This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The bucket has to be in the same Region where the OpenSearch Service domain is hosted. Create an IAM role and user Complete the following steps to create your IAM role and user: Create an IAM role to grant permissions to OpenSearch Service. For this post, we name the role TheSnapshotRole. For this post, name the role DestinationSnapshotRole.
“Bigdata is at the foundation of all the megatrends that are happening.” – Chris Lynch, bigdata expert. We live in a world saturated with data. Zettabytes of data are floating around in our digital universe, just waiting to be analyzed and explored, according to AnalyticsWeek. At present, around 2.7
On your project, in the navigation pane, choose Data. For Add data source , choose Add connection. For Host , enter your host name of your Aurora PostgreSQL database cluster. format(connection_properties["HOST"],connection_properties["PORT"],connection_properties["DATABASE"]) df.write.format("jdbc").option("url",
In the trust policy, specify that Amazon Elastic Compute Cloud (Amazon EC2) can assume this role: { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "ec2.amazonaws.com" Launch an EC2 instance Note : Make sure to deploy the EC2 instance for hosting Jenkins in the same VPC as the OpenSearch domain.
Such analytic use cases can be enabled by building a data warehouse or data lake. Customers can now use the AWS Glue SAP OData connector to extract data from SAP. The SAP OData connector supports both on-premises and cloud-hosted (native and SAP RISE) deployments. For more information see AWS Glue.
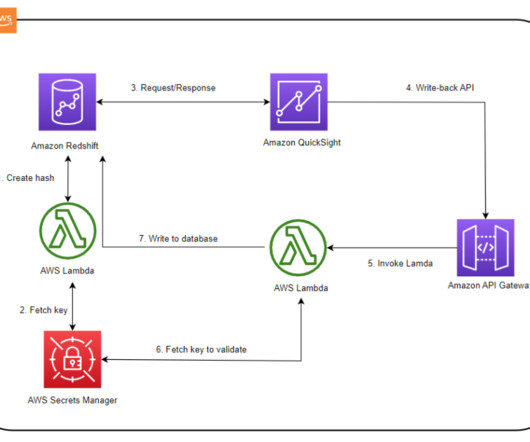
Copy and save the client ID and client secret needed later for the Streamlit application and the IAM Identity Center application to connect using the Redshift Data API. Generate the client secret and set sign-in redirect URL and sign-out URL to [link] (we will host the Streamlit application locally on port 8501).
The workflow consists of the following initial steps: OpenSearch Service is hosted in the primary Region, and all the active traffic is routed to the OpenSearch Service domain in the primary Region. For instructions, see Creating an IAM role (console). We refer to this role as TheSnapshotRole in this post.
To create your pipeline, your manager role that is used to create the pipeline will require iam:PassRole permissions to the pipeline role created in this step.
“Without bigdata, you are blind and deaf and in the middle of a freeway.” – Geoffrey Moore, management consultant, and author. In a world dominated by data, it’s more important than ever for businesses to understand how to extract every drop of value from the raft of digital insights available at their fingertips.
In this post, we delve into the key aspects of using Amazon EMR for modern data management, covering topics such as data governance, data mesh deployment, and streamlined data discovery. Organizations have multiple Hive data warehouses across EMR clusters, where the metadata gets generated. compute.internal ).
Cross-account access has been set up between S3 buckets in Account A with resources in Account B to be able to load and unload data. In the second account, Amazon MWAA is hosted in one VPC and Redshift Serverless in a different VPC, which are connected through VPC peering.
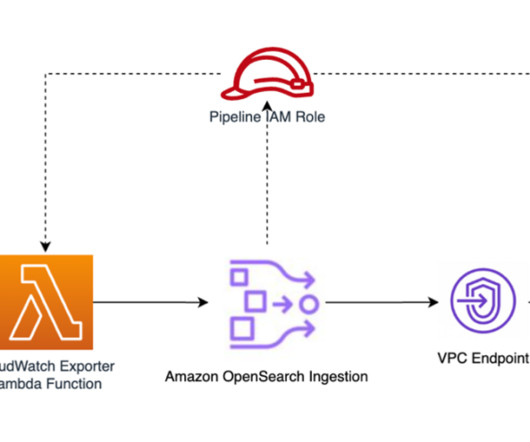
Attach a permissions policy to the role to allow it to read data from the OpenSearch Service domain. Update the following information for the source: Uncomment hosts and specify the endpoint of the existing OpenSearch Service endpoint. This role needs to be specified in the sts_role_arn parameter of the pipeline configuration.
Provide your host name, Region, snapshot repo name, and S3 bucket. import boto3 import requests from requests_aws4auth import AWS4Auth host = ' ' # domain endpoint with trailing / region = ' ' # e.g. us-west-1 service = 'es' credentials = boto3.Session().get_credentials() The Boto3 session should use the RegisterSnapshotRepo IAM role.
