

How Volkswagen streamlined access to data across multiple data lakes using Amazon DataZone – Part 1
AWS Big Data
JULY 18, 2024
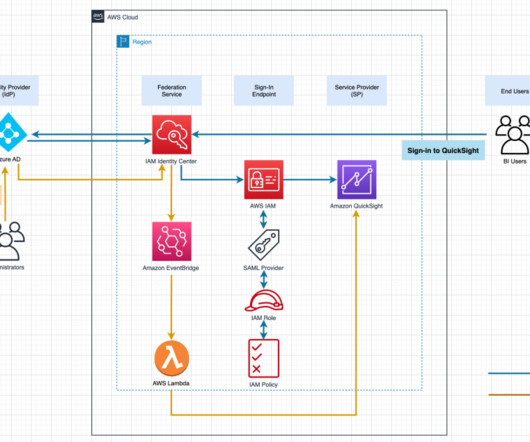
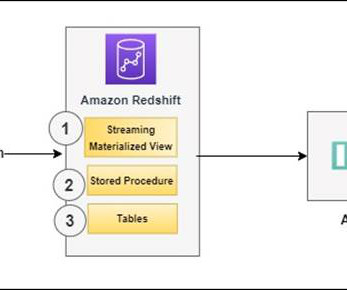
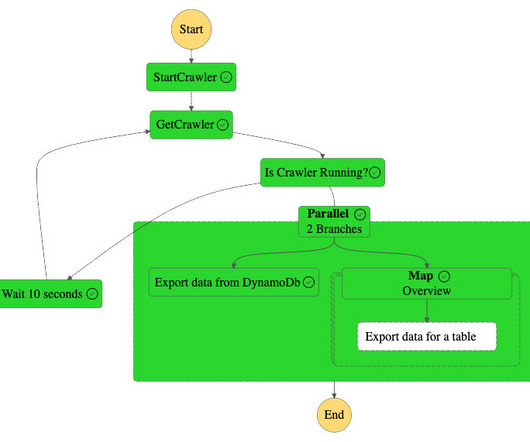
This populates the technical metadata in the business data catalog for each data asset. The business metadata, can be added by business users to provide business context, tags, and data classification for the datasets. If new AWS Glue tables or metadata is created or updated, then it starts the data source sync job.





























Let's personalize your content