This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Not least is the broadening realization that ML models can fail. And that’s why model debugging, the art and science of understanding and fixing problems in ML models, is so critical to the future of ML. Because all ML models make mistakes, everyone who cares about ML should also care about model debugging. [1]
When we started with generative AI and large language models, we leveraged what providers offered in the cloud. Now that we have a few AI use cases in production, were starting to dabble with in-house hosted, managed, small language models or domain-specific language models that dont need to sit in the cloud.
From the discussions, it is clear that today, the critical focus for CISOs, CIOs, CDOs, and CTOs centers on protecting proprietary AI models from attack and protecting proprietary data from being ingested by public AI models. isnt intentionally or accidentally exfiltrated into a public LLM model?
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. Lakehouse allows you to use preferred analytics engines and AI models of your choice with consistent governance across all your data.
Think your customers will pay more for data visualizations in your application? Five years ago they may have. But today, dashboards and visualizations have become table stakes. Discover which features will differentiate your application and maximize the ROI of your embedded analytics. Brought to you by Logi Analytics.
From 2013 with the first deep learning model to successfully learn a policy directly from pixel input using reinforcement learning to the OpenAI Dexterity project in 2019, we live in an exciting moment in RL research. In the last few years, we’ve seen a lot of breakthroughs in reinforcement learning (RL).
The excerpt covers how to create word vectors and utilize them as an input into a deep learning model. While the field of computational linguistics, or Natural Language Processing (NLP), has been around for decades, the increased interest in and use of deep learning models has also propelled applications of NLP forward within industry.
Cloud Programming Simplified: A Berkeley View on Serverless Computing (2019) – Serverless computing is very popular nowadays and this article covers some of the limitations.
Insurance companies have access to stats on what make and model of car is stolen more often or involved in more crashes. For instance, the 2000 Honda Civic is the most stolen car in America and the Mitsubishi Mirage (in the 2013-2017 model range) has the most fatal crashes. Telematics.
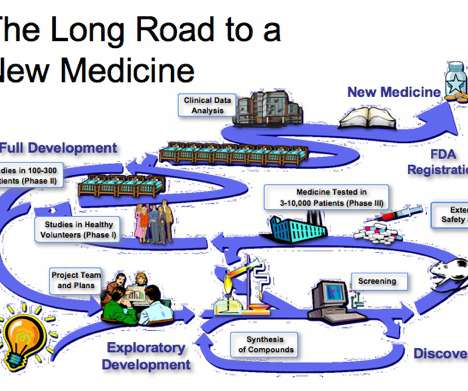
Current R&D Models Provide Diminishing Returns. In a report on the failure rates of drug discovery efforts between 2013 and 2015, Richard K. Now, picture the same process using heuristic models, machine vision, and artificial intelligence. Artificial intelligence can help us take better care of those we’ve left behind.
OpenAI is setting up a new governance body to oversee the safety and security of its AI models, as it embarks on the development of a successor to GPT-4. The first task for the OpenAI Board’s new Safety and Security Committee will be to evaluate the processes and safeguards around how the company develops future models.
A 2013 survey conducted by the IBM’s Institute of Business Value and the University of Oxford showed that 71% of the financial service firms had already adopted analytics and big data. Big Data can efficiently enhance the ways firms utilize predictive models in the risk management discipline. The Underlying Concept.
While training a model for NLP, words not present in the training data commonly appear in the test data. Using the semantic meaning of words it already knows as a base, the model can understand the meanings of words it doesn’t know that appear in test data. It’s difficult to retrain models frequently from scratch for new data.
India’s Ministry of Electronics and Information Technology (MeitY) has caused consternation with its stern reminder to makers and users of large language models (LLMs) of their obligations under the country’s IT Act, after Google’s Gemini model was prompted to make derogatory remarks about Indian Prime Minister Narendra Modi.
For these reasons, we have applied semantic data integration and produced a coherent knowledge graph covering all Bulgarian elections from 2013 to the present day. A set of of sample queries is provided to help the understanding of the data model and shorten the learning curve. Easily accessible linked open elections data.
SSI), which he co-founded with Daniel Gross, co-founder of the search engine company Cue (acquired by Apple in 2013), and Daniel Levy, a former OpenAI researcher. He went on to say that the company’s business model “means safety, security and progress are all insulated from short-term commercial pressures.
