This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
licensed, 100% open-source data table format that helps simplify data processing on large datasets stored in datalakes. Data engineers use Apache Iceberg because it’s fast, efficient, and reliable at any scale and keeps records of how datasets change over time.
You can navigate to the projects Data page to visually verify the existence of the newly created table. On the top left menu, choose your project name, and under CURRENT PROJECT , choose Data. Additionally, the notebook provides a chart view to visualize query results as graphs. Under Create job , choose Visual ETL.
Customers often want to augment and enrich SAP source data with other non-SAP source data. Such analytic use cases can be enabled by building a data warehouse or datalake. Customers can now use the AWS Glue SAP OData connector to extract data from SAP. Choose Visual ETL to create a job in the Visual Editor.
We are excited to announce a new capability of the AWS Glue Studio visual editor that offers a new visual user experience. Now you can author data preparation transformations and edit them with the AWS Glue Studio visual editor. You can configure all these steps in the visual editor in AWS Glue Studio.
At the same time, they need to optimize operational costs to unlock the value of this data for timely insights and do so with a consistent performance. With this massive data growth, data proliferation across your data stores, data warehouse, and datalakes can become equally challenging.
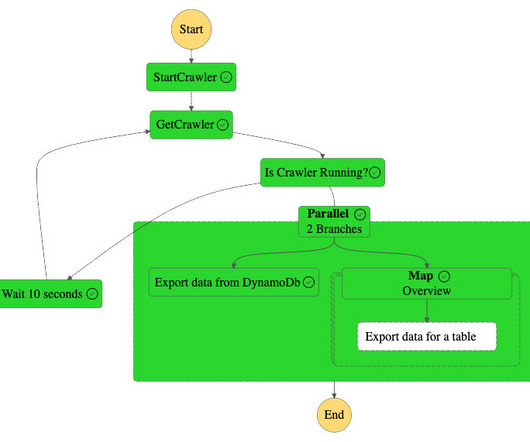
As the volume and complexity of analytics workloads continue to grow, customers are looking for more efficient and cost-effective ways to ingest and analyse data. AWS Glue provides both visual and code-based interfaces to make data integration effortless. The following diagram illustrates the solution architecture.
Modern applications store massive amounts of data on Amazon Simple Storage Service (Amazon S3) datalakes, providing cost-effective and highly durable storage, and allowing you to run analytics and machine learning (ML) from your datalake to generate insights on your data.
In recent years, datalakes have become a mainstream architecture, and data quality validation is a critical factor to improve the reusability and consistency of the data. On the AWS Glue console, under ETL jobs in the navigation pane, choose Visual ETL. In the Create job section, choose Visual ETL.x
AWS Data Pipeline helps customers automate the movement and transformation of data. With Data Pipeline, customers can define data-driven workflows, so that tasks can be dependent on the successful completion of previous tasks. You can visually create, run, and monitor ETL pipelines to load data into your datalakes.
He talked through how the mind-blowing escalation of data and the drastic reduction in the cost of its storage has led to more complex, sophisticated uses of data and a shift in the way it’s managed and consumed. He concluded that data teams can influence the transformation of startups into unicorns. A true unicorn.
For sales across multiple markets, the product sales data such as orders, transactions, and shipment data is available on Amazon S3 in the datalake. The data engineering team can use Apache Spark with Amazon EMR or AWS Glue to analyze this data in Amazon S3. enableHiveSupport().getOrCreate()
Optionally, specify the Amazon S3 storage class for the data in Amazon Security Lake. For more information, refer to Lifecycle management in Security Lake. Review the details and create the datalake. Choose Next. Choose Component templates to verify the OCSF component templates.
2012: Amazon Redshift, the first of its kind cloud-based data warehouse service comes into existence. Microsoft also releases Power BI, a datavisualization and business intelligence tool. Google launches BigQuery, its own data warehousing tool and Microsoft introduces Azure SQL Data Warehouse and Azure DataLake Store.
Somehow, the gravity of the data has a geological effect that forms datalakes. Also, data science workflows begin to create feedback loops from the big data side of the illo above over to the DW side. DG emerges for the big data side of the world, e.g., the Alation launch in 2012.
He’s been out of Wolfram for a while and writing exquisite science books including Elements: A Visual Explanation of Every Known Atom in the Universe and Molecules: The Architecture of Everything. Historically, grad students in physics and physical sciences have been excellent candidates for data science teams. Or something.
And so I actually transitioned out of that group and into the Big Data Appliance group at Oracle, but soon realized that if that was what I wanted to keep doing, this up and coming company called Cloudera might be a better place to do it since these new technologies weren’t just a hobby at Cloudera. As you mentioned, Qlik is in there.
AWS Step Functions is a fully managed visual workflow service that enables you to build complex data processing pipelines involving a diverse set of extract, transform, and load (ETL) technologies such as AWS Glue , Amazon EMR , and Amazon Redshift. On the Step Functions console, navigate to the failed workflow you want to redrive.
The ETL application will use IAM role-based access to the Iceberg table, and the data analyst gets Lake Formation permissions to query the same tables. The solution can be visually represented in the following diagram. Read the latest update, again, as Data-Analyst.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content