Select Custom trust policy and paste the following policy into the editor: { "Version":"2012-10-17", "Statement":[ { "Effect":"Allow", "Principal":{ "Service":"osis-pipelines.amazonaws.com" }, "Action":"sts:AssumeRole" } ] } Choose Next, and then search for and select the collection-pipeline-policy you just created.
arn: " arn:aws:kafka:us-west-2:XXXXXXXXXXXX:cluster/msk-prov-1/id " sink: - opensearch: # Provide an AWS OpenSearch Service domain endpoint # hosts: [ " [link] " ] aws: # Provide a Role ARN with access to the domain. MSK arn – Specifies the MSK cluster to consume data from. region: "us-west-2" msk: # Provide the MSK ARN.
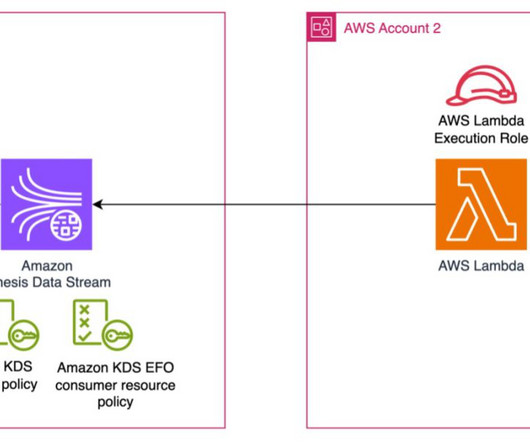
Download and launch CloudFormation template 2 where you want to host the Lambda consumer. KinesisStreamCreateResourcePolicyCommand – This creates the resource policy in Account 1 for Kinesis Data Stream. We recommend using CloudShell because it will have the latest version of the AWS CLI and avoid any kind of failures.
Select the Consumption hosting plan and then choose Select. Create a new function app Complete the following steps to create a new function app: Open your web browser and navigate to the Azure Portal ( portal.azure.com ). Log in with your Azure account credentials. Choose Create a resource. Choose Create under Function App.
To create the connection string, the Snowflake host and account name is required. Using the worksheet, run the following SQL commands to find the host and account name. The account, host, user, password, and warehouse can differ based on your setup. Choose Next. For Secret name , enter airflow/connections/snowflake_accountadmin.
Not only does it support the successful planning and delivery of each edition of the Games, but it also helps each successive OCOG to develop its own vision, to understand how a host city and its citizens can benefit from the long-lasting impact and legacy of the Games, and to manage the opportunities and risks created.
The challenge is to do it right, and a crucial way to achieve it is with decisions based on data and analysis that drive measurable business results. This was the key learning from the Sisense event heralding the launch of Periscope Data in Tel Aviv, Israel — the beating heart of the startup nation. What VCs want from startups.
Amazon EMR on EC2 is a managed service that makes it straightforward to run bigdata processing and analytics workloads on AWS. With Amazon EMR, you can take advantage of the power of these bigdata tools to process, analyze, and gain valuable business intelligence from vast amounts of data.
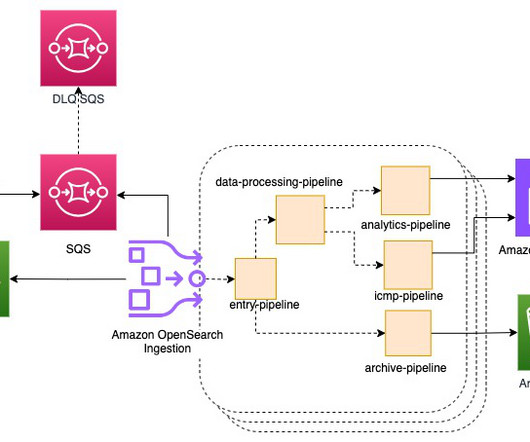
Create an SQS queue Amazon SQS offers a secure, durable, and available hosted queue that lets you integrate and decouple distributed software systems and components. You must have created an OpenSearch Service domain. For instructions, refer to Creating and managing Amazon OpenSearch Service domains.
A participant in one of my Friday #BIWisdom tweetchats observed that “in the mobile ecosystem, BigData + social + the NSA data surveillance news are a perfect storm.” percent of respondents ranked mobile BI as “critically important” in 2012. He hosts a weekly tweet chat (#BIWisdom) on Twitter each Friday.
Spyridon supports the organization in designing, implementing and operating its services in a secure manner protecting the company and users’ data. He has over 13 years of experience in BigData analytics and Data Engineering, where he enjoys building reliable, scalable, and efficient solutions.
In configuring the access policy for this role, you grant permission for the osis:Ingest. { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": " {your-account-id} " }, "Action": "sts:AssumeRole" } ] } Create a pipeline role (called PipelineRole ) with a trust relationship for OpenSearch Ingestion to assume that role.
For example, if the present day is January 10, 2024, and you need data from January 6, 2024 at a specific interval for analysis, you can create an OpenSearch Ingestion pipeline with an Amazon S3 scan in your YAML configuration, with the start_time and end_time to specify when you want the objects in the bucket to be scanned: version: "2" ondemand-ingest-pipeline: (..)
