick to consign the technologies and techniques touted during the honeymoon period (circa 2005-2015) of the Big Data Era to the dust bin of history. But many execs suffer from “data defeatism,” erroneously thinking that data value is dependent on having degrees in math, statistics, or machine learning.
The stages of burnout Developing over time, burnout builds in distinct stages that lead employees down a path of low motivation, cynicism, and eventually depersonalization, according to Yerbo’s The State of Burnout in Tech report, which points to 2005 research by Salanova and Schaufeli on the subject.
Rokita has been with Edmunds for more than 18 years, starting as executive director of technology in 2005. His role now encompasses responsibility for data engineering, analytics development, and the vehicle inventory and statistics & pricing teams. The data warehouse is about past data, and models are about future data.
KUEHNEL, and ALI NASIRI AMINI In this post, we give a brief introduction to random effects models, and discuss some of their uses. Through simulation we illustrate issues with model fitting techniques that depend on matrix factorization. Random effects models are a useful tool for both exploratory analyses and prediction problems.
SCOTT Time series data are everywhere, but time series modeling is a fairly specialized area within statistics and data science. This post describes the bsts software package, which makes it easy to fit some fairly sophisticated time series models with just a few lines of R code. by STEVEN L. Forecasting (e.g.
Or when Tableau and Qlik’s serious entry into the market circa 2004-2005 set in motion a seismic market shift from IT to the business user creating the wave of what was to become the modern BI disruption. After five minutes of seeing these products back then, I just knew they would change everything! Answer: Better than every other vendor?
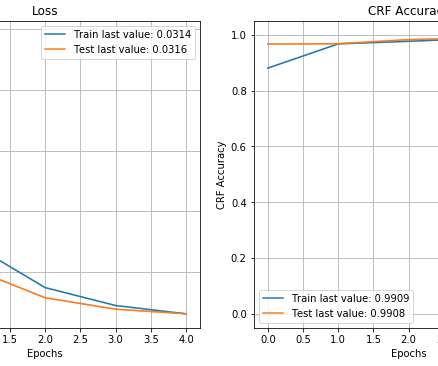
In this blog post we present the Named Entity Recognition problem and show how a BiLSTM-CRF model can be fitted using a freely available annotated corpus and Keras. The model achieves relatively high accuracy and all data and code is freely available in the article. How to build a statistical Named Entity Recognition (NER) model.
how “the business executives who are seeing the value of data science and being model-informed, they are the ones who are doubling down on their bets now, and they’re investing a lot more money.” He was saying this doesn’t belong just in statistics. Key highlights from the session include. Transcript. Tukey did this paper.
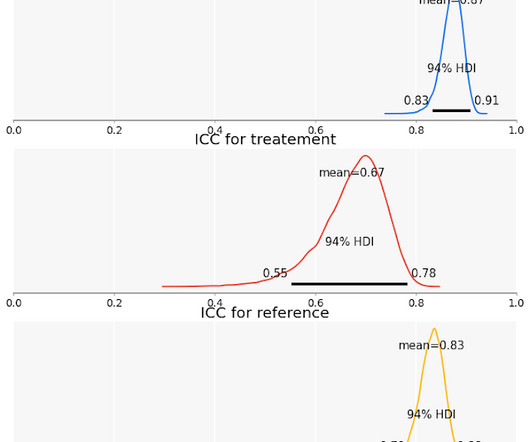
Editor's note : The relationship between reliability and validity are somewhat analogous to that between the notions of statistical uncertainty and representational uncertainty introduced in an earlier post. Throughout, we’ll refer to our model-derived measurement of inter-rater reliability as the Intraclass Correlation Coefficient (ICC).
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content