This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Not least is the broadening realization that ML models can fail. And that’s why model debugging, the art and science of understanding and fixing problems in ML models, is so critical to the future of ML. Because all ML models make mistakes, everyone who cares about ML should also care about model debugging. [1]
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. Lakehouse allows you to use preferred analytics engines and AI models of your choice with consistent governance across all your data.
Statistics show that married people have fewer car accidents than singletons. Insurance companies have access to crime statistics and can track the number of car theft and break-ins per neighborhood. Insurance companies have access to stats on what make and model of car is stolen more often or involved in more crashes.
For these reasons, we have applied semantic data integration and produced a coherent knowledge graph covering all Bulgarian elections from 2013 to the present day. A set of of sample queries is provided to help the understanding of the data model and shorten the learning curve. Easily accessible linked open elections data.
The excerpt covers how to create word vectors and utilize them as an input into a deep learning model. While the field of computational linguistics, or Natural Language Processing (NLP), has been around for decades, the increased interest in and use of deep learning models has also propelled applications of NLP forward within industry.
Chapin shared that even though GE had embraced agile practices since 2013, the company still struggled with massive amounts of legacy systems. Most companies have legacy models in software development that are well-oiled machines. Success Requires Focus on Business Outcomes, Benchmarking. Take a show-me approach.
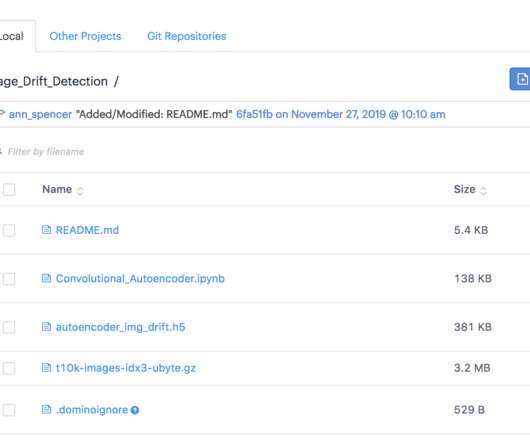
This article covers how to detect data drift for models that ingest image data as their input in order to prevent their silent degradation in production. Introduction: preventing silent model degradation in production. This article explores an approach that can be used to detect data drift for models that classify/score image data.
In 2013, Amazon Web Services revolutionized the data warehousing industry by launching Amazon Redshift , the first fully-managed, petabyte-scale, enterprise-grade cloud data warehouse. Amazon Redshift made it simple and cost-effective to efficiently analyze large volumes of data using existing business intelligence tools.
We’ll use a gradient boosting technique via XGBoost to create a model and I’ll walk you through steps you can take to avoid overfitting and build a model that is fit for purpose and ready for production. Let’s also look at the basic descriptive statistics for all attributes. from sklearn import metrics.
If $Y$ at that point is (statistically and practically) significantly better than our current operating point, and that point is deemed acceptable, we update the system parameters to this better value. Figure 2: Spreading measurements out makes estimates of model (slope of line) more accurate. And sometimes even if it is not[1].)
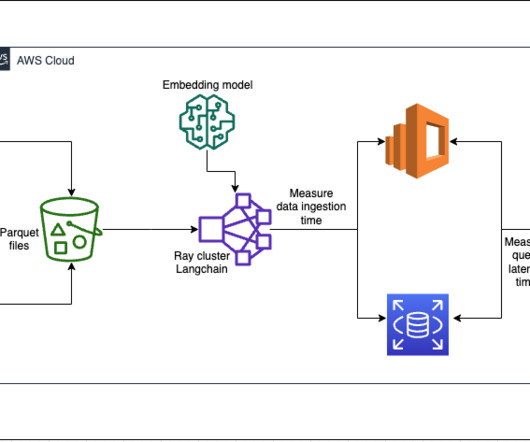
For building any generative AI application, enriching the large language models (LLMs) with new data is imperative. For the model used to create embeddings, we settled on all-mpnet-base-v2 to create a 768-dimensional vector space. You will see the Ray dashboard and statistics of the jobs and cluster running.
And he demonstrated how the Periscope Data platform overcomes the challenges of huge data volumes that can’t be easily modeled by traditional BI. Kongregate has been using Periscope Data since 2013. No surprise then that Tinder beat Netflix to become the highest-earning non-game app on both Google Play Store and the Apple Store.
I’ve been teaching data science since 2008 privately for employers – exec staff, investors, IT teams, and the data teams I’ve led – and since 2013, for industry professionals in general. Also, clearly there’s no “one size fits all” educational model for data science. The Berkeley model addresses large university needs in the US.
In 2013 I joined American Family Insurance as a metadata analyst. The Bureau of Labor Statistics projects the job outlook for data scientists to grow 22% from 2020 to 2030. The rapid growth of data roles critical to data-centric business models demonstrate an awareness of this need. Two data-driven careers.
For example, you can calculate the average percentage of votes cast for Democratic Party candidates: # Compute summary statistics for the `presidentialElections` data frame average_votes <- summarize(. Using the summarize() function to calculate summary statistics for the presidentialElections data frame. Red notes are added.
First, someone worked really hard on this and created a really nice model for a smarter decision to be made for 2014. Second, between 2012 and 2013. When I present it, I'll say something like "Our peak investment, in Aquantive in 2013, was 700k." You are a Ninja, it will likely take you less. Rest is irrelevant.
Diving into examples of building and deploying ML models at The New York Times including the descriptive topic modeling-oriented Readerscope (audience insights engine), a prediction model regarding who was likely to subscribe/cancel their subscription, as well as prescriptive example via recommendations of highly curated editorial content.
In 2013, Robert Galbraith?—?an The AIgent was built with BERT, Google’s state-of-the-art language model. In this article, I will discuss the construction of the AIgent, from data collection to model assembly. More relevant to the AIgent is Google’s BERT model, a task-agnostic (i.e. an aspiring author?—?finished
Companies like Tableau (which raised over $250 million when it had its IPO in 2013) demonstrated an unmet need in the market. These licensing terms are critical: Perpetual license vs subscription: Subscription is a pay-as-you-go model that provides flexibility as you evaluate a vendor. Their dashboards were visually stunning.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























Let's personalize your content