This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Redshift is a fast, scalable, secure, and fully managed cloud datawarehouse that makes it simple and cost-effective to analyze your data using standard SQL and your existing business intelligence (BI) tools. Data ingestion is the process of getting data to Amazon Redshift.
Tens of thousands of customers use Amazon Redshift for modern data analytics at scale, delivering up to three times better price-performance and seven times better throughput than other cloud datawarehouses. To maintain the right level of access, the company wants to restrict data visibility based on the users role and region.
Business intelligence concepts refer to the usage of digital computing technologies in the form of datawarehouses, analytics and visualization with the aim of identifying and analyzing essential business-based data to generate new, actionable corporate insights. The datawarehouse. 1) The raw data.
Amazon Redshift is a fast, petabyte-scale, cloud datawarehouse that tens of thousands of customers rely on to power their analytics workloads. With its massively parallel processing (MPP) architecture and columnar data storage, Amazon Redshift delivers high price-performance for complex analytical queries against large datasets.
Amazon Redshift is a fully managed, petabyte-scale datawarehouse service in the cloud that delivers powerful and secure insights on all your data with the best price-performance. With Amazon Redshift, you can analyze your data to derive holistic insights about your business and your customers.
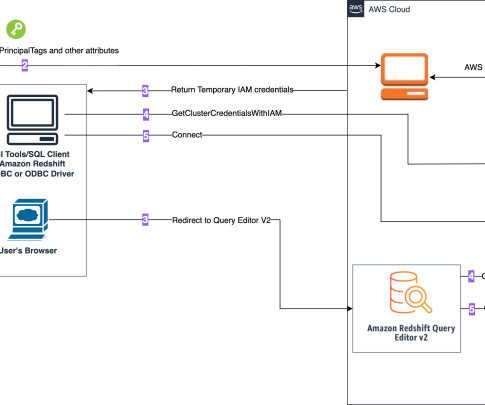
This integration simplifies the authentication and authorization process for Amazon Redshift users using Query Editor V2 or Amazon Quicksight , making it easier for them to securely access your datawarehouse. Note: Your organization’s IdC instance must be in the same region as the Amazon Redshift datawarehouse you’re connecting to.
Tens of thousands of customers rely on Amazon Redshift to analyze exabytes of data and run complex analytical queries. You can use your preferred SQL clients to analyze your data in an Amazon Redshift datawarehouse. He is passionate about automating and solving customer problems with cloud solutions.
Amazon Redshift Serverless makes it easy to run and scale analytics in seconds without the need to set up and manage datawarehouse clusters. Customers use their preferred SQL clients to analyze their data in Redshift Serverless. An Redshift Serverless datawarehouse. sales' : '', isMemberOfGroupName("finance") ?
You might be modernizing your data architecture using Amazon Redshift to enable access to your data lake and data in your datawarehouse, and are looking for a centralized and scalable way to define and manage the data access based on IdP identities. Choose Grant database. Choose Assign. Choose Assign.
Apache Spark enables you to build applications in a variety of languages, such as Java, Scala, and Python, by accessing the data in your Amazon Redshift datawarehouse. Amazon Redshift integration for Apache Spark helps developers seamlessly build and run Apache Spark applications on Amazon Redshift data.
These business units have varying landscapes, where a data lake is managed by Amazon Simple Storage Service (Amazon S3) and analytics workloads are run on Amazon Redshift , a fast, scalable, and fully managed cloud datawarehouse that allows you to process and run your complex SQL analytics workloads on structured and semi-structured data.
Amazon Redshift is a fully managed, petabyte-scale datawarehouse service in the cloud. Tens of thousands of customers use Amazon Redshift to process exabytes of data every day to power their analytics workloads. For more information, see ElectricityLoadDiagrams20112014 Data Set (Dua, D. and Karra Taniskidou, E.
One of the bank’s key challenges related to strict cybersecurity requirements is to implement field level encryption for personally identifiable information (PII), Payment Card Industry (PCI), and data that is classified as high privacy risk (HPR). Only users with required permissions are allowed to access data in clear text.
Founded in 2012, SumUp is the financial partner for more than 4 million small merchants in over 35 markets worldwide, helping them start, run and grow their business. Unless, of course, the rest of their data also resides in the Google Cloud. This is a guest blog post by Mira Daniels and Sean Whitfield from SumUp.
For this blog post, we create two folders: awssso-sales and awssso-finance , under a bucket named amzn-s3-demo-bucket. Use the following trust policy for the IAM role: { "Version": "2012-10-17", "Statement": [ { "Sid": "ForAccessGrants", "Effect": "Allow", "Principal": { "Service": "access-grants.s3.amazonaws.com"
SageMaker Lakehouse organizes data using logical containers called catalogs , enabling teams to seamlessly query and analyze data across their entire ecosystemfrom S3 data lakes to Amazon Redshift warehousesusing familiar Apache Iceberg compatible tools. We launched AWS Glue 5.0 with upgraded Apache Spark 3.5.4 and Python 3.11.
Traditionally, answering this question would involve multiple data exports, complex extract, transform, and load (ETL) processes, and careful data synchronization across systems. The existing Data Catalog becomes the Default catalog (identified by the AWS account number) and is readily available in SageMaker Lakehouse.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content