AnyCompany determined that running workloads in the cloud to support its growing global business needs is a competitive advantage and uses the cloud to host all its workloads. Note that the traditional BI tools are read-only with little to no options to update source data. See [link] # We rethrow the exception by default.
This solution uses Amazon Aurora MySQL hosting the example database salesdb. Prerequisites This post assumes you have a running Amazon MSK Connect stack in your environment with the following components: Aurora MySQL hosting a database. In this post, you use the example database salesdb. mysql -f -u master -h mask-lab-salesdb.xxxx.us-east-1.rds.amazonaws.com
It includes perspectives about current issues, themes, vendors, and products for data governance. My interest in data governance (DG) began with the recent industry surveys by O’Reilly Media about enterprise adoption of “ABC” (AI, BigData, Cloud). We keep feeding the monster data. the flywheel effect.
He joined AWS in 2015 and has been focusing in the bigdata analytics space since then, helping customers build scalable and robust solutions using AWS analytics services. He is passionate about building products customers love and helping customers extract value from their data. About the Authors Pathik Shah is a Sr.
In addition to the prerequisite AWS Identity and Access Management (IAM) permissions provided by the role AWSBasicLambdaExecutionRole , the ProcessDevicePosition function requires permissions to perform the S3 put_object action and any other actions required by the data enrichment logic. detail.EventType TrackerName: $.detail.TrackerName
For each Airflow environment, Amazon MWAA creates a single-tenant service VPC, which hosts the metadatabase that stores states and the web server that provides the user interface.
ans from Nick Elprin, CEO and co-founder of Domino Data Lab, about the importance of model-driven business: “Being data-driven is like navigating by watching the rearview mirror. If your business is using bigdata and putting dashboards in front of analysts, you’re missing the point.”. I consider that a healthy trend.
After looking at the historical flight delay data from 2003–2018 at a high level, it was determined that the historical data should be separated into two separate time periods: 2003–2012 and 2013–2018. Only the oldest historical data (2003–2012) had flight delays comparable to 2022.
Insert your specific host domain name where the Keycloak application resides in the following URL: [link] /realms/aws-realm/protocol/saml/descriptor. Change the IdP initiated SSO Relay State to [link]. On the Client scopes tab, choose the client ID. On the Scope tab, make sure the Full scope allowed toggle is set to off.
Under sink, update the following information: Replace the hosts value in the OpenSearch section with the Amazon OpenSearch Service domain endpoint. Additionally, the principal must have permission to pass the pipeline role to OpenSearch Ingestion. In the Specify permissions section, choose JSON to open the policy editor.
2007: Amazon launches SimpleDB, a non-relational (NoSQL) database that allows businesses to cheaply process vast amounts of data with minimal effort. The platform is built on S3 and EC2 using a hosted Hadoop framework. An efficient bigdata management and storage solution that AWS quickly took advantage of.
When this is not the case, the platform teams themselves need to develop custom functionality at the host level to ensure that role accesses are correctly controlled. Conclusion This post shows an approach to building a scalable and secure data and analytics platform.
To avoid this constraint, a number of compute units can be scaled out to provide additional capacity for hosting additional instances of RCFInstances. Create a dead-letter queue with the following code export SQS_DLQ_URL=$(aws sqs create-queue --queue-name VpcFlowLogsNotifications-DLQ | jq -r '.QueueUrl')
In the digital age, those who can squeeze every single drop of value from the wealth of data available at their fingertips, discovering fresh insights that foster growth and evolution, will always win on the commercial battlefield. Moreover, 83% of executives have pursued bigdata projects to gain a competitive edge.
It’s hosted by Simmons College and features high-profile speakers, with Serena Williams among those scheduled to speak at the latest upcoming event. Topics include cybersecurity, blockchain, AI, VR, digital transformation, bigdata, security, entrepreneurship, startups, and healthcare technology.
December 18, 2012 Dresner’s Point: Will Amazon’s Redshift Become a BI Swiss Army Knife? BIWisdom tweetchat tribe members were facing off in response to the question of whether the EDW (electronic data warehouse) is dead. December 11, 2012 Dresner’s Point: What’s Innovation Worth in BI? Once upon a time.
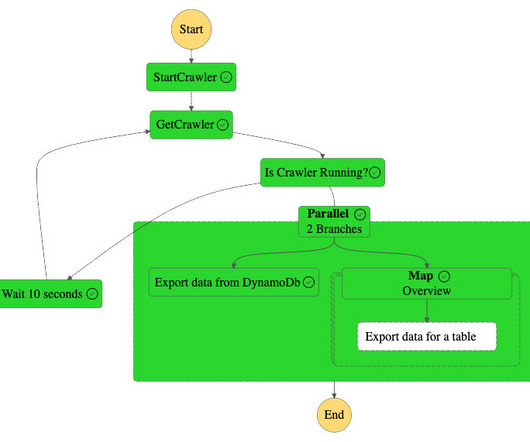
There are multiple tables related to customers and order data in the RDS database. Amazon S3 hosts the metadata of all the tables as a.csv file. For more information, refer to IAM Policies for invoking AWS Glue job from Step Functions. The following diagram illustrates the Step Functions workflow.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content