This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For all the excitement about machinelearning (ML), there are serious impediments to its widespread adoption. In addition to newer innovations, the practice borrows from model risk management, traditional model diagnostics, and software testing. Not least is the broadening realization that ML models can fail. ML security audits.
In June of 2020, Database Trends & Applications featured DataKitchen’s end-to-end DataOps platform for its ability to coordinate data teams, tools, and environments in the entire data analytics organization with features such as meta-orchestration , automated testing and monitoring , and continuous deployment : DataKitchen [link].
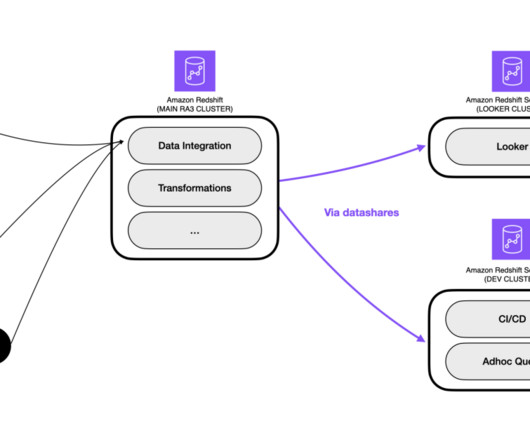
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. In internal tests, AI-driven scaling and optimizations showcased up to 10 times price-performance improvements for variable workloads.
While training a model for NLP, words not present in the training data commonly appear in the test data. Because of this, predictions made using test data may not be correct. To solve this problem, machines need to capture the semantic meaning of words. Test data then contains this sentence: Pasta is delicious.
But for two years, we were testing limits within the public cloud.” Randich, who came to FINRA.org in 2013 after stints as co-CIO of Citigroup and former CIO of Nasdaq, is no stranger to the public cloud. “We spent about a year and a half going through several bottlenecks, taking them out one at a time with Amazon engineers.
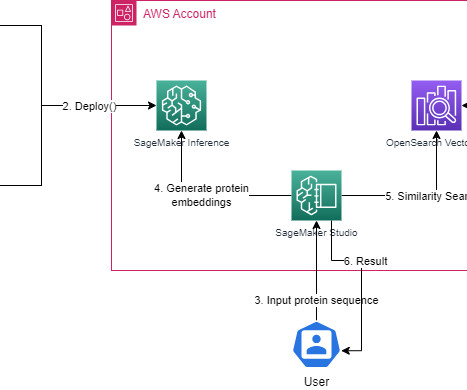
ProtT5-XL-UniRef50 is a machinelearning (ML) model specifically designed to understand the language of proteins by converting protein sequences into multidimensional embeddings. ProtTrans: Toward Understanding the Language of Life Through Self-Supervised Learning”. Code for this solution is available in GitHub. Mikolov, T.;
In 2013, Amazon Web Services revolutionized the data warehousing industry by launching Amazon Redshift , the first fully-managed, petabyte-scale, enterprise-grade cloud data warehouse. Amazon Redshift made it simple and cost-effective to efficiently analyze large volumes of data using existing business intelligence tools.
RAG is a machinelearning (ML) architecture that uses external documents (like Wikipedia) to augment its knowledge and achieve state-of-the-art results on knowledge-intensive tasks. He entered the big data space in 2013 and continues to explore that area. This is where the Retrieval Augmented Generation (RAG) technique comes in.
Wallapop’s initial data architecture platform Wallapop is a Spanish ecommerce marketplace company focused on second-hand items, founded in 2013. Since its creation in 2013, it has reached more than 40 million downloads and more than 700 million products have been listed. The marketplace can be accessed via mobile app or website.
In the context of machinelearning, we consider data drift 1 to be the change in model input data that leads to a degradation of model performance. Step 4: Generate the test, train and noisy MNIST data sets. Generate the train and test sets (x_train, _), (x_test, _) = mnist.load_data() x_train = x_train.astype('float32') / 255.
It is my immense pleasure to introduce you all to our guest today Ria Persad, she’s named as international woman of the year by Renewable Energy World in power engineering in 2013 and the lifetime achievement leader by Platts Global Energy awards in 2014. We need people who can test.
