This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Redshift provides performance metrics and data so you can track the health and performance of your provisioned clusters, serverless workgroups, and databases. This feature is part of the Amazon Redshift console and provides a visual and graphical representation of the query’s run order, execution plan, and various statistics.
In fact, a Digital Universe study found that the total data supply in 2012 was 2.8 More often than not, it involves the use of statistical modeling such as standard deviation, mean and median. Let’s quickly review the most common statistical terms: Mean: a mean represents a numerical average for a set of responses.
For those embarking on a journey to master the art of the ‘R’ language – a statistical computing program and framework for increased business intelligence-based success – Advanced R is intuitive, easy to follow, and will give you a well-rounded overview of this invaluable area of data science.
The company’s business analysts want to generate metrics to identify ticket movement over time, success rates for sellers, and the best-selling events, venues, and seasons. They would like to get these metrics in near-real time using a zero-ETL integration. or higher version) database. source) and Amazon Redshift (destination).
Bonus One: Read: Brand Measurement: Analytics & Metrics for Branding Campaigns ]. There are many different tools, both online and offline, that measure the elusive metric called brand strength. They are full of specific insights you can use to optimize your online search campaigns.
Create a role in the target account with the following permissions: { "Version":"2012-10-17", "Statement":[ { "Effect":"Allow", "Action":[ "redshift:DescribeClusters", "redshift-serverless:ListNamespaces" ], "Resource":[ "*" ] } ] } The role must have the following trust policy, which specifies the target account ID.
Of course, any mistakes by the reviewers would propagate to the accuracy of the metrics, and the metrics calculation should take into account human errors. If we could separate bad videos from good videos perfectly, we could simply calculate the metrics directly without sampling. The missing verdicts create two problems.
The company’s business analysts want to generate metrics to identify ticket movement over time, success rates for sellers, and the best-selling events, venues, and seasons. They would like to get these metrics in near real time using a zero-ETL integration. Choose Create policy.
AWS Glue Data Quality reduces the effort required to validate data from days to hours, and provides computing recommendations, statistics, and insights about the resources required to run data validation. Create and attach a new inline policy ( AWSGlueDataQualityBucketPolicy ) with the following content.
In contrast, the decision tree classifies observations based on attribute splits learned from the statistical properties of the training data. Machine Learning-based detection – using statistical learning is another approach that is gaining popularity, mostly because it is less laborious. from sklearn import metrics.
the weight given to Likes in our video recommendation algorithm) while $Y$ is a vector of outcome measures such as different metrics of user experience (e.g., Experiments, Parameters and Models At Youtube, the relationships between system parameters and metrics often seem simple — straight-line models sometimes fit our data well.
Many organizations already use AWS Glue Data Quality to define and enforce data quality rules on their data, validate data against predefined rules , track data quality metrics, and monitor data quality over time using artificial intelligence (AI). The metrics are saved in Amazon S3 to have a persistent output. onData(df).useRepository(metricsRepository).addCheck(
He outlined how critical measurable results are to help VCs make major investment decisions — metrics such as revenue, net vs gross earnings, sales , costs and projections, and more. From a startup in 2012, it is now valued at $3.2 The company has integrated data analysis throughout its organization to power decision making.
and implications of findings) than in statistical significance. I first learned about this technique through Cole Nussbaumer’s Storytelling with Data workshop back in 2012—but geez, was it tough to apply! Dashboards provide key metrics about a program, department, or organization, usually at regular intervals over time (e.g.,
Identification We now discuss formally the statistical problem of causal inference. We start by describing the problem using standard statistical notation. The field of statistical machine learning provides a solution to this problem, allowing exploration of larger spaces. For a random sample of units, indexed by $i = 1.
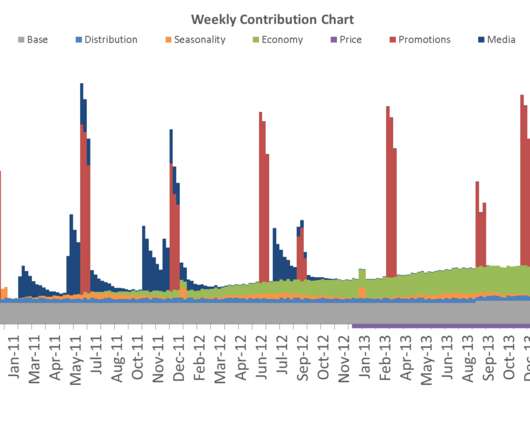
MMM stands for Marketing Mix Model and it is one of the oldest and most well-established techniques to measure the sales impact of marketing activity statistically. As with any type of statistical model, data is key and GIGO (“Garbage In, Garbage Out”) principle definitely applies. What is MMM? Data Requirements.
This means it is possible to specify exactly in which geos an ad campaign will be served – and to observe the ad spend and the response metric at the geo level. In other words, iROAS is the slope of a curve of the response metric plotted against the underlying advertising spend. They are non-overlapping geo-targetable regions.
What metrics are used to evaluate success? While image data has been the stalwart for deep learning use cases since the proverbial “ AlexNet moment ” in 2011-2012, and a renaissance in NLP over the past 2-3 years has accelerated emphasis on text use cases, we note that structured data is at the top of the list in enterprise.
Without a doubt, the best way to drive maximum value from the metrics, insights, and information is through something called data discovery. Studies say that more data has been generated in the last two years than in the entire history before and that since 2012 the industry has created around 13 million jobs around the world.
1]" Statistics, as a discipline, was largely developed in a small data world. With more features come more potential post hoc hypotheses about what is driving metrics of interest, and more opportunity for exploratory analysis. Data was expensive to gather, and therefore decisions to collect data were generally well-considered.
Second, between 2012 and 2013. You are comparing 2012 and 2013, add a row of data at the top that shows your computation of the size of the opportunity for 2014. conversion rate (it might not be statistically significant!). Despite that, I bet it was still harder than necessary for you to figure out what is going on.
He was saying this doesn’t belong just in statistics. It involved a lot of work with applied math, some depth in statistics and visualization, and also a lot of communication skills. I went to a meeting at Starbucks with the founder of Alation right before they launched in 2012, drawing on the proverbial back-of-the-napkin.
Metrics and statistics are wonderful, but we need to surround data with more context and lower the costs of using data. Rather than focusing on making data consumers do more work, maybe we can boost literacy by surrounding the data with context and reducing the burden of understanding the information.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content