This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
According to a study conducted by IBM in 2012, companies that perform well tend to innovate their business models quite frequently, compared to underperformers. Failing to adjust one’s business model to suit the ever-dynamic business environment can threaten and diminish the longevity of any business.
According to a study conducted by IBM in 2012, companies that perform well tend to innovate their business models quite frequently, compared to underperformers. Failing to adjust one’s business model to suit the ever-dynamic business environment can threaten and diminish the longevity of any business.
for BI data model development. For several years, Visual Studio has been my go-to tool for designing semantic data models used for Business Intelligent reporting. In 2012 when Microsoft began the transition from on-disk cubes to in-memory SSAS Tabular models, I used SQL Server Data Tools (SSDT) to create tabular models.
Stage 2: Machine learning models Hadoop could kind of do ML, thanks to third-party tools. While data scientists were no longer handling Hadoop-sized workloads, they were trying to build predictive models on a different kind of “large” dataset: so-called “unstructured data.” And it was good.
With the number of available data science roles increasing by a staggering 650% since 2012, organizations are clearly looking for professionals who have the right combination of computer science, modeling, mathematics, and business skills. Demand for data scientists is surging.
Fauna was founded in 2012 by software infrastructure engineers Evan Weaver and Matt Freels to develop the cloud-native transactional database product they would have liked to have had at their disposal in their former roles at what was then known as Twitter (now X). Fauna describes its product as a document-relational database.
Companies successfully adopt machine learning either by building on existing data products and services, or by modernizing existing models and algorithms. For example, in a July 2018 survey that drew more than 11,000 respondents, we found strong engagement among companies: 51% stated they already had machine learning models in production.
. “In computer vision, for example, starting in 2012, those models were essentially open sourced, so a lot of businesses then got into the business of applying those computer vision models for specific use cases, like autonomous tracking vehicles. Then you have pre-trained models you can do transfer learning with.
Large language models have allowed BI providers to accelerate the delivery of functionality to convert natural language questions into analytic queries and generate summarizations and recommendations from data and charts.
While there is an ongoing need for data platforms to support data warehousing workloads involving analytic reports and dashboards, there is increasing demand for analytic data platform providers to add dedicated functionality for data engineering, including the development, training and tuning of machine learning (ML) and GenAI models.
Back in 2012, Harvard Business Review called data scientists “the sexiest job of the 21st century.” For one, odds are not in their favor with >90% of AI executives claiming to have problems with model development and deployment. It’s a difficult job for a number of reasons. It’s a difficult job for a number of reasons.
The company had offered a freemium model in contrast to MixPanel’s paid service, helping it not only rake up customers but also attract new investors. . The company, which was founded by Spenser Saktes and Curtis Liu in 2012, has raised a total of $336 million with the latest Series F round closing at $150 million in 2021.
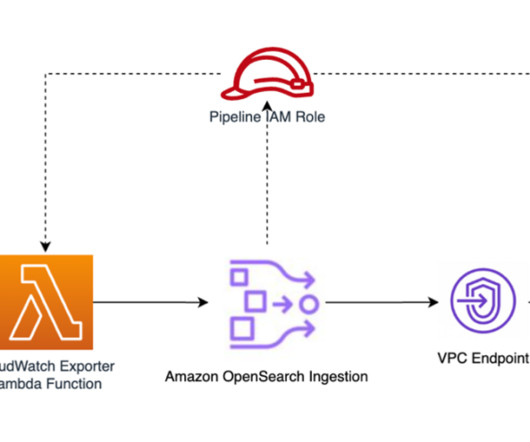
Select Custom trust policy and paste the following policy into the editor: { "Version":"2012-10-17", "Statement":[ { "Effect":"Allow", "Principal":{ "Service":"osis-pipelines.amazonaws.com" }, "Action":"sts:AssumeRole" } ] } Choose Next, and then search for and select the collection-pipeline-policy you just created.
The Dawn of Telco Big Data: 2007-2012. Suddenly, it was possible to build a data model of the network and create both a historical and predictive view of its behaviour. The Explosion in Telco Big Data: 2012-2017. Let’s examine how we got here. Data governance was completely balkanized, if it existed at all.
This framework acts in a provider-subscriber model to enable data transfers between SAP systems and non-SAP data targets. AWS Glue is a serverless data integration service that makes it easier to discover, prepare, move, and integrate data from multiple sources for analytics, machine learning (ML), and application development.
In fact, a Digital Universe study found that the total data supply in 2012 was 2.8 More often than not, it involves the use of statistical modeling such as standard deviation, mean and median. Prior to 2012, Intel would conduct over 19,000 manufacturing function tests on their chips before they could be deemed acceptable for release.
There’s recognition that it’s nearly impossible to find the unicorn data scientist that was the apple of every CEO’s eye in 2012. In addition to the UI interface, Cloudera Machine Learning exposes a REST API that can be used to programmatically perform operations related to Projects, Jobs, Models, and Applications.
Last March, IFS launched a new, cloud-native version of its suite of ERP applications with significant extensions for field service management (FSM) and enterprise asset management (EAM), all based on the same data model via its IFS Cloud platform.
Consumer personas – Consumers include data analysts who run queries on the data lake, data scientists who prepare data for machine learning (ML) models and conduct exploratory analysis, as well as downstream systems that run batch jobs on the data within the data lake. compute.internal ). Choose Grant. Choose Submit job run.
In 2012, DataRobot co-founders Jeremy Achin and Tom de Godoy recognized the profound impact that AI and machine learning could have on organizations, but that there wouldn’t be enough data scientists to meet the demand.
The company had offered a freemium model in contrast to MixPanel’s paid service, helping it not only rake up customers but also attract new investors. . The company, which was founded by Spenser Saktes and Curtis Liu in 2012, has raised a total of $336 million with the latest Series F round closing at $150 million in 2021.
