This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Not least is the broadening realization that ML models can fail. And that’s why model debugging, the art and science of understanding and fixing problems in ML models, is so critical to the future of ML. Because all ML models make mistakes, everyone who cares about ML should also care about model debugging. [1]
India’s Ministry of Electronics and Information Technology (MeitY) has caused consternation with its stern reminder to makers and users of large language models (LLMs) of their obligations under the country’s IT Act, after Google’s Gemini model was prompted to make derogatory remarks about Indian Prime Minister Narendra Modi.
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. In internal tests, AI-driven scaling and optimizations showcased up to 10 times price-performance improvements for variable workloads.
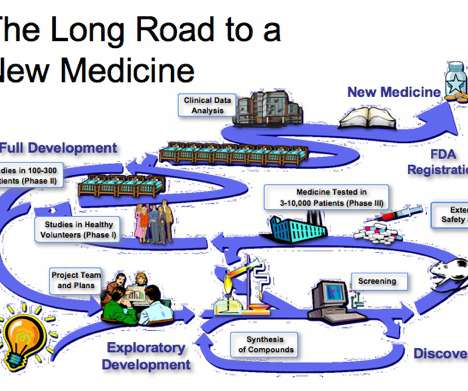
Current R&D Models Provide Diminishing Returns. Phase 0 is the first to involve human testing. Phase I involves dialing-in the proper dosage and further testing in a larger patient pool. In a report on the failure rates of drug discovery efforts between 2013 and 2015, Richard K. Some of the pieces are missing.
Think your customers will pay more for data visualizations in your application? Five years ago they may have. But today, dashboards and visualizations have become table stakes. Discover which features will differentiate your application and maximize the ROI of your embedded analytics. Brought to you by Logi Analytics.
Financial institutions such as banks have to adhere to such a practice, especially when laying the foundation for back-test trading strategies. A 2013 survey conducted by the IBM’s Institute of Business Value and the University of Oxford showed that 71% of the financial service firms had already adopted analytics and big data.
While training a model for NLP, words not present in the training data commonly appear in the test data. Because of this, predictions made using test data may not be correct. Using the semantic meaning of words it already knows as a base, the model can understand the meanings of words it doesn’t know that appear in test data.
The excerpt covers how to create word vectors and utilize them as an input into a deep learning model. While the field of computational linguistics, or Natural Language Processing (NLP), has been around for decades, the increased interest in and use of deep learning models has also propelled applications of NLP forward within industry.
Chapin shared that even though GE had embraced agile practices since 2013, the company still struggled with massive amounts of legacy systems. Most companies have legacy models in software development that are well-oiled machines. Success Requires Focus on Business Outcomes, Benchmarking.
But for two years, we were testing limits within the public cloud.” Randich, who came to FINRA.org in 2013 after stints as co-CIO of Citigroup and former CIO of Nasdaq, is no stranger to the public cloud. “We spent about a year and a half going through several bottlenecks, taking them out one at a time with Amazon engineers.
How can we understand causal lifts in the absence of an A/B test? This is where propensity modeling, or other techniques of causal inference, comes into play. Propensity Modeling. So suppose we want to model the effect of drinking Soylent using a propensity model technique. a negative effect).
In fact, it has been available since 2013. After adopting the MITRE ATT&CK as their common language and model for describing attacks and attackers, the critical infrastructure organization’s security team can now translate between operational aspects of security and the potential impact of a successful attack.
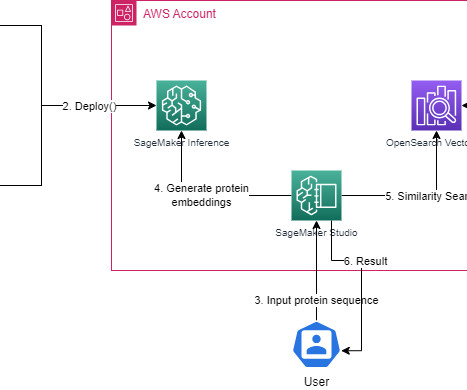
In this blog post, we propose a solution based on Amazon OpenSearch Service for similarity search and the pretrained model ProtT5-XL-UniRef50 , which we will use to generate embeddings. ProtT5-XL-UniRef50 is based on the t5-3b model and was pretrained on a large corpus of protein sequences in a self-supervised fashion.
