This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Migration – Manual snapshots can be useful when you want to migrate data from one domain to another. Testing and development – You can use snapshots to create copies of your data for testing or development purposes. This allows you to experiment with your data without affecting the production environment.
It is advised to discourage contributors from making changes directly to the production OpenSearch Service domain and instead implement a gatekeeper process to validate and test the changes before moving them to OpenSearch Service. Jenkins retrieves JSON files from the GitHub repository and performs validation. Leave the settings as default.
For each service, you need to learn the supported authorization and authentication methods, data access APIs, and framework to onboard and testdata sources. This approach simplifies your data journey and helps you meet your security requirements. Noritaka Sekiyama is a Principal BigData Architect on the AWS Glue team.
Each time, the underlying implementation changed a bit while still staying true to the larger phenomenon of “Analyzing Data for Fun and Profit.” ” They weren’t quite sure what this “data” substance was, but they’d convinced themselves that they had tons of it that they could monetize.
In fact, a Digital Universe study found that the total data supply in 2012 was 2.8 Based on that amount of data alone, it is clear the calling card of any successful enterprise in today’s global world will be the ability to analyze complex data, produce actionable insights and adapt to new market needs… all at the speed of thought.
Use ML to unlock new data types—e.g., Consider deep learning, a specific form of machine learning that resurfaced in 2011/2012 due to record-setting models in speech and computer vision. Thus, many developers will need to curate data, train models, and analyze the results of models. A typical data pipeline for machine learning.
On the Code + Test page, replace the sample code with the following code, which retrieves the users group membership, and choose Save. Test the SSO setup You can now test the SSO setup. Choose Test this application. Run a SQL statement to get data from sales_table. Log in as user C to test access for user C.
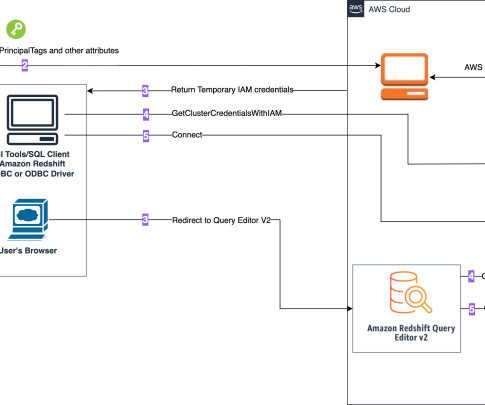
Data loading Amazon Redshift Query Editor v2 comes with sample data that can be loaded into a sample database and corresponding schema. To test Query profiler against the sample data, load the tpcds sample data and run queries.
Let’s test them and see the differences. About the Authors Noritaka Sekiyama is a Principal BigData Architect on the AWS Glue team. Gonzalo Herreros is a Senior BigData Architect on the AWS Glue team, with a background in machine learning and AI. Open the AWS Glue console with the blogDeveloper user.
In this post, we delve into the key aspects of using Amazon EMR for modern data management, covering topics such as data governance, data mesh deployment, and streamlined data discovery. Organizations have multiple Hive data warehouses across EMR clusters, where the metadata gets generated. compute.internal ).
In the modern world of business, data is one of the most important resources for any organization trying to thrive. Business data is highly valuable for cybercriminals. They even go after meta data. Bigdata can reveal trade secrets, financial information, as well as passwords or access keys to crucial enterprise resources.
In this post, we’ll discuss these challenges in detail and include some tips and tricks to help you handle text data more easily. Unstructured data and BigData. Most common challenges we face in NLP are around unstructured data and BigData. is “big” and highly unstructured.
The policies attached to the Amazon MWAA role have full access and must only be used for testing purposes in a secure test environment. For more information, see Accessing an Amazon MWAA environment. For production deployments, follow the least privilege principle.
Companies are spending nearly $30 billion a year on bigdata for marketing initiatives. One of the many reasons that they are using bigdata is to create better content marketing strategies. Despite the many benefits of bigdata for content marketing, many businesses still don’t know how to utilize it effectively.
