This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that makes it simple and cost-effective to analyze your data using standard SQL and your existing business intelligence (BI) tools. Data ingestion is the process of getting data to Amazon Redshift.
Unifying these necessitates additional data processing, requiring each business unit to provision and maintain a separate datawarehouse. This burdens business units focused solely on consuming the curated data for analysis and not concerned with data management tasks, cleansing, or comprehensive data processing.
Amazon AppFlow automatically encrypts data in motion, and allows you to restrict data from flowing over the public internet for SaaS applications that are integrated with AWS PrivateLink , reducing exposure to security threats. He has worked with building datawarehouses and big data solutions for over 13 years.
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that lets you analyze your data at scale. Amazon Redshift Serverless lets you access and analyze data without the usual configurations of a provisioned datawarehouse. In her spare time, Blessing loves travels and adventures.
You can learn how to query Delta Lake native tables through UniForm from different datawarehouses or engines such as Amazon Redshift as an example of expanding data access to more engines. For those datawarehouses, Delta Lake tables need to be converted to manifest tables, which requires additional operational overhead.
Tens of thousands of customers use Amazon Redshift for modern data analytics at scale, delivering up to three times better price-performance and seven times better throughput than other cloud datawarehouses. This makes sure that user access and roles are consistently maintained across both AWS services and external tools.
Fauna was founded in 2012 by software infrastructure engineers Evan Weaver and Matt Freels to develop the cloud-native transactional database product they would have liked to have had at their disposal in their former roles at what was then known as Twitter (now X).
Amazon Redshift is a fully managed, petabyte-scale datawarehouse service in the cloud that delivers powerful and secure insights on all your data with the best price-performance. With Amazon Redshift, you can analyze your data to derive holistic insights about your business and your customers.
Business intelligence concepts refer to the usage of digital computing technologies in the form of datawarehouses, analytics and visualization with the aim of identifying and analyzing essential business-based data to generate new, actionable corporate insights. The datawarehouse. 1) The raw data.
The new version includes details on the latest SQL features such as techniques for wrangling data, as well as two new chapters, one dedicated to setting up your own system, and another for using PostgreSQL and JSON. This piece, published in 2012, offers a step-to-step guide on everything related to SQL. Viescas, Douglas J.
and zero-ETL support) as the source, and a Redshift datawarehouse as the target. The integration replicates data from the source database into the target datawarehouse. Additionally, you can choose the capacity, to limit the compute resources of the datawarehouse. For this post, set this to 8 RPUs.
Snowflake was founded in 2012 to build a business around its cloud-based datawarehouse with built-in data-sharing capabilities. Snowflake has expanded its reach over the years to address data engineering and data science, and long ago moved beyond being seen as just a cloud datawarehouse.
There are two broad approaches to analyzing operational data for these use cases: Analyze the data in-place in the operational database (e.g. With Aurora zero-ETL integration with Amazon Redshift, the integration replicates data from the source database into the target datawarehouse.
One of the key challenges in modern big data management is facilitating efficient data sharing and access control across multiple EMR clusters. Organizations have multiple Hive datawarehouses across EMR clusters, where the metadata gets generated. compute.internal ). Choose Submit job run.
Customers often want to augment and enrich SAP source data with other non-SAP source data. Such analytic use cases can be enabled by building a datawarehouse or data lake. Customers can now use the AWS Glue SAP OData connector to extract data from SAP.
The extract, transform, and load (ETL) process has been a common pattern for moving data from an operational database to an analytics datawarehouse. ELT is where the extracted data is loaded as is into the target first and then transformed. ETL and ELT pipelines can be expensive to build and complex to manage.
Amazon Redshift is a fast, petabyte-scale, cloud datawarehouse that tens of thousands of customers rely on to power their analytics workloads. With its massively parallel processing (MPP) architecture and columnar data storage, Amazon Redshift delivers high price-performance for complex analytical queries against large datasets.
Amazon Redshift is a fast, fully managed, petabyte-scale datawarehouse service that makes it simple and cost-effective to analyze all your data efficiently and securely. Users such as data analysts, database developers, and data scientists use SQL to analyze their data in Amazon Redshift datawarehouses.
