This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Also, we designed our test environment without setting the Amazon Redshift Serverless workgroup max capacity parametera key configuration that controls the maximum RPUs available to your data warehouse. By removing this limit, we could clearly showcase how different configurations affect scaling behavior in our test endpoints.
Sometimes, we escape the clutches of this sub optimal existence and do pick good metrics or engage in simple A/B testing. Testing out a new feature. Identify, hypothesize, test, react. But at the same time, they had to have a real test of an actual feature. You don’t need a beautiful beast to go out and test.
The benefits of data analytics in accounts receivable was first explored by a study from New York University back in 2007. You should outline these options beforehand and test them carefully with your big data software after. Fortunately, new advances in data technology have made accounts receivable management easier than ever.
Then they isolated regions of the country (by city, zip, state, dma pick your fave) into test and control regions. People in the test regions will participate in our hypothesis testing. So for variation #3, no catalogs or email were sent to the customers in the test group. The nice thing is that you can also test that!
This library was developed in 2007 as part of a Google project. Scikit-learn contains a function that allows to separate the training data from the test data, this is done automatically and shuffles the data randomly that support our methodology. One version is for training (train), and another for testing (test).
class(attClose) [1] "xts" "zoo" > head(attClose) T.Close 2007-01-03 34.95 2007-01-04 34.50 2007-01-05 33.96 2007-01-08 33.81 2007-01-09 33.94 2007-01-10 34.03. Most of this, such as the statistics on residuals, tests, AIC and BIC are diagnostic measures on the quality of the fit. > attGarch.
Reyes has been with AES since 2007, working his way up the organization ladder from an SAP integration lead in Buenos Aires to application security manager, IT project director, and director of digital transformation today. If it doesn’t work, and we don’t understand why, then, we pivot to a different model and a hypothesis.
The best business relationships have a certain synergy, and that synergy is especially important for sustaining long-term business relationships that stand the test of time. They want the data transparency necessary to calibrate those solutions, test their effectiveness, and scale. Expanding Offerings to Grow Business Partnerships.
The DevOps movement started to come together sometime between 2007 and 2008. With DevOps aiming for greater efficiencies between software development and IT teams, it was clear that automated processes needed to be put in place to build, test, and release software faster and more reliably. Automation & Speed.
Our products are sometimes tested for a year before being launched in the field. For instance, some software developers still use Windows 2007 servers, which are completely end-of-life, and don’t have the necessary security patches. Much of the digitization in the manufacturing segment is related to the execution systems.
The 2007/2008 financial crisis unveiled the monstrous risk of mis-reporting data. Nicola Askham raised the concept of a “Daily Mail Test”. In its wake, many data leaders have made ethical standards core to their operations. However, for others, this can lead to impulse spending and they may not want to receive these. In Conclusion.
A/B testing is used widely in information technology companies to guide product development and improvements. For questions as disparate as website design and UI, prediction algorithms, or user flows within apps, live traffic tests help developers understand what works well for users and the business, and what doesn’t.
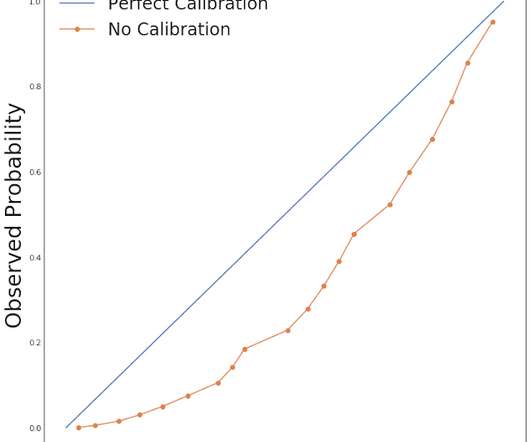
To explain, let’s borrow a quote from Nate Silver’s The Signal and the Noise : One of the most important tests of a forecast — I would argue that it is the single most important one — is called calibration. One useful property of these predictions is calibration. How should practitioners integrate calibration into their workflow?
DevOps first came about in 2007-2008 to fix problems in the software industry and bring with it continuous improvement and greater efficiencies. You should have at least one KPI for every part of your product cycle; planning, development, testing, deployment, release, and monitoring. But is that really true? Getting Started.
Consider an example in which our first data source says that Microsoft invested $240 million in Facebook and the second – that on October 24, 2007 Microsoft invested in Facebook. But, before we can have any larger scale implementation of these rules, we have to test their validity. However, this is not always so straightforward.
2 2007 7453215. To build an open lakehouse on your own try Cloudera Data Warehouse (CDW), Cloudera Data Engineering (CDE), and Cloudera Machine Learning (CML) by signing up for a 60-day trial , or test drive CDP. 1 2008 7009728. 3 2006 7141922. 4 2005 7140596. 5 2004 7129270. 6 2003 6488540. 7 2002 5271359. 8 2001 5967780.