The good news is that you can ask any of the large language models (LLMs) like ChatGPT to rewrite paragraphs or sections for improved comprehension or make it more concise. Delete old data I lived in Hong Kong 2008-2013 and one of my most pleasurable weekends was a trip to see an incredible band at the MGM hotel in Macau.
This article covers how to detect data drift for models that ingest image data as their input in order to prevent their silent degradation in production. Introduction: preventing silent model degradation in production. This article explores an approach that can be used to detect data drift for models that classify/score image data.
This is when IT operations and software development communities started to talk about problems in the software industry, specifically around the traditional software development model. While developers enjoy these streamlined processes, other team members may need more help in coordinating sequences for deploying and testing the application.
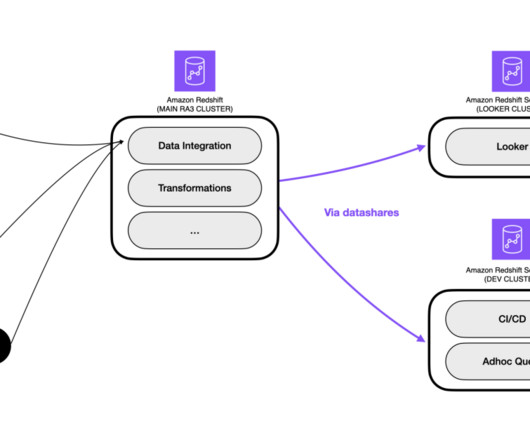
Amazon Redshift data sharing enables you to evolve your Amazon Redshift deployment architectures into a hub-and-spoke or data mesh model to better meet performance SLAs, provide workload isolation, perform cross-group analytics, and onboard new use cases, all without the complexity of data movement and data copies.
By defining team types, their fundamental interactions, and the science behind them, you learn how to better model your organizations according to these definitions. We need to really understand the drivers that influence customer and employee trust, as this is increasingly a litmus test,” says Johnson.
Large language models (LLMs) are becoming increasing popular, with new use cases constantly being explored. This is where model fine-tuning can help. Before you can fine-tune a model, you need to find a task-specific dataset. Next, we use Amazon SageMaker JumpStart to fine-tune the Llama 2 model with the preprocessed dataset.
It is my immense pleasure to introduce you all to our guest today Ria Persad, she’s named as international woman of the year by Renewable Energy World in power engineering in 2013 and the lifetime achievement leader by Platts Global Energy awards in 2014. We need people who can test.
The tradeoff is that you’d have to follow Spark’s programming model and you wouldn’t have the same amount of control as if you built the infrastructure yourself. Here are detailed instructions on how to install and test an installation of Hadoop on AWS. It’s a small amount of control to give up for what you gain?—?but
In 2013, Amazon Web Services revolutionized the data warehousing industry by launching Amazon Redshift , the first fully-managed, petabyte-scale, enterprise-grade cloud data warehouse. Amazon Redshift made it simple and cost-effective to efficiently analyze large volumes of data using existing business intelligence tools.
We’ll use a gradient boosting technique via XGBoost to create a model and I’ll walk you through steps you can take to avoid overfitting and build a model that is fit for purpose and ready for production. This is to prevent any information leakage into our test set. 2f%% of the test set."
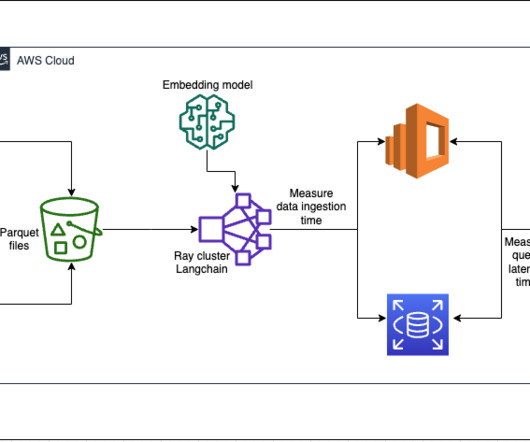
For building any generative AI application, enriching the large language models (LLMs) with new data is imperative. Ray cluster for ingestion and creating vector embeddings In our testing, we found that the GPUs make the biggest impact to performance when creating the embeddings. This breaks out to approximately 200 per record.
