This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Under the hood, UniForm generates Iceberg metadata files (including metadata and manifest files) that are required for Iceberg clients to access the underlying data files in Delta Lake tables. Both Delta Lake and Iceberg metadata files reference the same data files. The table is registered in AWS Glue Data Catalog.
For example, you can use metadata about the Kinesis data stream name to index by data stream ( ${getMetadata("kinesis_stream_name") ), or you can use document fields to index data depending on the CloudWatch log group or other document data ( ${path/to/field/in/document} ).
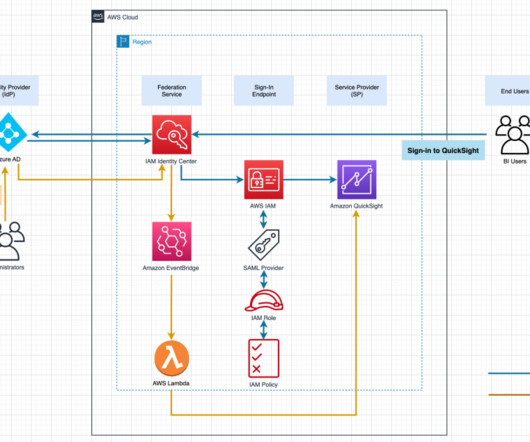
Save the federation metadata XML file You use the federation metadata file to configure the IAM IdP in a later step. In the Single sign-on section , under SAML Certificates , choose Download for Federation Metadata XML. Complete the following steps to download the file: Navigate back to your SAML-based sign-in page.
Migration of metadata such as security roles and dashboard objects will be covered in another subsequent post. For index , you can leave it as default, which will get the metadata from the source index and write to the same name in the destination as of the sources.
In the trust policy, specify that Amazon Elastic Compute Cloud (Amazon EC2) can assume this role: { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "ec2.amazonaws.com" amazonaws.com" }, "Action": "sts:AssumeRole" } ] } Make a note of the role ARN.
With the ability to browse metadata, you can understand the structure and schema of the data source, identify relevant tables and fields, and discover useful data assets you may not be aware of. This approach simplifies your data journey and helps you meet your security requirements. Choose the created IAM role.
Consider deep learning, a specific form of machine learning that resurfaced in 2011/2012 due to record-setting models in speech and computer vision. Metadata and artifacts needed for audits. Use ML to unlock new data types—e.g., images, audio, video. Tackle completely new use cases and applications.
Iceberg tables maintain metadata to abstract large collections of files, providing data management features including time travel, rollback, data compaction, and full schema evolution, reducing management overhead. Snowflake writes Iceberg tables to Amazon S3 and updates metadata automatically with every transaction.
Organizations have multiple Hive data warehouses across EMR clusters, where the metadata gets generated. The onboarding of producers is facilitated by sharing metadata, whereas the onboarding of consumers is based on granting permission to access this metadata. compute.internal ). Choose Submit job run.
Add this policy to the AWS Glue role and Amazon MWAA role: { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:PutObject", "s3:PutObjectAcl" ], "Resource": "arn:aws:s3:::sample-inp-bucket-etl- /*" } ] } In Account B, create the IAM policy policy_for_roleB specifying Account A as a trusted entity.
The metadata document from your IdP. To download it, refer to Federation Metadata Explorer. For Metadata document , upload the metadata document you downloaded as a prerequisite. For Federation metadata address , enter [link]. An AD user with permissions to manage AD FS and AD group membership. Choose Add provider.
This populates the technical metadata in the business data catalog for each data asset. The business metadata, can be added by business users to provide business context, tags, and data classification for the datasets. If new AWS Glue tables or metadata is created or updated, then it starts the data source sync job.
The objective is to create views in the Data Catalog so you can create a single common view schema and metadata object to use across engines (in this case, Athena). Solution overview For this post, we use the Women’s E-Commerce Clothing Review. Doing so lets you use the same views across your data lakes to fit your use case.
We split the solution into two primary components: generating Spark job metadata and running the SQL on Amazon EMR. The first component (metadata setup) consumes existing Hive job configurations and generates metadata such as number of parameters, number of actions (steps), and file formats. sql_path SQL file name.