Another reason to use ramp-up is to test if a website's infrastructure can handle deploying a new arm to all of its users. The website wants to make sure they have the infrastructure to handle the feature while testing if engagement increases enough to justify the infrastructure. We offer two examples where this may be the case.
It was introduced in 1980 but open-sourced in 2007, which created its widespread use. The competition metric is the maximum Tanimoto score of the top five recommendations to the ground truth averaged over the test dataset. SENTENCE represents smells as the target or labels that need to be predicted.
A naïve way to solve this problem would be to compare the proportion of buyers between the exposed and unexposed groups, using a simple test for equality of means. 2007): Propose a finite collection $mathcal L={hat e_k:k=1,ldots,K}$ of estimation algorithms. This fact is well documented by Kang & Schafer (2007).
The IMDB Movie Reviews Dataset provides 50,000 highly polarized movie reviews with a 50-50 train/test split. Whenever you test a machine learning method, it’s helpful to have a baseline method and accuracy level against which to measure improvements. It provides 1.6 Sentiment analysis, a baseline method.
Similarly, we could test the effectiveness of a search ad compared to showing only organic search results. Structure of a geo experiment A typical geo experiment consists of two distinct time periods: pretest and test. After the test period finishes, the campaigns in the treatment group are reset to their original configurations.
2007: Amazon launches SimpleDB, a non-relational (NoSQL) database that allows businesses to cheaply process vast amounts of data with minimal effort. AWS rolls out SageMaker, designed to build, train, test and deploy machine learning (ML) models. This gap sealed the domination of AWS in the market. The rest is history.
Multiparameter experiments, however, generate richer data than standard A/B tests, and automated t-tests alone are insufficient to analyze them well. We use PrePost in most of our A/B tests, so we have pre-experiment metric measurements readily available that we can use as covariates in our models. Springer New York, 2007. [8]
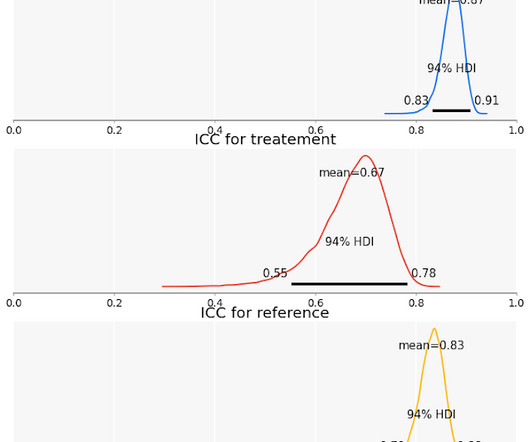
We use the diagnostic test results of our regression model to support the reasons why CIs should not be used in financial data analyses. The diagnostic tests computed by Statsmodels in Figure 3 show us that the equity market has wrecked the key assumptions of our MM. A significant vote of no confidence in confidence intervals.
The Awesome Power of Visualization 2 -> Death and Taxes 2007. Five Reasons And Awesome Testing Ideas. Lab Usability Testing: What, Why, How Much. Build A Great Web Experimentation & Testing Program. Experimentation and Testing: A Primer. Interviewing Tip: Stress Test Critical Thinking. Got Surveys?
I spend 70% of my time in the US and for those discussions I'm primary looking at speed (connection above), mobile penetration (yes, 2007 was the year of mobile!), Before you start influencing someone about the power of the web, it is nice to have a handy dandy chart to show that the web is material.
Strategic "how can we" questions: Simon: How to "sell" GWO testing (+Analytics) to Managers, very limited time/budget/staffing (btw, we already use Analytics and Adwords, but GWO is proving harder to get prioritised and understood, maybe worry of complexity). Post Testing: Visits 30k. Present this: Today: Visits 30k.
This is a summary of Bell and Koren’s 2007 Scalable Collaborative Filtering with Jointly Derived Neighborhood Interpolation Weights paper. I’m now (very slowly) trying to clean up my notes and put them online. Eventually, I hope to have a more integrated tutorial, but here’s a rough draft for now.).
While it may be a little abstract, this concept forms a key piece of Classical Test Theory (CTT) , a foundation of psychometrics. 2007): 77-89) Computing Krippendorff's Alpha-Reliability (Krippendorff, 2011) Cross-replication Reliability - An Empirical Approach to Interpreting Inter-rater Reliability (Wong et al.,
To make sure the reliability is high, there are various techniques to perform – the first of them being the control tests, which should have similar results when reproducing an experiment in similar conditions. In 2007, Colgate was ordered by the Advertising Standards Authority (ASA) of the U.K. 3) Misleading statistics in advertising.
since 2007. The CAF’s purpose is to test, challenge and support the art and science of Business Technology Architecture and its evolution over time as well as grow the influence and leadership of chief architects both inside and outside the profession. Is your IT sustainable?
Allowing CIOs to be political appointees opens the job to people who dont understand US laws governing federal IT systems and to those who dont have IT backgrounds, says John Weiler, CEO and CIO of the IT Acquisition Advisory Council, an organization created by Congress in 2007 to advise the US government on IT spending.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content