This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In fact, a Digital Universe study found that the total data supply in 2012 was 2.8 More often than not, it involves the use of statistical modeling such as standard deviation, mean and median. Let’s quickly review the most common statistical terms: Mean: a mean represents a numerical average for a set of responses.
Consider deep learning, a specific form of machine learning that resurfaced in 2011/2012 due to record-setting models in speech and computer vision. A catalog or a database that lists models, including when they were tested, trained, and deployed. Use ML to unlock new data types—e.g., images, audio, video.
Statistical methods for analyzing this two-dimensional data exist. MANOVA, for example, can test if the heights and weights in boys and girls is different. This statisticaltest is correct because the data are (presumably) bivariate normal. Each property is discussed below with R code so the reader can test it themselves.
This feature is part of the Amazon Redshift console and provides a visual and graphical representation of the query’s run order, execution plan, and various statistics. To test Query profiler against the sample data, load the tpcds sample data and run queries. Try this feature in your environment and share your feedback with us.
Gen Xers (born 1965-1980), Millennials (born 1981-1996), Gen Zers (born 1997-2012) have grown up in a world where IT has been generally thought to be a good, bordering on great, thing. While IT/digital can take some solace in not being perceived as the No. This positive generational bias toward IT is rapidly disappearing.
By 2012, there was a marginal increase, then the numbers rose steeply in 2014. One of the best solutions for data protection is advanced automated penetration testing. The instances of data breaches in the United States are rather interesting. Employee training.
AWS Glue Data Quality reduces the effort required to validate data from days to hours, and provides computing recommendations, statistics, and insights about the resources required to run data validation. In this post, we provide benchmark results of running increasingly complex data quality rulesets over a predefined test dataset.
IBM Cloud Pak for Business Automation , for example, provides a low-code studio for testing and developing automation strategies. Power Advisor tracks statistics about performance to locate bottlenecks and other issues. Rocketbot Orquestador will manage them, running them as needed while compiling statistics.
and implications of findings) than in statistical significance. Apply the Squint Test In these before scatter plot on the left, the cluttered appearance distracts us from the data. Apply the Squint Test. I like to test my drafts ahead of time to make sure they’ll still be legible even if they’re printed in grayscale.
In contrast, the decision tree classifies observations based on attribute splits learned from the statistical properties of the training data. Machine Learning-based detection – using statistical learning is another approach that is gaining popularity, mostly because it is less laborious. 3f" % x) dataDF.describe().
I published my first video on November 4, 2012…. Can I hire you to help me prep for the Excel tests that I’ll have to take as part of the hiring process?” ” I’d been a formal statistics tutor and Spanish tutor in college through a small invite-only program. I didn’t create the test!! Most Controversial.
A big part of statistics, particularly for financial and econometric data, is analyzing time series, data that are autocorrelated over time. predict(usBest, n.ahead=5, se.fit=TRUE) $pred Time Series: Start = 2012 End = 2016 Frequency = 1 [1] 49292.41 Chapter Introduction: Time Series and Autocorrelation. > attGarch.
Synthea is a synthetic patient generator that creates realistic patient data and associated medical records that can be used for testing healthcare software applications. To learn more about Pydeequ as a data testing framework, see Testing Data quality at scale with Pydeequ.
Data engineers and data scientists have test data, and want to load data into Amazon Redshift for their machine learning (ML) or analytics use cases. Select Statistics update and ON , then choose Next. They want to join that data with the curated data in their data warehouse. Choose Load operations. Choose Load existing table.
A naïve way to solve this problem would be to compare the proportion of buyers between the exposed and unexposed groups, using a simple test for equality of means. Identification We now discuss formally the statistical problem of causal inference. We start by describing the problem using standard statistical notation.
Another key point: troubleshooting edge cases for models in production—which is often where ethics and data meet, as far as regulators are concerned—requires much more sophistication in statistics than most data science teams tend to have. It’s a quick way to clear the room. machine learning? Or something. Nothing Spreads Like Fear”.
Similarly, we could test the effectiveness of a search ad compared to showing only organic search results. Structure of a geo experiment A typical geo experiment consists of two distinct time periods: pretest and test. After the test period finishes, the campaigns in the treatment group are reset to their original configurations.
If $Y$ at that point is (statistically and practically) significantly better than our current operating point, and that point is deemed acceptable, we update the system parameters to this better value. e-handbook of statistical methods: Summary tables of useful fractional factorial designs , 2018 [3] Ulrike Groemping.
We often use statistical models to summarize the variation in our data, and random effects models are well suited for this — they are a form of ANOVA after all. both L1 and L2 penalties; see [8]) which were tuned for test set accuracy (log likelihood). Cambridge University Press, (2012). [4] ICML, (2005). [3] 3] Bradley Efron.
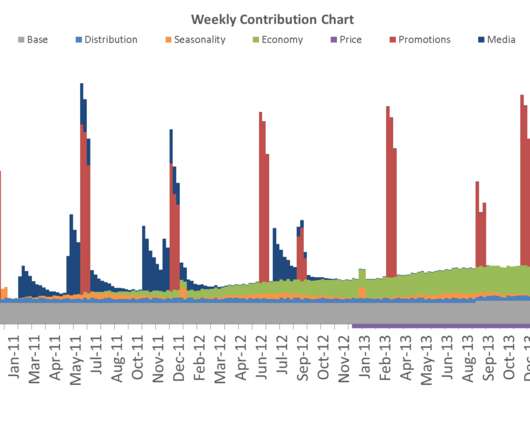
MMM stands for Marketing Mix Model and it is one of the oldest and most well-established techniques to measure the sales impact of marketing activity statistically. As with any type of statistical model, data is key and GIGO (“Garbage In, Garbage Out”) principle definitely applies. What is MMM? Data Requirements.
According to the Telegraph (2012), Female execs earn £423,390 less than men over careers. . For the leaders, the simplest option can simply be doing nothing, but let someone run around burning themselves out so that eventually it becomes a test of patience and stamina, rather than a test of what is right and wrong.
I’m here mostly to provide McLuhan quotes and test the patience of our copy editors with hella Californian colloquialisms. That’s the point where models degrade once exposed to live customer data, and where it requires significant statistical expertise to answer even a simple “Why?” Plus blatant overuse of intertextual parataxis.
Your Chance: Want to test a professional data discovery tool for free? Studies say that more data has been generated in the last two years than in the entire history before and that since 2012 the industry has created around 13 million jobs around the world. Your Chance: Want to test a professional data discovery tool for free?
1]" Statistics, as a discipline, was largely developed in a small data world. Yet when we use these tools to explore data and look for anomalies or interesting features, we are implicitly formulating and testing hypotheses after we have observed the outcomes. We must correct for multiple hypothesis tests.
10% of your time should be spent in implementing tools, not 15 months with an eye towards analysis in the middle of 2012. And possess at least some knowledge of the fundamentals of statistics. " This was in context of a President Obama A/B test. A/B testing! You can win with Omniture or WebTrends or IBM or Google.
1) What Is A Misleading Statistic? 2) Are Statistics Reliable? 3) Misleading Statistics Examples In Real Life. 4) How Can Statistics Be Misleading. 5) How To Avoid & Identify The Misuse Of Statistics? If all this is true, what is the problem with statistics? What Is A Misleading Statistic?
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content