This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By gaining the ability to understand, quantify, and leverage the power of online data analysis to your advantage, you will gain a wealth of invaluable insights that will help your business flourish. The ever-evolving, ever-expanding discipline of datascience is relevant to almost every sector or industry imaginable – on a global scale.
I got my first datascience job in 2012, the year Harvard Business Review announced data scientist to be the sexiest job of the 21st century. Two years later, I published a post on my then-favourite definition of datascience , as the intersection between software engineering and statistics.
Use ML to unlock new data types—e.g., Consider deep learning, a specific form of machine learning that resurfaced in 2011/2012 due to record-setting models in speech and computer vision. 58% of survey respondents indicated they are building or evaluating datascience platforms. Key features of many datascience platforms.
I learned about Bayesian statistics and conjugate priors. Towards the end of my PhD in 2012, I got into Kaggle competitions. Back then, it seemed like “real” datascience consisted of building and tuning machine learning models – that’s what Kaggle was all about.
There are three main reasons why datascience has been rated as a top job according to research. Firstly, the number of available job openings is rapidly increasing and the highest in comparison to other jobs, datascience has an extremely high job satisfaction rating, and the median annual salary base is undeniably desirable.
Statistical methods for analyzing this two-dimensional data exist. This statistical test is correct because the data are (presumably) bivariate normal. When there are many variables the Curse of Dimensionality changes the behavior of data and standard statistical methods give the wrong answers.
Datascience has been a hot term in the past few years. Despite this fact (or perhaps because of it), it still seems like there isn't a single unifying definition of datascience. Data Scientist (n.): This post discusses my favourite definition.
Paco Nathan ‘s latest monthly article covers Sci Foo as well as why datascience leaders should rethink hiring and training priorities for their datascience teams. In this episode I’ll cover themes from Sci Foo and important takeaways that datascience teams should be tracking. Introduction.
In fact, you may have even heard about IDC’s new Global DataSphere Forecast, 2021-2025 , which projects that global data production and replication will expand at a compound annual growth rate of 23% during the projection period, reaching 181 zettabytes in 2025. zettabytes of data in 2020, a tenfold increase from 6.5
SCOTT Time series data are everywhere, but time series modeling is a fairly specialized area within statistics and datascience. Introduction Time series data appear in a surprising number of applications, ranging from business, to the physical and social sciences, to health, medicine, and engineering.
Conducting exploratory analysis and extracting meaningful insights from data are core components of research and datascience work. Time series data is commonly encountered. We see it when working with log data, financial data, transactional data, and when measuring anything in a real engineering system.
In contrast, the decision tree classifies observations based on attribute splits learned from the statistical properties of the training data. Machine Learning-based detection – using statistical learning is another approach that is gaining popularity, mostly because it is less laborious. 3f" % x) dataDF.describe().
But importance sampling in statistics is a variance reduction technique to improve the inference of the rate of rare events, and it seems natural to apply it to our prevalence estimation problem. StatisticalScience. Statistics in Biopharmaceutical Research, 2010. [4] 5] Ray Chambers, Robert Clark (2012).
Identification We now discuss formally the statistical problem of causal inference. We start by describing the problem using standard statistical notation. The field of statistical machine learning provides a solution to this problem, allowing exploration of larger spaces. For a random sample of units, indexed by $i = 1.
The data scientist. In 2012 Davenport and Patil declared the data scientist was “ The Sexiest Job of the 21st Century.” Universities were only just beginning to plan formal academic datascience programs, and the skills to be taught in those programs were still being identified. Why is so much time wasted?
Paco Nathan covers recent research on data infrastructure as well as adoption of machine learning and AI in the enterprise. Welcome back to our monthly series about datascience! This month, the theme is not specifically about conference summaries; rather, it’s about a set of follow-up surveys from Strata Data attendees.
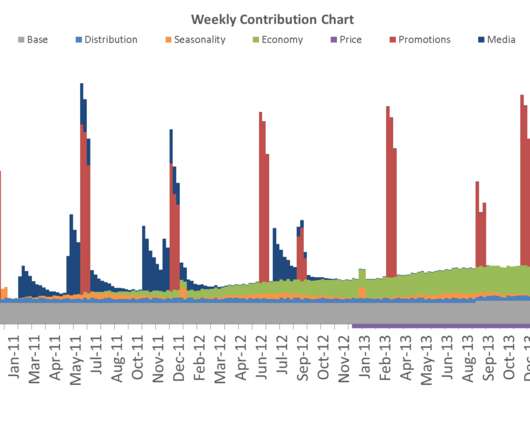
In the first plot, the raw weekly actuals (in red) are adjusted for a level change in September 2011 and an anomalous spike near October 2012. Prediction Intervals A statistical forecasting system should not lack uncertainty quantification. Forecasting data and methods". [2] Journal of Official Statistics 6.1 1990): 3. [3]
MMM stands for Marketing Mix Model and it is one of the oldest and most well-established techniques to measure the sales impact of marketing activity statistically. Data Requirements. As with any type of statistical model, data is key and GIGO (“Garbage In, Garbage Out”) principle definitely applies. What is MMM?
If $Y$ at that point is (statistically and practically) significantly better than our current operating point, and that point is deemed acceptable, we update the system parameters to this better value. e-handbook of statistical methods: Summary tables of useful fractional factorial designs , 2018 [3] Ulrike Groemping. Hedayat, N.J.A.
We often use statistical models to summarize the variation in our data, and random effects models are well suited for this — they are a form of ANOVA after all. Cambridge University Press, (2012). [4] Journal of the American Statistical Association 68.341 (1973): 117-130. [5] 4] Bradley Efron, and Carl Morris.
Statistical power is traditionally given in terms of a probability function, but often a more intuitive way of describing power is by stating the expected precision of our estimates. This is a quantity that is easily interpretable and summarizes nicely the statistical power of the experiment. In the U.S., Cambridge, 2007.
Paco Nathan presented, “DataScience, Past & Future” , at Rev. At Rev’s “ DataScience, Past & Future” , Paco Nathan covered contextual insight into some common impactful themes over the decades that also provided a “lens” help data scientists, researchers, and leaders consider the future.
From 2000 to 2015, I had some success [5] with designing and implementing Data Warehouse architectures much like the following: As a lot of my work then was in Insurance or related fields, the Analytical Repositories tended to be Actuarial Databases and / or Exposure Management Databases, developed in collaboration with such teams.
1]" Statistics, as a discipline, was largely developed in a small data world. Data was expensive to gather, and therefore decisions to collect data were generally well-considered. Implicitly, there was a prior belief about some interesting causal mechanism or an underlying hypothesis motivating the collection of the data.
We try use the Bake-Offs as a platform for data for good. Rather than just using some solely fun data like football/ soccer statistics – go Mo Salah! – this year, we used population health data. Last year we did loneliness and happiness data. ThoughtSpot. In 2016, life expectancy in the United States (78.5)
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content