This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
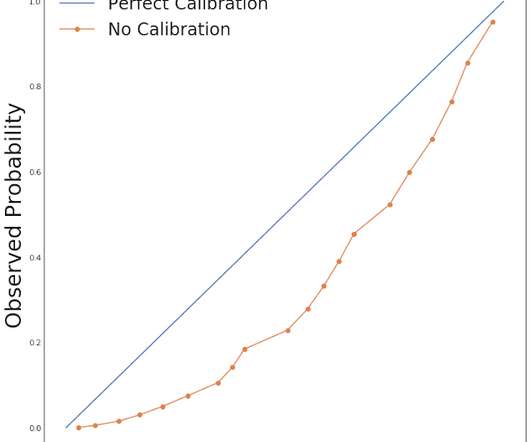
by LEE RICHARDSON & TAYLOR POSPISIL Calibrated models make probabilistic predictions that match real world probabilities. To explain, let’s borrow a quote from Nate Silver’s The Signal and the Noise : One of the most important tests of a forecast — I would argue that it is the single most important one — is called calibration.
Sometimes, we escape the clutches of this sub optimal existence and do pick good metrics or engage in simple A/B testing. Let's listen in as Alistair discusses the lean analytics model… The Lean Analytics Cycle is a simple, four-step process that shows you how to improve a part of your business. Testing out a new feature.
Key To Your Digital Success: Web Analytics Measurement Model. Web Data Quality: A 6 Step Process To Evolve Your Mental Model. The Awesome Power of Visualization 2 -> Death and Taxes 2007. Five Reasons And Awesome Testing Ideas. Lab Usability Testing: What, Why, How Much. Experimentation and Testing: A Primer.
Recall from my previous blog post that all financial models are at the mercy of the Trinity of Errors , namely: errors in model specifications, errors in model parameter estimates, and errors resulting from the failure of a model to adapt to structural changes in its environment. For example, if a stock has a beta of 1.4
This library was developed in 2007 as part of a Google project. There are two essential classifiers for developing machine learning applications with this library: a supervised learning model known as an SVM and a Random Forest (RF). Some of the Premier benefits include: Regression modeling. Advanced probability modeling.
How do you get over the frustration of having done attribution modeling and realizing that it is not even remotely the solution to your challenge of using multiple media channels? Then they isolated regions of the country (by city, zip, state, dma pick your fave) into test and control regions. Good lord I love this stuff!
The benefits of data analytics in accounts receivable was first explored by a study from New York University back in 2007. Companies can use their predictive analytics models to decide how to resolve issues with tardiness. You should outline these options beforehand and test them carefully with your big data software after.
by HENNING HOHNHOLD, DEIRDRE O'BRIEN, and DIANE TANG In this post we discuss the challenges in measuring and modeling the long-term effect of ads on user behavior. We describe experiment designs which have proven effective for us and discuss the subtleties of trying to generalize the results via modeling.
One of the most common ways of fitting time series models is to use either autoregressive (AR), moving average (MA) or both (ARMA). These models are well represented in R and are fairly easy to work with. AR models can be thought of as linear regressions of the current value of the time series against previous values.
Reyes has been with AES since 2007, working his way up the organization ladder from an SAP integration lead in Buenos Aires to application security manager, IT project director, and director of digital transformation today. If it doesn’t work, and we don’t understand why, then, we pivot to a different model and a hypothesis.
The DevOps movement started to come together sometime between 2007 and 2008. This is when IT operations and software development communities started to talk about problems in the software industry, specifically around the traditional software development model. It’s also shaping the way BI and Analytics are deployed.
Another reason to use ramp-up is to test if a website's infrastructure can handle deploying a new arm to all of its users. The website wants to make sure they have the infrastructure to handle the feature while testing if engagement increases enough to justify the infrastructure. We offer two examples where this may be the case.
