
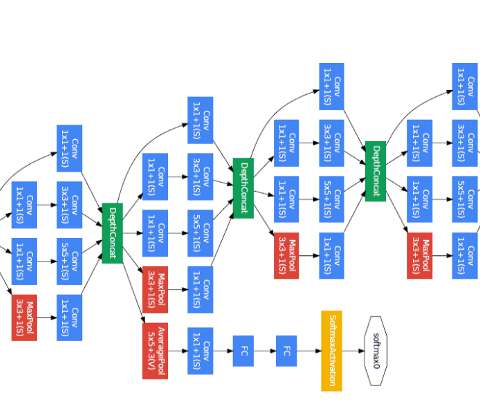
Google BigQuery Architecture for Data Engineers
Analytics Vidhya
JULY 22, 2022
This article was published as a part of the Data Science Blogathon Introduction Google’s BigQuery is an enterprise-grade cloud-native data warehouse. BigQuery was first launched as a service in 2010, with general availability in November 2011.















Let's personalize your content