While training a model for NLP, words not present in the training data commonly appear in the test data. Using the semantic meaning of words it already knows as a base, the model can understand the meanings of words it doesn’t know that appear in test data. Amit Bendov was appointed CEO in July 2012.
Multi-channel attribution was the flavor of the month for every month in 2012. And just as in 2012 magic pills will be scarce, FUD will be plentiful, and vendors will promise the moon. After that if you can't resist the itch, go play with the, now free to everyone, Attribution Modeling Tool in GA. Mobile Devices Report.
I got my first data science job in 2012, the year Harvard Business Review announced data scientist to be the sexiest job of the 21st century. As I was wrapping up my PhD in 2012, I started thinking about my next steps. Things have changed considerably since 2012. What do I actually do here?
Some of these ‘structures’ may include putting all the information; for instance, a structure could be about cars, placing them into tables that consist of makes, models, year of manufacture, and color. This piece, published in 2012, offers a step-to-step guide on everything related to SQL.
Making this belief a reality at Insight In 2012, Insight created a new model for professional education to bridge this gap. Beyond our tuition-free model, we offer need-based scholarships to help cover expenses like transportation and housing. We’re truly committed to supporting our Fellows?—?we
Amazon Redshift ML makes it easy for data analysts and database developers to create, train, and apply machine learning (ML) models using familiar SQL commands in Amazon Redshift. Simply use SQL statements to create and train SageMaker ML models using your Redshift data and then use these models to make predictions.
You can add AD users to the respective groups based on your business permissions model. Users in Active Directory can subsequently be added to the groups, providing the ability to assume access to the corresponding roles in AWS. Note that each user must have an email address configured in Active Directory.
My story seems to reflect that: From my first steps in sentiment analysis and topic modelling, through building recommender systems while dabbling in Kaggle competitions and deep learning a few years ago, and to my present-day interest in causal inference. Moving forward in my PhD, I got into topic modelling.
In the Create function pane, provide the following information: For Select a template , choose v2 Programming Model. For Programming Model , choose the HTTP trigger template. In the function app, choose Overview , then choose Create function in the Functions section. choose Next. Choose Create policy.
In 2012, COBIT 5 was released and in 2013, the ISACA released an add-on to COBIT 5, which included more information for businesses regarding risk management and information governance. COBIT 2019 Framework: Governance and management objectives: A companion guide that dives into the COBIT Core Model and 40 governance and management objectives.
Create a role in the target account with the following permissions: { "Version":"2012-10-17", "Statement":[ { "Effect":"Allow", "Action":[ "redshift:DescribeClusters", "redshift-serverless:ListNamespaces" ], "Resource":[ "*" ] } ] } The role must have the following trust policy, which specifies the target account ID. Choose Create policy.
Derek Driggs, a machine learning researcher at the University of Cambridge, together with his colleagues, published a paper in Nature Machine Intelligence that explored the use of deep learning models for diagnosing the virus. The paper determined the technique not fit for clinical use. Target analytics violated privacy.
Migrating all use cases from one permissions model to another in a single step without disruption was challenging for operations teams. To ease the transition of data lake permissions from an IAM and S3 model to Lake Formation, we’re introducing a hybrid access mode for AWS Glue Data Catalog.
In other words, structured data has a pre-defined data model , whereas unstructured data doesn’t. . It facilitates AI because, to be useful, many AI models require large amounts of data for training. There is a plethora of efforts to produce models that can learn without labels or with few labels. The challenges of data.
SSRS is a server-based reporting platform that comes free with SQL Server 2012. It is widely used for modeling and structuring of unshaped data. Migrating SSRS 2012/2014/2016 to Power BI is fine. Two popular options for reporting platforms are SQL Server Reporting Services (SSRS) and Microsoft Power BI. Replacing the server.
This is opening up new revenue opportunities, use cases and even the possibility for different types of business models within the sector, changing the way that CSPs operate. . In many established markets, traditional sources of revenue are either plateauing or declining relatively rapidly. .
For example, IDC data shows that 2021 there was a boom in monitor sales, with the highest volume of monitors shipped since 2012, at 143.6 However, a technology upgrade should be on the cards too, because over the past few years, many employees have effectively upgraded their home spaces, and now employees need to do the same in the office.
For example, IDC data shows that 2021 there was a boom in monitor sales, with the highest volume of monitors shipped since 2012, at 143.6 However, a technology upgrade should be on the cards too, because over the past few years, many employees have effectively upgraded their home spaces, and now employees need to do the same in the office.
One of the most common ways of fitting time series models is to use either autoregressive (AR), moving average (MA) or both (ARMA). These models are well represented in R and are fairly easy to work with. AR models can be thought of as linear regressions of the current value of the time series against previous values.
The PostgreSQL resource model allows you to create multiple databases within a cluster. The newly created Aurora PostgreSQL cluster will be the source for the zero-ETL integration. The next step is to create a named database in Amazon Aurora PostgreSQL for the zero-ETL integration.
zettabytes in 2012. Reports and models stutter as they try to interpret the massive amounts of data flowing through them. It may conflict with your data governance policy (more on that below), but it may be valuable in establishing a broader view of the data and directing you toward better data sets for your main models.
Statistics developed in the last century are based on probability models (distributions). This model for data analytics has proven highly successful in basic biomedical research and clinical trials. The accuracy of any predictive model approaches 100%. Property 4: The accuracy of any predictive model approaches 100%.
We had data science leaders presenting about lessons learned while leading data science teams, covering key aspects including scalability, being model-driven, being model-informed, and how to shape the company culture effectively. Data science leadership: importance of being model-driven and model-informed.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content