Consider an example in which our first data source says that Microsoft invested $240 million in Facebook and the second – that on October 24, 2007 Microsoft invested in Facebook. But, before we can have any larger scale implementation of these rules, we have to test their validity. However, this is not always so straightforward.
The best option is to hire a statistician with experience in data modeling and forecasting. Brian Krick: Best way to measure and communicate "available demand" from available channels (social, search, display) for forecast modeling. Post Testing: Visits 30k. Please see the advice above. the web is so insanely fluid, 2.
It was introduced in 1980 but open-sourced in 2007, which created its widespread use. DataRobot’s AutoML uses different feature engineering techniques and a variety of machine learning algorithms to identify the best model for multilabel classification. The best model for this dataset is a Keras-based neural network.
A naïve way to solve this problem would be to compare the proportion of buyers between the exposed and unexposed groups, using a simple test for equality of means. The choice of space $cal F$ (sometimes called the model ) and loss function $L$ explicitly defines the estimation problem. the curse of dimensionality).
I spend 70% of my time in the US and for those discussions I'm primary looking at speed (connection above), mobile penetration (yes, 2007 was the year of mobile!), Think of it as attribution modeling. :). and mobile intent to purchase (I love this data).
With that said, recent advances in deep learning methods have allowed models to improve to a point that is quickly approaching human precision on this difficult task. The first step in developing any model is gathering a suitable source of training data, and sentiment analysis is no exception. Sentiment analysis models.
Similarly, we could test the effectiveness of a search ad compared to showing only organic search results. Structure of a geo experiment A typical geo experiment consists of two distinct time periods: pretest and test. After the test period finishes, the campaigns in the treatment group are reset to their original configurations.
Experiments, Parameters and Models At Youtube, the relationships between system parameters and metrics often seem simple — straight-line models sometimes fit our data well. That is true generally, not just in these experiments — spreading measurements out is generally better, if the straight-line model is a priori correct.
Amazon strategically went with the pricing model of ‘on-demand’, allowing developers to pay only as-per their computational needs. 2007: Amazon launches SimpleDB, a non-relational (NoSQL) database that allows businesses to cheaply process vast amounts of data with minimal effort. EC2 was a more evolved version of a Virtual Machine.
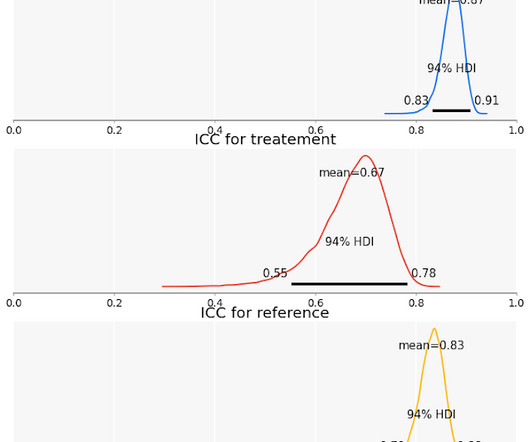
Parametric measurements Thus far, we’ve been discussing non-parametric approaches to measuring reliability and validity, but in this section we’ll present an approach to get the same measurements from parametric models. Each item receives multiple labels, and each person labeling this data assesses multiple items.
This is a summary of Bell and Koren’s 2007 Scalable Collaborative Filtering with Jointly Derived Neighborhood Interpolation Weights paper. Another way of thinking about this is that we are simply building a regression model. I’m now (very slowly) trying to clean up my notes and put them online. Bob likes Kate Winslet).
since 2007. Training a single AI model emits as much as five average cars over their lifetimes. By aligning your infrastructure and operations with ESG frameworks, we identify key opportunities to drive innovation, enhance operational efficiency and gain a competitive edge. Research indicates that the circular economy presents a $4.5
To make sure the reliability is high, there are various techniques to perform – the first of them being the control tests, which should have similar results when reproducing an experiment in similar conditions. In 2007, Colgate was ordered by the Advertising Standards Authority (ASA) of the U.K. 3) Misleading statistics in advertising.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content