“Without bigdata, you are blind and deaf and in the middle of a freeway.” – Geoffrey Moore, management consultant, and author. In a world dominated by data, it’s more important than ever for businesses to understand how to extract every drop of value from the raft of digital insights available at their fingertips.
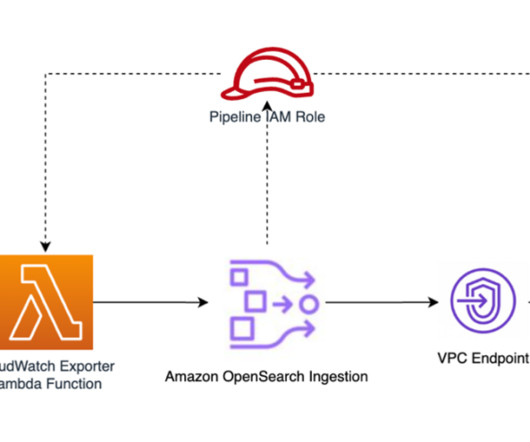
Select Custom trust policy and paste the following policy into the editor: { "Version":"2012-10-17", "Statement":[ { "Effect":"Allow", "Principal":{ "Service":"osis-pipelines.amazonaws.com" }, "Action":"sts:AssumeRole" } ] } Choose Next, and then search for and select the collection-pipeline-policy you just created.
Use proper semantic conventions when providing the cluster, topic, and group permissions and remove the comments from the policy before using. { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "osis-pipelines.aws.internal" }, "Action": [ "kafka:CreateVpcConnection", "kafka:GetBootstrapBrokers", "kafka:DescribeCluster" (..)
AWS Glue Data Quality is built on DeeQu , an open source tool developed and used at Amazon to calculate data quality metrics and verify data quality constraints and changes in the data distribution so you can focus on describing how data should look instead of implementing algorithms.
Danger of BigData. Bigdata is the rage. This could be lots of rows (samples) and few columns (variables) like credit card transaction data, or lots of columns (variables) and few rows (samples) like genomic sequencing in life sciences research. Statistical methods for analyzing this two-dimensional data exist.
git clone [link] cd automate-and-simplify-aws-glue-data-asset-publish-to-amazon-datazone At the base of the repository folder, run the following commands to build and deploy resources to AWS. However for testing, you can manually run the crawler by going to the AWS Glue console and selecting Crawlers from the navigation pane.
When the Lambda function is triggered, the data sent to the function includes an array of records from the Kafka topic—no need for direct contact with Amazon MSK. For testing, this post includes a sample AWS Cloud Development Kit (AWS CDK) application. Prerequisites The example has the following prerequisites: An AWS account.
Snapshot Management helps you create point-in-time backups of your domain using OpenSearch Dashboards, including both data and configuration settings (for visualizations and dashboards). Before this release, to automate the process of taking snapshots, you needed to use the snapshot action of OpenSearch’s Index State Management (ISM) feature.
Reverse ETL use cases are also supported, allowing you to write data back to Salesforce. You can use Amazon Athena to query the data: SELECT id, name, type, active__c, upsellopportunity__c, lastmodifieddate FROM "glue_etl_salesforce_db"."account" BigData and ETL Solutions Architect, Amazon MWAA and AWS Glue ETL expert.
The following is an example authorization policy for a cluster named MyTestCluster. catch(console.error) You are now finished with all the code changes.
Due to these limitations, the application should not be used for arbitrary tests. We also show how to test the function with Lambda tests. Choose the users_tbl Inspect the LF-Tags associated to the different columns in the Schema Review the Lake Formation permissions: Choose Data lake permissions in the navigation pane.
Use Lake Formation to grant permissions to users to access data. Test the solution by accessing data with a corporate identity. Audit user data access. Create an IAM Identity Center enabled security configuration for EMR clusters. Create a Service Catalog product template to create the EMR clusters. Choose Grant.
AWS Data Pipeline helps customers automate the movement and transformation of data. With Data Pipeline, customers can define data-driven workflows, so that tasks can be dependent on the successful completion of previous tasks. He is responsible for building software artifacts to help customers.