There are a number of factors that can contribute to sudden changes in Bitcoin’s price that machine learning developers need to incorporate into their pricing models. Vankhede isn’t the only one that has developed predictive analytics models to predict bitcoin prices.
Sometimes big data models can look at which keywords and topics are trending on social media and, as translation company Tomedes points out, that can involve multiple languages. Even by 2013, 90% of the data in the world had been generated within the previous two years. It’s overwhelming just how fast our data is growing.
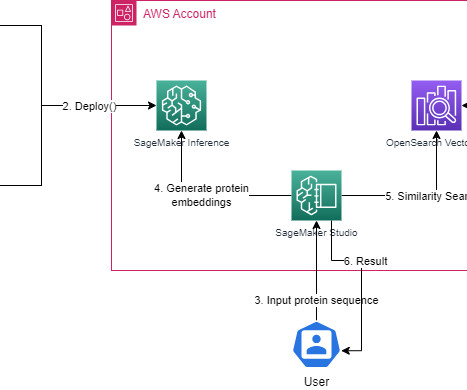
In this blog post, we propose a solution based on Amazon OpenSearch Service for similarity search and the pretrained model ProtT5-XL-UniRef50 , which we will use to generate embeddings. ProtT5-XL-UniRef50 is based on the t5-3b model and was pretrained on a large corpus of protein sequences in a self-supervised fashion.
This is where propensity modeling, or other techniques of causal inference, comes into play. Propensity Modeling. So suppose we want to model the effect of drinking Soylent using a propensity model technique. Propensity modeling , then, is a simplification of this twin matching procedure. What do we do?
It will be the same in 2013. Even if you never get into the mess of attribution modeling and all that other craziness, you are much smarter by just analyzing the data, and implications, from at this report. After that if you can't resist the itch, go play with the, now free to everyone, Attribution Modeling Tool in GA.
It’s been a long time since I wrote an article on Tabular Model. In this article, I want to show you how to connect to your Tabular Model database and use it as the underlying model for either Pivot Table, Pivot Chart, or Power View. Connecting to Tabular Model in Excel. i.e. Pivot Table, Pivot Chart or Power View.
It’s been a long time since I wrote an article on Tabular Model. In this article, I want to show you how to connect to your Tabular Model database and use it as the underlying model for either Pivot Table, Pivot Chart, or Power View. Connecting to Tabular Model in Excel. i.e. Pivot Table, Pivot Chart or Power View.
Randich, who came to FINRA.org in 2013 after stints as co-CIO of Citigroup and former CIO of Nasdaq, is no stranger to the public cloud. “We spent about a year and a half going through several bottlenecks, taking them out one at a time with Amazon engineers. And now we’re in a good place,” he says.
In 2013, Landmark Retail’s financial planning and analysis team faced challenges as they managed financial processes across more than 1200 stores. Their business model was very complex, and it required massive data volumes to be processed. Because of this, the budgeting process was inefficient.
The Challenge offers an opportunity for contestants to win prize money totaling over $700,000 for their development of a recidivism forecasting model using data provided by NIJ. The Challenge uses data from the State of Georgia about persons released from prison to parole supervision for the period January 1, 2013, through December 31, 2015.
In fact, it has been available since 2013. After adopting the MITRE ATT&CK as their common language and model for describing attacks and attackers, the critical infrastructure organization’s security team can now translate between operational aspects of security and the potential impact of a successful attack.
Excel 2013 is 1.8, Excel 2013 is 1.9) Excel 2013 is 1.8, Excel 2013 is 1.9) Excel 2013 is 1.8, Excel 2013 is 1.9) Excel 2013 is 1.8, Excel 2013 is 1.9) Excel 2013 is 1.8, Excel 2013 is 1.9) Excel 2013 is 1.8, Excel 2013 is 1.9)
The good news is that you can ask any of the large language models (LLMs) like ChatGPT to rewrite paragraphs or sections for improved comprehension or make it more concise. Delete old data I lived in Hong Kong 2008-2013 and one of my most pleasurable weekends was a trip to see an incredible band at the MGM hotel in Macau.
Mapping shifting hierarchical and regional tendencies in an urban network through alluvial diagrams (2013). Bayesian Modelling of Alluvial Diagram Complexity (2021). This is the first piece of research that empirically assesses, quantifies, and models the complexity of Alluvial Diagrams to aid in improving their effectiveness.
