This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The bucket has to be in the same Region where the OpenSearch Service domain is hosted. Create an IAM role and user Complete the following steps to create your IAM role and user: Create an IAM role to grant permissions to OpenSearch Service. For this post, we name the role TheSnapshotRole. For this post, name the role DestinationSnapshotRole.
By acquiring a deep working understanding of data science and its many business intelligence branches, you stand to gain an all-important competitive edge that will help to position your business as a leader in its field. Data science, also known as data-driven science, covers an incredibly broad spectrum.
The workflow consists of the following initial steps: OpenSearch Service is hosted in the primary Region, and all the active traffic is routed to the OpenSearch Service domain in the primary Region. Samir works directly with enterprise customers to design and build customized solutions catered to their dataanalytics and cybersecurity needs.
Such analytic use cases can be enabled by building a data warehouse or data lake. Customers can now use the AWS Glue SAP OData connector to extract data from SAP. The SAP OData connector supports both on-premises and cloud-hosted (native and SAP RISE) deployments.
In todays data-driven world, securely accessing, visualizing, and analyzing data is essential for making informed business decisions. The Amazon Redshift Data API simplifies access to your Amazon Redshift data warehouse by removing the need to manage database drivers, connections, network configurations, data buffering, and more.
You can use this approach for a variety of real-time data ingestion use cases, and add it to existing workloads that use Kinesis Data Streams for real-time dataanalytics.
Business leaders, developers, data heads, and tech enthusiasts – it’s time to make some room on your business intelligence bookshelf because once again, datapine has new books for you to add. We have already given you our top data visualization books , top business intelligence books , and best dataanalytics books.
The producer account will host the EMR cluster and S3 buckets. The catalog account will host Lake Formation and AWS Glue. The consumer account will host EMR Serverless, Athena, and SageMaker notebooks. Prerequisites You need three AWS accounts with admin access to implement this solution. It is recommended to use test accounts.
Cross-account access has been set up between S3 buckets in Account A with resources in Account B to be able to load and unload data. In the second account, Amazon MWAA is hosted in one VPC and Redshift Serverless in a different VPC, which are connected through VPC peering.
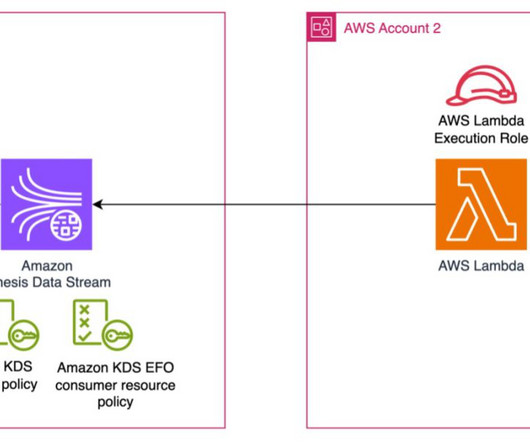
Download and launch CloudFormation template 2 where you want to host the Lambda consumer. KinesisStreamCreateResourcePolicyCommand – This creates the resource policy in Account 1 for Kinesis Data Stream. We recommend using CloudShell because it will have the latest version of the AWS CLI and avoid any kind of failures.
To create the connection string, the Snowflake host and account name is required. Using the worksheet, run the following SQL commands to find the host and account name. The account, host, user, password, and warehouse can differ based on your setup. Choose Next. For Secret name , enter airflow/connections/snowflake_accountadmin.
Not only does it support the successful planning and delivery of each edition of the Games, but it also helps each successive OCOG to develop its own vision, to understand how a host city and its citizens can benefit from the long-lasting impact and legacy of the Games, and to manage the opportunities and risks created.
About the Authors Pradeep Misra is a Principal Analytics Solutions Architect at AWS. He works across Amazon to architect and design modern distributed analytics and AI/ML platform solutions. He is passionate about solving customer challenges using data, analytics, and AI/ML.