Analysts performing ad hoc analyses in their workspace need to load sample data in Amazon Redshift by creating a table and load data from desktop. They want to join that data with the curated data in their data warehouse. He helps customers architect data analytics solutions at scale on the AWS platform.
Many customers run bigdata workloads such as extract, transform, and load (ETL) on Apache Hive to create a data warehouse on Hadoop. json ) to DynamoDB (for more information, refer to Write data to a table using the console or AWS CLI ): { "name": "step1.q", He is passionate about bigdata and data analytics.
Amazon EMR on EC2 is a managed service that makes it straightforward to run bigdata processing and analytics workloads on AWS. With Amazon EMR, you can take advantage of the power of these bigdata tools to process, analyze, and gain valuable business intelligence from vast amounts of data.
BigData Cloud Engineer ( ETL ) specialized in AWS Glue. Omar Elkharbotly is a Glue SME who works as BigData Cloud Support Engineer 2 (DIST). He is dedicated to assisting customers in resolving issues related to their ETL workloads and creating scalable data processing and analytics pipelines on AWS.
A participant in one of my Friday #BIWisdom tweetchats observed that “in the mobile ecosystem, BigData + social + the NSA data surveillance news are a perfect storm.” percent of respondents ranked mobile BI as “critically important” in 2012. So mobile BI adoption will grow despite its current drawbacks.
However, there has to be different dashboards and datasets for each non-production environment, such as development and testing. For deployments, the import job API provides the capability to pass data source configurations to point to the respective test or production instances of data sources.
If you’re testing on a different Amazon MWAA version, update the requirements file accordingly. For testing purposes, you can choose Add permissions and add the managed AmazonS3FullAccess policy to the user instead of providing restricted access. The requirements file is based on Amazon MWAA version 2.6.3.
In our example, we have configured a ruleset against a table containing patient data within a healthcare synthetic dataset generated using Synthea. Synthea is a synthetic patient generator that creates realistic patient data and associated medical records that can be used for testing healthcare software applications.
This solution includes a Lambda function that continuously updates the Amazon Location tracker with simulated location data from fictitious journeys. You can test this solution yourself using the AWS Samples GitHub repository. The Lambda function is triggered at regular intervals using a scheduled EventBridge rule.
Clean up When you’re done testing the solution, clean up the resources to avoid incurring future charges: Delete the Redshift provisioned cluster. If you’re getting errors while setting up the application on Okta, make sure you have admin access. Delete the IAM roles, IAM IdPs, and IAM policies.
Then to perform more complex data analysis such as regression tests and time series forecasting, you can use Apache Spark with Python, which allows you to take advantage of a rich ecosystem of libraries, including data visualization in Matplot, Seaborn, and Plotly. About the Authors Pathik Shah is a Sr.
Delete the Lake Formation application and the Redshift provisioned cluster that you created for testing. Srividya Parthasarathy is a Senior BigData Architect on the AWS Lake Formation team. She enjoys building data mesh solutions and sharing them with the community.
In the navigation pane, under Data Catalog , choose Catalog settings. Test your IAM Identity Center and Amazon Redshift integration with QuickSight Now you’re ready to connect to Amazon Redshift using QuickSight. Clean up Complete the following steps to clean up your resources: Delete the data from the S3 bucket.
Test the login to OpenSearch Dashboards. You can create an Okta Developer Edition free account to test the setup. Map IAM roles to OpenSearch Service roles. Create the DynamoDB attribute-role mapping table. Deploy and configure the pre-token generation Lambda function. Configure the pre-token generation Lambda trigger.
Test the filter by selecting the actual log stream. For testing, use the following pattern and choose Test pattern. We use the following commands to test the solution; however, this is not restricted to these commands only. In the Create policy section, choose the JSON tab and enter the following IAM policy.
Choose Test from SQL Workbench/J to test the connection. Clean up When you’re done testing the solution, clean up the resources to avoid incurring future charges: Delete the Redshift Serverless instance by deleting both the workgroup and the namespace. Choose Create policy. On the Create policy page, choose the JSON tab.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















































Let's personalize your content