Chapin shared that even though GE had embraced agile practices since 2013, the company still struggled with massive amounts of legacy systems. Most companies have legacy models in software development that are well-oiled machines. Success Requires Focus on Business Outcomes, Benchmarking.
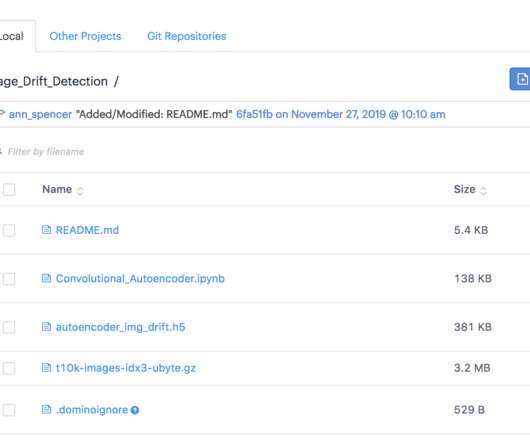
This article covers how to detect data drift for models that ingest image data as their input in order to prevent their silent degradation in production. Introduction: preventing silent model degradation in production. This article explores an approach that can be used to detect data drift for models that classify/score image data.
in 2013, Alfa Aesar in 2015, Affymetrix and FEI Co. We’re very much focused on the commercialization of acquisitions, making sure we don’t break the deal models and that things are running as they should be,” says John Stevens, vice president of IT at Thermo Fisher. in 2016, and BD Advanced Bioprocessing in 2018.
Large language models (LLMs) are becoming increasing popular, with new use cases constantly being explored. This is where model fine-tuning can help. Before you can fine-tune a model, you need to find a task-specific dataset. Next, we use Amazon SageMaker JumpStart to fine-tune the Llama 2 model with the preprocessed dataset.
Amazon Redshift ML makes it easy for data analysts and database developers to create, train, and apply machine learning (ML) models using familiar SQL commands in Amazon Redshift. Simply use SQL statements to create and train SageMaker ML models using your Redshift data and then use these models to make predictions.
OpenSearch Serverless overview and tenancy model options OpenSearch Service managed domains provided a stable foundation for Alcion’s search functionality, but the team needed to manually provision resources to the domains for their peak workload. This allowed Alcion to focus on optimizing the tenancy model for the new search architecture.
Among other accolades, he was named Consumer Goods Technology’s 2013 CIO of the Year and was the 2021 recipient of the Bay Area CIO of the Year ORBIE award for Leadership. Along the way, Loura has been recognized time and again as an inspiring, transformational CIO whose innovative approaches create real business value.
As a result, many organizations are able to join external data to their own data in real time to forecast business impacts, predict supply and demand , apply models, and aggregate to predict the spread of the virus. This builds reusable artifacts that power ad hoc analysis, and also serves that data into reporting to send to teams and models.
In 2013, Amazon Web Services revolutionized the data warehousing industry by launching Amazon Redshift , the first fully-managed, petabyte-scale, enterprise-grade cloud data warehouse. Amazon Redshift made it simple and cost-effective to efficiently analyze large volumes of data using existing business intelligence tools.
In 2012, COBIT 5 was released and in 2013, the ISACA released an add-on to COBIT 5, which included more information for businesses regarding risk management and information governance. COBIT 2019 Framework: Governance and management objectives: A companion guide that dives into the COBIT Core Model and 40 governance and management objectives.
In 2013, actually, with SPARQL 1.1. Ontotext Platform allows you to define a simple model of your data – or to generate it from your pre-existent ontology. This model would contain a number of objects such as Report, Drone, Inspection, Building, etc. SPARQL federation. That does not mean that it cannot visualize data.
By defining team types, their fundamental interactions, and the science behind them, you learn how to better model your organizations according to these definitions. “It gives the fundamental patterns for achieving fast flow,” he says. “By The CEO demands that Bill deliver the project in 90 days.
Carbon Neutrality 2050, and the Bio-Circular-Green Economic Model. In addition, since Huawei’s global flagship CSR project Seeds for the Future first started in Thailand in 2013, Huawei Thailand has already partnered with 23 local universities to facilitate knowledge transfer and skill improvement for over 215 leading students.
It is my immense pleasure to introduce you all to our guest today Ria Persad, she’s named as international woman of the year by Renewable Energy World in power engineering in 2013 and the lifetime achievement leader by Platts Global Energy awards in 2014. We need people who can test.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content