This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For model training and selection, we recommend considering fairness metrics when selecting hyperparameters and decision cutoff thresholds. 1] “All models are wrong, but some are useful.” — George Box, Statistician (1919 – 2013). [2] 17] Hopefully some of these techniques will work for you and your team.
For these reasons, we have applied semantic data integration and produced a coherent knowledge graph covering all Bulgarian elections from 2013 to the present day. Easily accessible linked open elections data.
In 2013, less than 0.5% For those embarking on a journey to master the art of the ‘R’ language – a statistical computing program and framework for increased business intelligence-based success – Advanced R is intuitive, easy to follow, and will give you a well-rounded overview of this invaluable area of data science.
Chapin shared that even though GE had embraced agile practices since 2013, the company still struggled with massive amounts of legacy systems. One of the keys for our success was really focusing that effort on what our key business initiatives were and what sorts of metrics mattered most to our customers. Take a show-me approach.
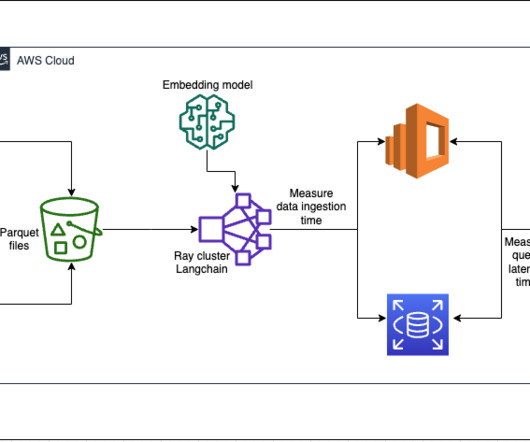
Each service implements k-nearest neighbor (k-NN) or approximate nearest neighbor (ANN) algorithms and distance metrics to calculate similarity. You will see the Ray dashboard and statistics of the jobs and cluster running. You can track metrics from here. He entered the big data space in 2013 and continues to explore that area.
In contrast, the decision tree classifies observations based on attribute splits learned from the statistical properties of the training data. Machine Learning-based detection – using statistical learning is another approach that is gaining popularity, mostly because it is less laborious. from sklearn import metrics.
the weight given to Likes in our video recommendation algorithm) while $Y$ is a vector of outcome measures such as different metrics of user experience (e.g., Experiments, Parameters and Models At Youtube, the relationships between system parameters and metrics often seem simple — straight-line models sometimes fit our data well.
He outlined how critical measurable results are to help VCs make major investment decisions — metrics such as revenue, net vs gross earnings, sales , costs and projections, and more. Kongregate has been using Periscope Data since 2013. Diving deeper into the datasphere: Data lakes — best practices.
Although it’s not perfect, [Note: These are statistical approximations, of course!] Note: A test set of 19,500 such analogies was developed by Tomas Mikolov and his colleagues in their 2013 word2vec paper. Example 11.6 Detecting collocated bigrams with more conservative thresholds. Note: Mikolov, T., arXiv:1301.3781]. 0.85 = 0.15.
It will get us to the complete statistical data for each feature. Previously, he held leadership roles in analytics and operations, including launching the company’s first paid SaaS offerings at Square and helping Tremor Video IPO in 2013. We have three methods for exploratory data analysis: Univariate analysis. Bivariate analysis.
Second, between 2012 and 2013. When I present it, I'll say something like "Our peak investment, in Aquantive in 2013, was 700k." You are comparing 2012 and 2013, add a row of data at the top that shows your computation of the size of the opportunity for 2014. The reason is quite simple. That's hard enough.
Companies like Tableau (which raised over $250 million when it had its IPO in 2013) demonstrated an unmet need in the market. As a result, end users can better view shared metrics (backed by accurate data), which ultimately drives performance. They can also create custom calculations and metrics, and build new data visualizations.
In 2013, Robert Galbraith?—?an The most powerful approach for the first task is to use a ‘language model’ (LM), i.e. a statistical model of natural language. It is worth keeping in mind that the choice of threshold will impact downstream metrics like precision as well as shifting the size of our dataset. an aspiring author?—?finished
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content