Tens of thousands of customers rely on Amazon Redshift to analyze exabytes of data and run complex analytical queries. You can use your preferred SQL clients to analyze your data in an Amazon Redshift datawarehouse. He is passionate about automating and solving customer problems with cloud solutions.
After having rebuilt their datawarehouse, I decided to take a little bit more of a pointed role, and I joined Oracle as a database performance engineer. I spent eight years in the real-world performance group where I specialized in high visibility and high impact data warehousing competes and benchmarks.
New feature: Custom AWS service blueprints Previously, Amazon DataZone provided default blueprints that created AWS resources required for data lake, datawarehouse, and machine learning use cases. You can build projects and subscribe to both unstructured and structured data assets within the Amazon DataZone portal.
It can generate data integration jobs for extracts and loads to S3 data lakes including file formats like CSV, JSON, and Parquet, and ingestion into open table formats like Apache Hudi, Delta, and Apache Iceberg. Prerequisites Before going forward with this tutorial, complete the following prerequisites: Set up AWS Glue Studio.
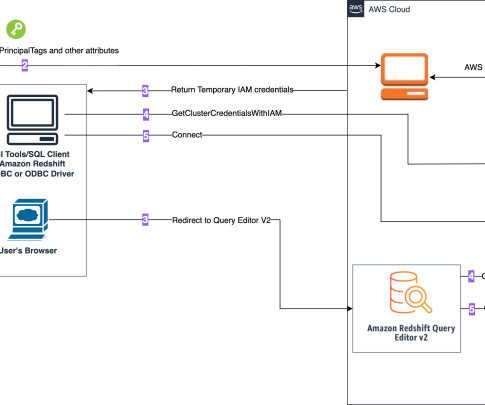
In this post, we discuss how to democratize data access to Amazon Redshift using the Amazon Redshift Query Editor V2. Background At AWS Payments, we had been using Redash to allow our users to author and run SQL queries against our Amazon Redshift datawarehouse.
This integration simplifies the authentication and authorization process for Amazon Redshift users using Query Editor V2 or Amazon Quicksight , making it easier for them to securely access your datawarehouse. Note: Your organization’s IdC instance must be in the same region as the Amazon Redshift datawarehouse you’re connecting to.
Amazon Redshift is a fully managed, petabyte-scale datawarehouse service in the cloud. Tens of thousands of customers use Amazon Redshift to process exabytes of data every day to power their analytics workloads. For more information, see ElectricityLoadDiagrams20112014 Data Set (Dua, D. and Karra Taniskidou, E.
As the queries finish running, an UNLOAD operation is invoked from the Redshift datawarehouse to the S3 bucket in Account A. The pipeline then starts running stored procedures and SQL commands on Redshift Serverless.
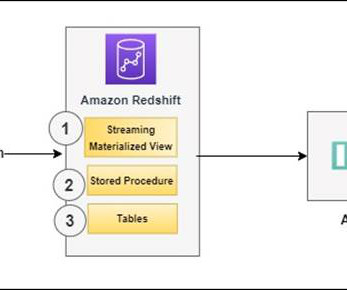
A CDC-based approach captures the data changes and makes them available in datawarehouses for further analytics in real-time. usually a datawarehouse) needs to reflect those changes in near real-time. This post showcases how to use streaming ingestion to bring data to Amazon Redshift.
As the volume and complexity of analytics workloads continue to grow, customers are looking for more efficient and cost-effective ways to ingest and analyse data. OpenSearch Service is used for multiple purposes, such as observability, search analytics, consolidation, cost savings, compliance, and integration.
Amazon Redshift Serverless makes it easy to run and scale analytics in seconds without the need to set up and manage datawarehouse clusters. Customers use their preferred SQL clients to analyze their data in Redshift Serverless. An Redshift Serverless datawarehouse. If you don’t have one, you can sign up for one.