. // It serves as a simple API Gateway to Kafka Proxy, accepting requests and forwarding them to a Kafka topic. withBody("Message successfully pushed to kafka"); } catch (Exception e) { // In case of exception, log the error message and return a 500 status code log.error(e.getMessage(), e); return response.withBody(e.getMessage()).withStatusCode(500);
After the table is cataloged in your AWS Glue metadata catalog, you can run queries directly on your data in your S3 data lake through OpenSearch Dashboards. You can audit connections to ensure that they are set up in a scalable, cost-efficient, and secure way. Solution overview The following diagram illustrates the solution architecture.
With Lake Formation, you can manage access control for your data lake data in Amazon Simple Storage Service (Amazon S3 ) and its metadata in AWS Glue Data Catalog in one place with familiar database-style features. AWS Lake Formation helps you centrally govern, secure, and globally share data for analytics and machine learning.
The Data Catalog provides metadata that allows analytics applications using Athena to find, read, and process the location data stored in Amazon S3. The crawlers will automatically classify the data into JSON format, group the records into tables and partitions, and commit associated metadata to the AWS Glue Data Catalog. Choose Run.
int '2' 'InstanceType': 'Ref': 'ClusterInstanceType' 'Market': 'ON_DEMAND' 'Name': 'Core' 'Outputs': 'ClusterId': 'Value': 'Ref': 'EmrCluster' 'Description': 'The ID of the EMR cluster' 'Metadata': 'AWS::CloudFormation::Designer': {} 'Rules': {} Trusted identity propagation is supported from Amazon EMR 6.15
With Lake Formation, you can centralize data security and governance using the AWS Glue Data Catalog , letting you manage metadata and data permissions in one place with familiar database-style features. glue:GetUnfilteredTableMetadata – Allows a third-party analytical engine to retrieve unfiltered table metadata from the Data Catalog.
The IdP metadata is displayed. In the SAML Certificates section, download the Federation Metadata XML file and the Certificate (Raw) file. For IdP SAML metadata under the Identity provider metadata section, choose Choose file. Choose the previously downloaded metadata file ( IIC-QuickSight.xml ). Choose Save.
Download the SAML metadata file. In the navigation pane under Clients , import the SAML metadata file. Download the Keycloak IdP SAML metadata file from that URL location. For Metadata document , upload the Keycloak IdP SAML metadata XML file you downloaded and saved to your local machine earlier. Choose Browse.
December 2012: Alation forms and goes to work creating the first enterprise data catalog. August 2017: Alation debuts as a leader in the Gartner MQ for Metadata Management Solutions. August 2018: Gartner names Alation a 2X Leader in the MQ for Metadata Management Solutions. June 2017: Yahoo Japan Corp.
By selecting the corresponding asset, you can understand its content through the readme, glossary terms , and technical and business metadata. We use this data source to import metadata information related to our datasets. Use Amazon DataZone APIs through Boto3 to push custom data quality metadata.
Amazon SQS receives an Amazon S3 event notification as a JSON file with metadata such as the S3 bucket name, object key, and timestamp. The OpenSearch Ingestion pipeline receives the message from Amazon SQS, loads the files from Amazon S3, and parses the CSV data from the message into columns.
Eliminating dependency on business units – Redshift Spectrum uses a metadata layer to directly query the data residing in S3 data lakes, eliminating the need for data copying or relying on individual business units to initiate the copy jobs. Similarly, individual business units produce their own domain-specific data.
Data as a product Treating data as a product entails three key components: the data itself, the metadata, and the associated code and infrastructure. For orchestration, they use the AWS Cloud Development Kit (AWS CDK) for infrastructure as code (IaC) and AWS Glue Data Catalogs for metadata management.
Use the IdP metadata in block 4 and save the metadata file in.xml format (for example, metadata.xml ). Choose Choose file and upload the metadata file (.xml) Collect Okta information To gather your Okta information, complete the following steps: On the Sign On tab, choose View SAML setup instructions. Choose Add provider.
That’s a lot of priorities – especially when you group together closely related items such as data lineage and metadata management which rank nearby. DG emerges for the big data side of the world, e.g., the Alation launch in 2012. Allows metadata repositories to share and exchange. That would’ve been heresy in earlier years.
To analyze XML files stored in Amazon S3 using AWS Glue and Athena, we complete the following high-level steps: Create an AWS Glue crawler to extract XML metadata and create a table in the AWS Glue Data Catalog. We use the AWS Glue crawler to extract XML file metadata. We also use a custom XML classifier in this solution.