Collaboration BI At one of my weekly #BIWisdom tweetchats this month, collaboration, social media and text analytics turned up in a discussion about 2013 BI predictions that didn’t pan out. Vendors need to automate and decrease that effort.” • “I tested a social analytics tool; I was less than impressed.
In this article, we’ll discuss the challenge organizations face around fraud detection, how machinelearning can be used to identify and spot anomalies that the human eye might not catch. This is to prevent any information leakage into our test set. 2f%% of the test set." 2f%% of the test set."
For example, Crisis Text Line , which provides online support to people in crisis, received a total of 8 m illion text messages in the first two years of its existence between 2013 and 2015. Fox Foundation is testing a watch-type wearable device in Australia to continuously monitor the symptoms of patients with Parkinson’s disease.
by OMKAR MURALIDHARAN Many machinelearning applications have some kind of regression at their core, so understanding large-scale regression systems is important. But most common machinelearning methods don’t give posteriors, and many don’t have explicit probability models. Figure 4 shows the results of such a test.
word2vec is an unsupervised learning technique—that is, it is applied to a corpus of natural language without making use of any labels that may or may not happen to exist for the corpus. Note: A test set of 19,500 such analogies was developed by Tomas Mikolov and his colleagues in their 2013 word2vec paper. Note: Mikolov, T.,
2013: Google launches Google Compute Engine (IaaS), its own version of EC2. Microsoft launches Azure ML Studio for machinelearning capabilities on the cloud. AWS rolls out SageMaker, designed to build, train, test and deploy machinelearning (ML) models. Google releases Kubernetes.
Multiparameter experiments, however, generate richer data than standard A/B tests, and automated t-tests alone are insufficient to analyze them well. We use PrePost in most of our A/B tests, so we have pre-experiment metric measurements readily available that we can use as covariates in our models. Springer Netherlands, 2013. [16]
Wiggins advocated that data scientists find problems that impact the business; re-frame the problem as a machinelearning (ML) task; execute on the ML task; and communicate the results back to the business in an impactful way. I still believe that data science is the craft of trying to apply machinelearning to some real world problem.
The effects of AI will be magnified in the coming decade as manufacturing, retailing, transportation, finance, health care, law, advertising, insurance, entertainment, education, and virtually every other industry transform their core processes and business models to take advantage of machinelearning.
Reliable “The Department’s AI capabilities will have explicit, well-defined uses, and the safety, security, and effectiveness of such capabilities will be subject to testing and assurance within those defined uses across their entire life cycles.” This is misguided. But it is well worth the effort.
In 2013, Robert Galbraith?—?an I tested several different flavors of BERT for use as synopsis classifiers before settling on the DistilBERT model from Hugging Face. On my test set, this approach resulted in~75–95% accuracy and ~.65 Test Case: Dune Let’s see an example of genre tag prediction in action.
Companies like Tableau (which raised over $250 million when it had its IPO in 2013) demonstrated an unmet need in the market. Later on, you’ll appreciate being able to test ideas and leverage best practices as your needs evolve. Users’ varied needs require a shift in traditional BI thinking. Their dashboards were visually stunning.
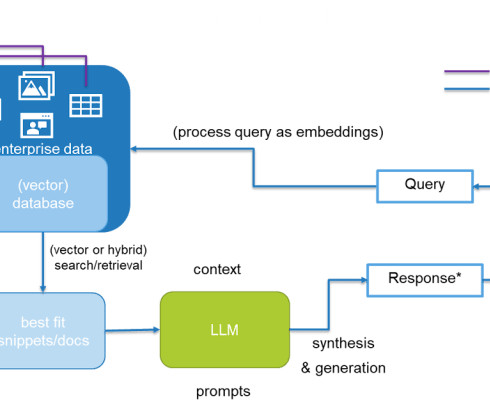
The combination of AI and search enables new levels of enterprise intelligence, with technologies such as natural language processing (NLP), machinelearning (ML)-based relevancy, vector/semantic search, and large language models (LLMs) helping organizations finally unlock the value of unanalyzed data.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content