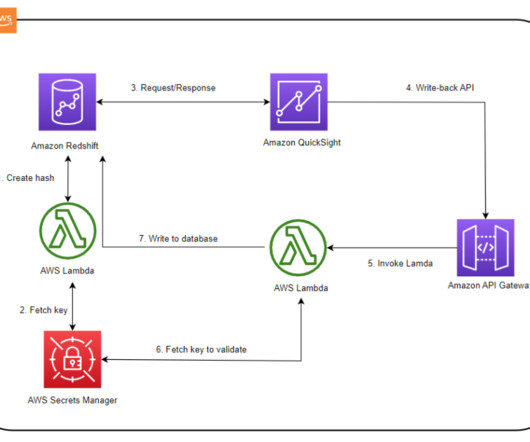
A write-back is the ability to update a data mart, datawarehouse, or any other database backend from within BI dashboards and analyze the updated data in near-real time within the dashboard itself. AnyCompany currently uses Amazon Redshift as their enterprise datawarehouse platform and QuickSight as their BI solution.
In fact, you may have even heard about IDC’s new Global DataSphere Forecast, 2021-2025 , which projects that global data production and replication will expand at a compound annual growth rate of 23% during the projection period, reaching 181 zettabytes in 2025. zettabytes of data in 2020, a tenfold increase from 6.5
This allows data that exists in cloud object storage to be easily combined with existing datawarehousedata without data movement. The advantage to NPS clients is that they can store infrequently used data in a cost-effective manner without having to move that data into a physical datawarehouse table.
He is passionate about helping customers build modern data architectures on the AWS Cloud. He has helped customers of all sizes implement data management, datawarehouse, and data lake solutions. Brian Dolan joined Amazon as a Military Relations Manager in 2012 after his first career as a Naval Aviator.
At the same time, they need to optimize operational costs to unlock the value of this data for timely insights and do so with a consistent performance. With this massive data growth, data proliferation across your data stores, datawarehouse, and data lakes can become equally challenging.
One of the bank’s key challenges related to strict cybersecurity requirements is to implement field level encryption for personally identifiable information (PII), Payment Card Industry (PCI), and data that is classified as high privacy risk (HPR). Only users with required permissions are allowed to access data in clear text.
Apache Spark enables you to build applications in a variety of languages, such as Java, Scala, and Python, by accessing the data in your Amazon Redshift datawarehouse. Amazon Redshift integration for Apache Spark helps developers seamlessly build and run Apache Spark applications on Amazon Redshift data.
Amazon Redshift is a fully managed, scalable cloud datawarehouse that accelerates your time to insights with fast, straightforward, and secure analytics at scale. Tens of thousands of customers rely on Amazon Redshift to analyze exabytes of data and run complex analytical queries, making it the most widely used cloud datawarehouse.
With the AWS Glue Salesforce connector, you can ingest and transform your CRM data to any of the AWS Glue supported destinations, including Amazon Simple Storage Service (Amazon S3), in your preferred format, including Apache Iceberg, Apache Hudi, and Linux Foundation Delta Lake; datawarehouses such as Amazon Redshift and Snowflake; and many more.
You might be modernizing your data architecture using Amazon Redshift to enable access to your data lake and data in your datawarehouse, and are looking for a centralized and scalable way to define and manage the data access based on IdP identities.
His background is in datawarehouse/data lake – architecture, development and administration. He is in data and analytical field for over 14 years. Ramesh Raghupathy is a Senior Data Architect with WWCO ProServe at AWS. He specializes in building and modernising analytical solutions.
Many customers run big data workloads such as extract, transform, and load (ETL) on Apache Hive to create a datawarehouse on Hadoop. Sandeep Singh is a Lead Consultant at AWS ProServe, focused on analytics, data lake architecture, and implementation. Amol Guldagad is a Data Analytics Consultant based in India.
These business units have varying landscapes, where a data lake is managed by Amazon Simple Storage Service (Amazon S3) and analytics workloads are run on Amazon Redshift , a fast, scalable, and fully managed cloud datawarehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data.
Amazon Redshift is a petabyte-scale, enterprise-grade cloud datawarehouse service delivering the best price-performance. Today, tens of thousands of customers run business-critical workloads on Amazon Redshift to cost-effectively and quickly analyze their data using standard SQL and existing business intelligence (BI) tools.
December 2012: Alation forms and goes to work creating the first enterprise data catalog. Later, in its inaugural report on data catalogs, Forrester Research recognizes that “Alation started the MLDC trend.”. Here’s a timeline view of what the market has said about Alation since our founding: Timeline: 10 Years of Alation.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content