In 2013 I joined American Family Insurance as a metadata analyst. I had always been fascinated by how people find, organize, and access information, so a metadata management role after school was a natural choice. The use cases for metadata are boundless, offering opportunities for innovation in every sector. The data scientist.
Member account 2 (Glue_Member_Account) is where metadata is cataloged in the Data Catalog and Lake Formation is enabled with IAM Identity Center integration. Member account 2 (Glue_Member_Account) where metadata is cataloged in the Data Catalog. We integrate users and groups from the IdP with IAM Identity Center.
ORDERTOPIC" WHERE CAN_JSON_PARSE(kafka_value); The metadata column kafka_value that arrives from Amazon MSK is stored in VARBYTE format in Amazon Redshift. For this post, you use the JSON_PARSE function to convert kafka_value to a SUPER data type.
Use case 3: Amazon S3 file uploads In addition to the download functionality, users often need to retain and attach metadata to new versions of files. For example, when you download a file, you can perform data changes, enrichment, or analysis on the file, and then upload the updated version back to the Amazon DataZone portal.
An AWS Glue Crawler scans the above files and catalogs metadata about them into the AWS Glue Data Catalog. Select Create database , as shown in the following screenshot. Repeat the steps for creating other database like lobmarket and hr.
An example is provided below ocsf-cuid-${/class_uid}-${/metadata/product/name}-${/class_name}-%{yyyy.MM.dd} Complete the following steps to install the index templates and dashboards for your data: Download the component_templates.zip and index_templates.zip files and unzip them on your local device. Set region as us-east-1.
The gist is, leveraging metadata about research datasets, projects, publications, etc., Once upon a time, circa 2012-ish, data science conferences were replete with talks about an industry hellbent on loading amazing enormous Big Data into some kind of data lake, and applying all kinds of odd astrophysics-ish approaches…for eventual PROFIT!
After you finish entering the required cluster metadata and create the resource, you can check the status for IdC integration in the properties. Note that when a new data warehouse is created, the IAM role specified for IdC integration is automatically attached to the provisioned cluster or Serverless Namespace.
Let’s analyze text data from the party conventions during the 2012 US Presidential elections. metadata=convention_df["speaker"]? ). Here’s an interactive visualization for understanding texts: scattertext , a product of the genius of Jason Kessler. get_data(). ? category="democrat",?. width_in_pixels=1000,?.
I recall a “Data Drinkup Group” gathering at a pub in Palo Alto, circa 2012, where I overheard Pete Skomoroch talking with other data scientists about Kahneman’s work. Rather, they were beaming about Kahneman’s work and its significance in our field.
Metadata can play a very important role in using data assets to make data driven decisions. Generating metadata for your data assets is often a time-consuming and manual task. This post shows you how to enrich your AWS Glue Data Catalog with dynamic metadata using foundation models (FMs) on Amazon Bedrock and your data documentation.
Founded in 2012, SumUp is the financial partner for more than 4 million small merchants in over 35 markets worldwide, helping them start, run and grow their business. Data Catalog: We also wanted to automate a Glue Crawler to have metadata in a Data Catalog and be able to explore our files in S3 with Athena.
When the IdP is created in the previous step, an event is added in an Amazon Simple Notification Service (Amazon SNS) topic with its details, such as name and SAML metadata. In the NNEDH control plane, a Lambda job is triggered by new events on this SNS topic.
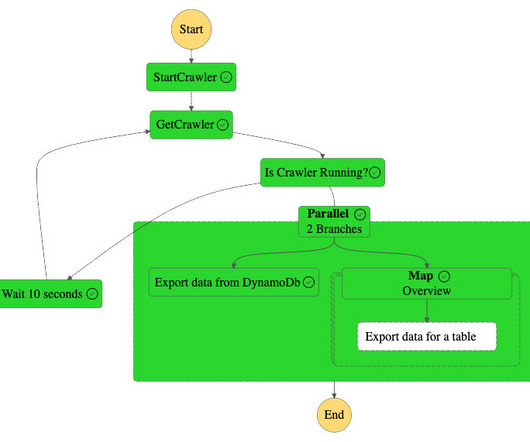
Amazon S3 hosts the metadata of all the tables as a.csv file. The pipeline uses the Step Functions distributed map to read the table metadata from Amazon S3, iterate on every single item, and call the downstream AWS Glue job in parallel to export the data. The following diagram illustrates the Step Functions workflow.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content