This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In addition to newer innovations, the practice borrows from model risk management, traditional model diagnostics, and software testing. Because ML models can react in very surprising ways to data they’ve never seen before, it’s safest to test all of your ML models with sensitivity analysis. [9] If so, have fun debugging! [1]
Chapin shared that even though GE had embraced agile practices since 2013, the company still struggled with massive amounts of legacy systems. One of the keys for our success was really focusing that effort on what our key business initiatives were and what sorts of metrics mattered most to our customers.
Financial institutions such as banks have to adhere to such a practice, especially when laying the foundation for back-test trading strategies. A 2013 survey conducted by the IBM’s Institute of Business Value and the University of Oxford showed that 71% of the financial service firms had already adopted analytics and big data.
While training a model for NLP, words not present in the training data commonly appear in the test data. Because of this, predictions made using test data may not be correct. Using the semantic meaning of words it already knows as a base, the model can understand the meanings of words it doesn’t know that appear in test data.
According to Nielsen, YouTube reaches more US adults ages 18-34 than any cable network as of mid-2013. As of March 2013, one billion, (B!), One more thing to ponder… One hundred hours of video is uploaded into YouTube every single minute, as of May 2013. I'm not a fan of compound metrics. How cool is that!
Containers have increased in popularity and adoption ever since the release of Docker in 2013, an open-source platform for building, deploying and managing containerized applications. Containerization helps DevOps teams avoid the complications that arise when moving software from testing to production.
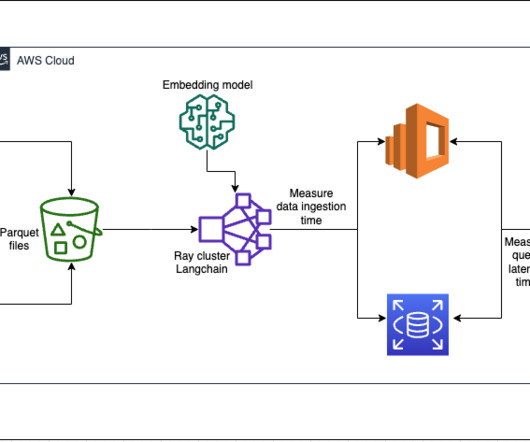
Each service implements k-nearest neighbor (k-NN) or approximate nearest neighbor (ANN) algorithms and distance metrics to calculate similarity. Ray cluster for ingestion and creating vector embeddings In our testing, we found that the GPUs make the biggest impact to performance when creating the embeddings. Waiting for connections.
Note: A test set of 19,500 such analogies was developed by Tomas Mikolov and his colleagues in their 2013 word2vec paper. This test set is available at download.tensorflow.org/data/questions-words.txt.]. Relative to extrinsic evaluations, intrinsic tests are quick. Note that the final test word in Table 11.2—ma’am—is
the weight given to Likes in our video recommendation algorithm) while $Y$ is a vector of outcome measures such as different metrics of user experience (e.g., Experiments, Parameters and Models At Youtube, the relationships between system parameters and metrics often seem simple — straight-line models sometimes fit our data well.
The dataset contains transactions made by European credit card holders in September 2013, and has been anonymized – Features V1, V2, …, V28 are results from applying PCA on the raw data. from sklearn import metrics. from sklearn import metrics. This is to prevent any information leakage into our test set.
For example, Crisis Text Line , which provides online support to people in crisis, received a total of 8 m illion text messages in the first two years of its existence between 2013 and 2015. Fox Foundation is testing a watch-type wearable device in Australia to continuously monitor the symptoms of patients with Parkinson’s disease.
One that reflects the customer expectations of 2013. Or Ford (it is amazing that in 2013, for such an expensive product, it looks so… 2005). Bonus: Facebook Marketing: Best Metrics, ROI, Business Value ]. Here is what it looks like: Let's look at each step on the ladder in some detail. Look at the colors. Beat Motrin.
It is not just what you do to attract traffic (what most people think of as marketing and advertising), but also what types of experiences you create (something people rarely think is marketing) and how good you are at delivering for where you should be in 2013 rather than 2009 (only the rarest of marketers think with this lens on).
There is only one simple message above, and just two metrics that matter. The latter is especially important because it directly ties to what content the ads/marketing should contain, what the tone and texture should be of the landing page/app experience, and what we'll use to measure success (S, T, D, C metrics).
[A benchmark for you: In 2013 if 30% of your time, Ms./Mr. Many used some data, but they unfortunately used silly data strategies/metrics. And silly simply because as soon as the strategy/success metric being obsessed about was mentioned, it was clear they would fail. It is a really good metric. They get you fired.
Reliable “The Department’s AI capabilities will have explicit, well-defined uses, and the safety, security, and effectiveness of such capabilities will be subject to testing and assurance within those defined uses across their entire life cycles.” This is misguided. But it is well worth the effort.
Companies like Tableau (which raised over $250 million when it had its IPO in 2013) demonstrated an unmet need in the market. As a result, end users can better view shared metrics (backed by accurate data), which ultimately drives performance. They can also create custom calculations and metrics, and build new data visualizations.
In 2013, Robert Galbraith?—?an I tested several different flavors of BERT for use as synopsis classifiers before settling on the DistilBERT model from Hugging Face. It is worth keeping in mind that the choice of threshold will impact downstream metrics like precision as well as shifting the size of our dataset.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























Let's personalize your content