This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
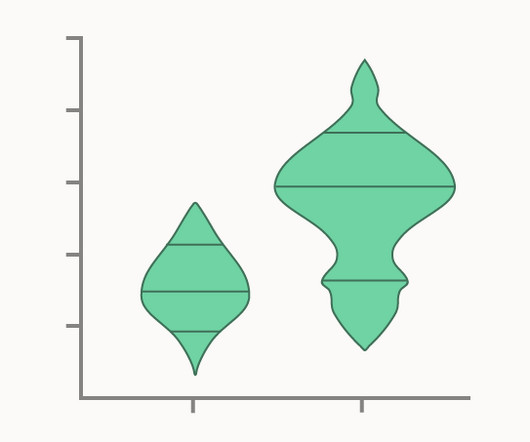
Box-Percentile Plots display the same summary statistics as regular Box Plots (median, quartiles, minimum, and maximum), but instead use line markers on a density/distribution shape to indicate their location. i17 Box-percentile plots of height-for-age (HAZ) by country; 2009-10. The Box-Percentile Plot, Warren W. Esty and Jeffrey D.
Based on figures from Statista , the volume of data breaches increased from 2005 to 2008, then dropped in 2009 and rose again in 2010 until it dropped again in 2011. In 2009 for example, data breaches dropped to 498 million (from 656 million in 2008) but the number of records exposed increased sharply to 222.5 million (from 35.7
On April 15, 2021, my book Now You See It (2009) will become available in its second edition with the revised subtitle An Introduction to Visual Data Sensemaking. I wrote Signal in 2015 to complement Now You See It by covering more advanced data sensemaking techniques, including Statistical Process Control.
In fact, according to the UNESCO Institute for Statistics , “16 million girls will never set foot in a classroom – and women account for two-thirds of the 750 million adults without basic literacy skills.”. Despite progress in recent years, UNESCO says that more girls than boys remain out of school. Making Women and Girls a Priority.
eBay's green line is very close the performance of the category (and you'll see that often at peaks in the shopping category queries, eBay actually does worse starting holiday season 2009). The tussle between Wal-Mart and Target is interesting. Amazon is an interesting example.
This is an example of Simpon’s paradox , a statistical phenomenon in which a trend that is present when data is put into groups reverses or disappears when the data is combined. It’s time to introduce a new statistical term. In 2009, researchers suggested that Simpson’s paradox may occur more often than commonly thought.
When I started my PhD in 2009, the plan was to work on sentiment analysis of opinion polls. I learned about Bayesian statistics and conjugate priors. What can one do to remain relevant in such an environment? Read this post to find out. Highlights from my past. Moving forward in my PhD, I got into topic modelling.
Ideally you'll measure the number prior to your branding campaign, say Feb 2009, and then you'll measure it again during your campaign, March 2009. It shows which terms (hence brands, sites, properties) have risen the by the most statistically significant amounts. Notice the competitive trends?
” The Information Technology Amendment Act of 2009 designated CERT-IN as the national agency to perform functions for cyber security, including the collection, analysis and dissemination of information on cyber incidents, as well as taking emergency measures to handle incidents and coordinating cyber incident response activities.
SCOTT Time series data are everywhere, but time series modeling is a fairly specialized area within statistics and data science. They may contain parameters in the statistical sense, but often they simply contain strategically placed 0's and 1's indicating which bits of $alpha_t$ are relevant for a particular computation. by STEVEN L.
The Decision Model (TDM) is a proprietary approach to representing business logic established by Barbara von Halle and Larry Goldberg in 2009 and documented in their book The Decision Model [1].
For example, with Alexa , you can report on traffic statistics (such as rank and page views), upstream (where your traffic comes from) and downstream (where people go after visiting your site) statistics, and key-words driving traffic to a site. You'll find other reports in the Resource Center.
You know the markets shake and the accompanying Swine Flu epidemic of 2015 and 2016, the Japanese tsunami and the Thailand floods in 2011 that shook up the high-tech value chain quite a bit, the great financial crisis and the accompanying H1N1 outbreak in 2008-2009, MERS and SARS before that in 2003.
Integrity of statistical estimates based on Data. Having spent 18 years working in various parts of the Insurance industry, statistical estimates being part of the standard set of metrics is pretty familiar to me [7]. The thing with statistical estimates is that they are never a single figure but a range. million ± £0.5
What our data engineers like about this course is that it is geared towards the data scientists and covers practical issues for statistical computing. Apache Spark : This unified analytics engine for Big Data processing was created in 2009 as a replacement for MapReduce. This keeps you focused on what the data scientists need from you.