This solution uses Amazon Aurora MySQL hosting the example database salesdb. Prerequisites This post assumes you have a running Amazon MSK Connect stack in your environment with the following components: Aurora MySQL hosting a database. He works with AWS customers to design and build real time data processing systems.
Dataanalytics – Business analysts gather operational insights from multiple data sources, including the location data collected from the vehicles. Query the data using Athena Athena is a serverless, interactive analytics service built to analyze unstructured, semi-structured, and structured data where it is hosted.
This was the key learning from the Sisense event heralding the launch of Periscope Data in Tel Aviv, Israel — the beating heart of the startup nation. An exciting slate of presentations took them on a journey from why to how they should use dataanalytics to optimize their operations successfully and maximize their business opportunities.
About the Authors Raj Patel is AWS Lead Consultant for DataAnalytics solutions based out of India. He specializes in building and modernising analytical solutions. His background is in data warehouse/data lake – architecture, development and administration.
After looking at the historical flight delay data from 2003–2018 at a high level, it was determined that the historical data should be separated into two separate time periods: 2003–2012 and 2013–2018. Only the oldest historical data (2003–2012) had flight delays comparable to 2022.
Spyridon supports the organization in designing, implementing and operating its services in a secure manner protecting the company and users’ data. He has over 13 years of experience in Big Dataanalytics and Data Engineering, where he enjoys building reliable, scalable, and efficient solutions.
Analytics Architect on Amazon Athena. He joined AWS in 2015 and has been focusing in the big dataanalytics space since then, helping customers build scalable and robust solutions using AWS analytics services. He is passionate about building products customers love and helping customers extract value from their data.
She had much to say to leaders of data science teams, coming from perspectives of data engineering at scale. And by “scale” I’m referring to what is arguably the largest, most successful dataanalytics operation in the cloud of any public firm that isn’t a cloud provider. Rev 2 wrap up. See you at Rev 3 in 2020!
2007: Amazon launches SimpleDB, a non-relational (NoSQL) database that allows businesses to cheaply process vast amounts of data with minimal effort. The platform is built on S3 and EC2 using a hosted Hadoop framework. An efficient big data management and storage solution that AWS quickly took advantage of. To be continued.
To avoid this constraint, a number of compute units can be scaled out to provide additional capacity for hosting additional instances of RCFInstances. Mikhail specializes in dataanalytics services. amazonaws.com"}, "Action":"SQS:SendMessage","Resource":"*"}]}" }' | jq -r '.QueueUrl')
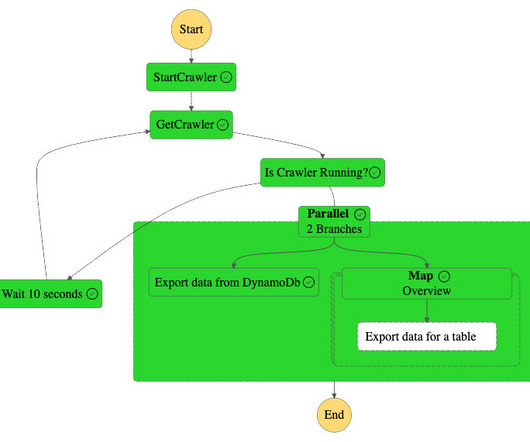
There are multiple tables related to customers and order data in the RDS database. Amazon S3 hosts the metadata of all the tables as a.csv file. Over the years, he has helped multiple customers on data platform transformations across industry verticals. The following diagram illustrates the Step Functions workflow.
SageMaker Unified Studio is part of the next generation of Amazon SageMaker, the center for all your data, analytics, and AI. In Part 1 of this series, we explored how to access AWS Glue Data Catalog tables and Amazon Redshift resources through SageMaker Unified Studio. In your project, in the navigation pane, choose Data.
Many organizations build and operate enterprise-wide data mesh architectures using the AWS Glue Data Catalog and AWS Lake Formation for their Amazon Simple Storage Service (Amazon S3) based data lakes. An S3 bucket in the producer account to host the sample Iceberg table data.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content