This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
OpenSearch Service stores different types of stored objects, such as dashboards, visualizations, alerts, security roles, index templates, and more, within the domain. As your user base and number of Amazon OpenSearch Service domains grow, tracking activities and changes to those saved objects becomes increasingly difficult.
With the ability to browse metadata, you can understand the structure and schema of the data source, identify relevant tables and fields, and discover useful data assets you may not be aware of. You can navigate to the projects Data page to visually verify the existence of the newly created table. Under Create job , choose Visual ETL.
The Query Editor V2 offers a user-friendly interface for connecting to your Redshift clusters, executing queries, and visualizing results. Save the federation metadata XML file You use the federation metadata file to configure the IAM IdP in a later step. Save this file locally. Choose Add provider. Choose Add provider.
Iceberg tables maintain metadata to abstract large collections of files, providing data management features including time travel, rollback, data compaction, and full schema evolution, reducing management overhead. You can use this same integration to take advantage of the data sharing and collaboration capabilities in Snowflake.
A common use case that we see amongst customers is to search and visualize data. In this post, we show how to ingest CSV files from Amazon Simple Storage Service (Amazon S3) into Amazon OpenSearch Service using the Amazon OpenSearch Ingestion feature and visualize the ingested data using OpenSearch Dashboards.
Add this policy to the AWS Glue role and Amazon MWAA role: { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:PutObject", "s3:PutObjectAcl" ], "Resource": "arn:aws:s3:::sample-inp-bucket-etl- /*" } ] } In Account B, create the IAM policy policy_for_roleB specifying Account A as a trusted entity.
With OpenSearch Ingestion, you can filter, enrich, transform, and deliver your data for downstream analysis and visualization. You can now analyze infrequently queried data in cloud object stores and simultaneously use the operational analytics and visualization capabilities of OpenSearch Service.
We discuss how to visualize data quality scores in Amazon DataZone, enable AWS Glue Data Quality when creating a new Amazon DataZone data source, and enable data quality for an existing data asset. If the asset has AWS Glue Data Quality enabled, you can now quickly visualize the data quality score directly in the catalog search pane.
The Data Catalog provides metadata that allows analytics applications using Athena to find, read, and process the location data stored in Amazon S3. Visual layouts in some screenshots in this post may look different than those on your AWS Management Console. The following code is the input paths map: { EventType: $.detail.EventType
Solution overview We explore two distinct techniques that can streamline your XML file processing workflow: Technique 1: Use an AWS Glue crawler and the AWS Glue visual editor – You can use the AWS Glue user interface in conjunction with a crawler to define the table structure for your XML files. Choose Create.
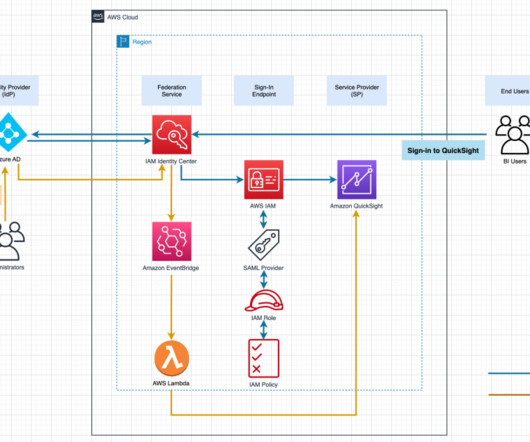
The IdP metadata is displayed. In the SAML Certificates section, download the Federation Metadata XML file and the Certificate (Raw) file. For IdP SAML metadata under the Identity provider metadata section, choose Choose file. Choose the previously downloaded metadata file ( IIC-QuickSight.xml ). Choose Save.
Next let’s use the displaCy library to visualize the parse tree for that sentence: In [4]: from spacy import displacy?? The displaCy library provides an excellent way to visualize named entities: In [15]: displacy.render(doc, style="ent"). metadata=convention_df["speaker"]? ). part of speech. Cupertino GPE?
That’s a lot of priorities – especially when you group together closely related items such as data lineage and metadata management which rank nearby. DG emerges for the big data side of the world, e.g., the Alation launch in 2012. Allows metadata repositories to share and exchange. That would’ve been heresy in earlier years.
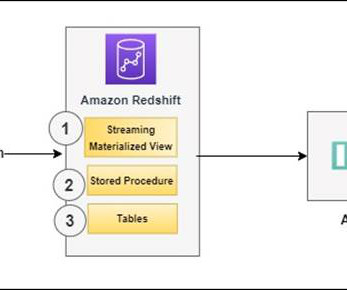
Establish connectivity between an Amazon QuickSight dashboard and Amazon Redshift to deliver visualization and insights. ORDERTOPIC" WHERE CAN_JSON_PARSE(kafka_value); The metadata column kafka_value that arrives from Amazon MSK is stored in VARBYTE format in Amazon Redshift.
An example is provided below ocsf-cuid-${/class_uid}-${/metadata/product/name}-${/class_name}-%{yyyy.MM.dd} Complete the following steps to install the index templates and dashboards for your data: Download the component_templates.zip and index_templates.zip files and unzip them on your local device.
He’s been out of Wolfram for a while and writing exquisite science books including Elements: A Visual Explanation of Every Known Atom in the Universe and Molecules: The Architecture of Everything. The gist is, leveraging metadata about research datasets, projects, publications, etc., Rinse, lather, repeat—probably each week.
Her talk addressed career paths for people in data science going into specialized roles, such as data visualization engineers, algorithm engineers, and so on. I recall a “Data Drinkup Group” gathering at a pub in Palo Alto, circa 2012, where I overheard Pete Skomoroch talking with other data scientists about Kahneman’s work.
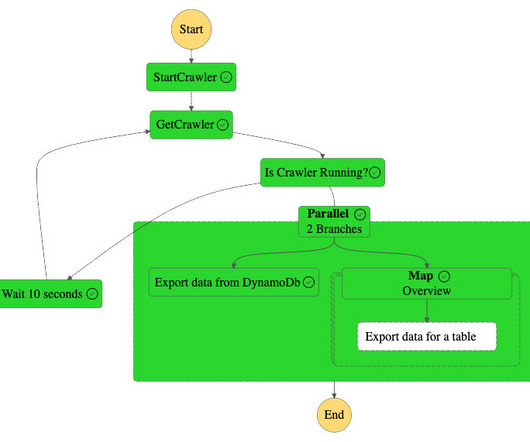
AWS Step Functions is a fully managed visual workflow service that enables you to build complex data processing pipelines involving a diverse set of extract, transform, and load (ETL) technologies such as AWS Glue , Amazon EMR , and Amazon Redshift. Amazon S3 hosts the metadata of all the tables as a.csv file.
To provide some coherence to the music, I decided to use Taylor Swift songs since her discography covers the time span of most papers that I typically read: Her main albums were released in 2006, 2008, 2010, 2012, 2014, 2017, 2019, 2020, and 2022. This choice also inspired me to call my project Swift Papers.
He also really informed a lot of the early thinking about data visualization. It involved a lot of work with applied math, some depth in statistics and visualization, and also a lot of communication skills. He was saying this doesn’t belong just in statistics. But the point there was what was emerging was interdisciplinary.
The solution can be visually represented in the following diagram. An S3 bucket to host the sample Iceberg table data and metadata. The ETL application will use IAM role-based access to the Iceberg table, and the data analyst gets Lake Formation permissions to query the same tables.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content