Overall the total number of articles and new pages I published exceeded 2017’s figures to claim the second spot behind 2009; our first year in business. Statistics & Data Science. Statistics & Data Science. These are as follows: General Data Articles. Data Visualisation. CDO perspectives. Programme Advice.
In contrast, the decision tree classifies observations based on attribute splits learned from the statistical properties of the training data. Machine Learning-based detection – using statistical learning is another approach that is gaining popularity, mostly because it is less laborious. 3f" % x) dataDF.describe().
Remember that the raw number is not the only important part, we would also measure statistical significance. By late 2009, that experiment was a success, too; they'd climbed back up to 4.5 The result? The properties with professional photography had 2-3 times the number of bookings! The graph is impressive, right?
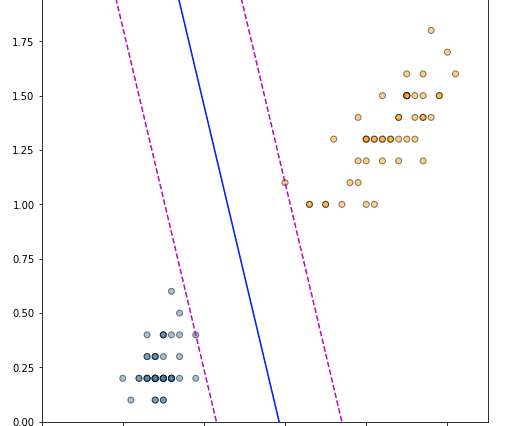
The intuition here is that a decision boundary that leaves a wider margin between the classes generalises better, which leads us to the key property of support vector machines — they construct a hyperplane in a such a way that the margin of separation between the two classes is maximised (Haykin, 2009). Derivation of a Linear SVM. Fisher, R.
Typically, causal inference in data science is framed in probabilistic terms, where there is statistical uncertainty in the outcomes as well as model uncertainty about the true causal mechanism connecting inputs and outputs. 2009, " Measuring invariances in deep networks ". Technical Report 1341, University of Montreal, 2009.
Of course it can be argued that you can use statistics (and Google Trends in particular) to prove anything [1] , but I found the above figures striking. Feel free to substitute Data Lake for Data Warehouse if you want a more modern vibe, sadly it won’t change the failure statistics. . [5]. – McKinsey 2009. . [6].
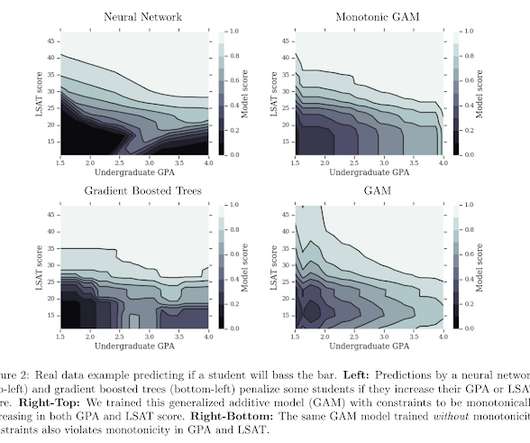
On the one hand, basic statistical models (e.g. by TAMAN NARAYAN & SEN ZHAO A data scientist is often in possession of domain knowledge which she cannot easily apply to the structure of the model. linear regression, trees) can be too rigid in their functional forms. References Wightman, L. LSAC National Longitudinal Bar Passage Study.
They also require advanced skills in statistics, experimental design, causal inference, and so on – more than most data science teams will have. Use of influence functions goes back to the 1970s in robust statistics. evaluate the effects of models on human subjects. measure the subjects’ ability to trust the models’ results.
— Janis Krums (@jkrums) January 15, 2009. Behind the scenes: we run a Storm topology that tracks statistics on search queries. Consider, for example, what happened when Flight 1549 crashed in the Hudson. link] - There’s a plane in the Hudson. I’m on the ferry going to pick up the people.
1) What Is A Misleading Statistic? 2) Are Statistics Reliable? 3) Misleading Statistics Examples In Real Life. 4) How Can Statistics Be Misleading. 5) How To Avoid & Identify The Misuse Of Statistics? If all this is true, what is the problem with statistics? What Is A Misleading Statistic?
When he retired in 2009 he had some time on his hands. ” And this is one of his papers about “you’re doing it wrong” where he talked about the algorithmic culture that he was observing in the machine learning community versus the generative model community that was more traditional in statistics.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content