

How Volkswagen streamlined access to data across multiple data lakes using Amazon DataZone – Part 1
AWS Big Data
JULY 18, 2024
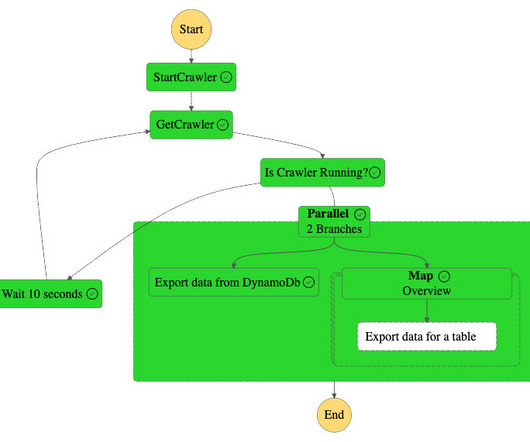
Over the years, organizations have invested in creating purpose-built, cloud-based data lakes that are siloed from one another. A major challenge is enabling cross-organization discovery and access to data across these multiple data lakes, each built on different technology stacks.

































Let's personalize your content