This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For all the excitement about machinelearning (ML), there are serious impediments to its widespread adoption. There are several known attacks against machinelearning models that can lead to altered, harmful model outcomes or to exposure of sensitive training data. [8] 2] The Security of MachineLearning. [3]
In 2013, less than 0.5% 2) “Deep Learning” by Ian Goodfellow, Yoshua Bengio and Aaron Courville. Best for: This best data science book is especially effective for those looking to enter the data-driven machinelearning and deep learning avenues of the field. Why You Need To Read Data Science Books.
As both words are semantically close to each other, machinelearning models can easily understand that “delicious” also refers to the pasta tasting good. Word embedding is a type of word representation that allows words with similar meanings to be understood by machinelearning algorithms.
With its business rapidly growing and customer expectations rising, Thermo Fisher Scientific is turning to machinelearning and robotic process automation (RPA) to transform the customer experience. in 2013, Alfa Aesar in 2015, Affymetrix and FEI Co. in 2016, and BD Advanced Bioprocessing in 2018. Catalyzing change.
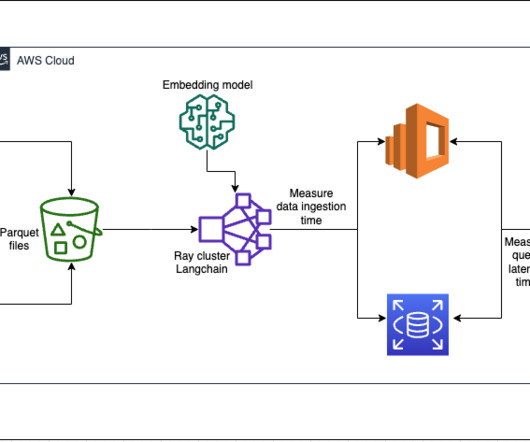
RAG is a machinelearning (ML) architecture that uses external documents (like Wikipedia) to augment its knowledge and achieve state-of-the-art results on knowledge-intensive tasks. Each service implements k-nearest neighbor (k-NN) or approximate nearest neighbor (ANN) algorithms and distance metrics to calculate similarity.
Amazon Redshift ML makes it easy for data analysts and database developers to create, train, and apply machinelearning (ML) models using familiar SQL commands in Amazon Redshift. With Redshift ML, you can take advantage of Amazon SageMaker , a fully managed ML service, without learning new tools or languages.
In this article, we’ll discuss the challenge organizations face around fraud detection, how machinelearning can be used to identify and spot anomalies that the human eye might not catch. from sklearn import metrics. It can be implemented as either unsupervised (e.g. from imblearn.over_sampling import SMOTE.
word2vec is an unsupervised learning technique—that is, it is applied to a corpus of natural language without making use of any labels that may or may not happen to exist for the corpus. Note: A test set of 19,500 such analogies was developed by Tomas Mikolov and his colleagues in their 2013 word2vec paper. Note: Mikolov, T.,
For example, Crisis Text Line , which provides online support to people in crisis, received a total of 8 m illion text messages in the first two years of its existence between 2013 and 2015. This is important because unlike diabetes or high blood pressure we don’t yet have clear metrics for Parkinson’s.
He outlined how critical measurable results are to help VCs make major investment decisions — metrics such as revenue, net vs gross earnings, sales , costs and projections, and more. Kongregate has been using Periscope Data since 2013. Kyle said: We empower data analysts to create more business value than any other BI platform.
Machinelearning and advanced analytics are helping humans make sense of large amounts of structured and unstructured data by leaning into our natural ability to make a better sense of visuals than the raw data we want to understand. The good news is, you don’t have to!
the weight given to Likes in our video recommendation algorithm) while $Y$ is a vector of outcome measures such as different metrics of user experience (e.g., Experiments, Parameters and Models At Youtube, the relationships between system parameters and metrics often seem simple — straight-line models sometimes fit our data well.
In 2013, IBM embarked on the journey of explainability and transparency in AI and machinelearning. We follow long-held principles of trust and transparency that make clear the role of AI is to augment, not replace, human expertise and judgment. But it is well worth the effort.
Companies like Tableau (which raised over $250 million when it had its IPO in 2013) demonstrated an unmet need in the market. As a result, end users can better view shared metrics (backed by accurate data), which ultimately drives performance. They can also create custom calculations and metrics, and build new data visualizations.
In 2013, Robert Galbraith?—?an It is worth keeping in mind that the choice of threshold will impact downstream metrics like precision as well as shifting the size of our dataset. Future versions of the AIgent may be improved with the use of more nuanced metrics, depending on the class-encoding scheme applied.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content