

Unlock the power of optimization in Amazon Redshift Serverless
AWS Big Data
MARCH 10, 2025
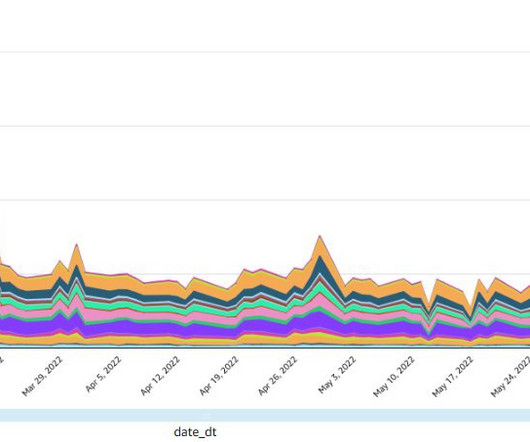
Although traditional scaling primarily responds to query queue times, the new AI-driven scaling and optimization feature offers a more sophisticated approach by considering multiple factors including query complexity and data volume. He has been helping companies with Data Warehouse solutions since 2007.


















Let's personalize your content