

Use Apache Iceberg in your data lake with Amazon S3, AWS Glue, and Snowflake
AWS Big Data
APRIL 3, 2024
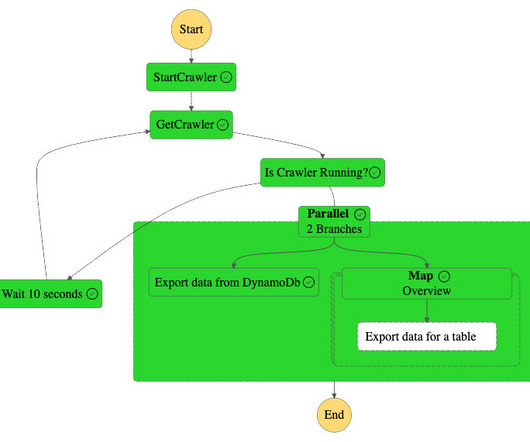
licensed, 100% open-source data table format that helps simplify data processing on large datasets stored in data lakes. Data engineers use Apache Iceberg because it’s fast, efficient, and reliable at any scale and keeps records of how datasets change over time.























Let's personalize your content