Containers have increased in popularity and adoption ever since the release of Docker in 2013, an open-source platform for building, deploying and managing containerized applications. Containerization helps DevOps teams avoid the complications that arise when moving software from testing to production.
Before the perfect storm, our tweetchat tribe (comprised of customers, vendors and consultants/analysts) were of the opinion that the growing “app” mentality for “cool stuff” among consumers and the easy-to-consume info in mobile apps could end up increasing trust and thus lead to less testing and faster releases.
By 2020, the robotics technology market is expected to reach almost $83 bn, according to the Global Robotics Technology Market 2013-2020. The RaaS model has recently become a common occurrence in the agro sector. Test the suggestions in a single department and scale the implemented technologies factory-wide, if successful.
But most common machine learning methods don’t give posteriors, and many don’t have explicit probability models. More precisely, our model is that $theta$ is drawn from a prior that depends on $t$, then $y$ comes from some known parametric family $f_theta$. Here, our items are query-ad pairs. Calculate posterior quantities of interest.
With the limited time F1 drivers have to test these days, rookies have to learn things very quickly – and he has done it very well. Killingsworth had 10 rebounds but they were outrebounded 48 – and none was more significant than the one on Brown’s missed free throw in the final seconds. I grew up on St.
Experiments, Parameters and Models At Youtube, the relationships between system parameters and metrics often seem simple — straight-line models sometimes fit our data well. That is true generally, not just in these experiments — spreading measurements out is generally better, if the straight-line model is a priori correct.
Amazon strategically went with the pricing model of ‘on-demand’, allowing developers to pay only as-per their computational needs. 2013: Google launches Google Compute Engine (IaaS), its own version of EC2. AWS rolls out SageMaker, designed to build, train, test and deploy machine learning (ML) models.
This allows you to easily rearrange the steps (simply by moving lines), as well as to “comment out” particular steps to test and debug your analysis as you go. Kennedy, and La Guardia airports) in 2013. Analyzing Data Frames by Group. You’ll use a data set of flights that departed from New York City airports (including Newark, John F.
One that reflects the customer expectations of 2013. Or Ford (it is amazing that in 2013, for such an expensive product, it looks so… 2005). Go buy a simple A/B testing tool ( Visual Website Optimizer , Optimizely ), go crazy optimizing every little thing to take money from the people who want to give it to you!
We need to really understand the drivers that influence customer and employee trust, as this is increasingly a litmus test,” says Johnson. By defining team types, their fundamental interactions, and the science behind them, you learn how to better model your organizations according to these definitions.
Diving into examples of building and deploying ML models at The New York Times including the descriptive topic modeling-oriented Readerscope (audience insights engine), a prediction model regarding who was likely to subscribe/cancel their subscription, as well as prescriptive example via recommendations of highly curated editorial content.
The effects of AI will be magnified in the coming decade as manufacturing, retailing, transportation, finance, health care, law, advertising, insurance, entertainment, education, and virtually every other industry transform their core processes and business models to take advantage of machine learning.
It shows the normal distribution of XS, S, L etc, but it also shows, how cool is this, the Model's size (S in this case), her height, bust, waist and hip size! You can't try the dress on, but this data helps you understand if it will look on you just like it does on the model. The model you see above just starts moving!
Earning trust in the outputs of AI models is a sociotechnical challenge that requires a sociotechnical solution. There must be a concerted effort to make these principles a reality through consideration of the functional and non-functional requirements in the models and the governance systems around those models.
A benchmark for you: In 2013 if 30% of your time, Ms./Mr. If the simple A/B (test/control) experiment demonstrates that delivering display banner ad impressions to the test group delivers increased revenue, buy impressions to your heart's content. In the latter group I discovered that there were two common themes.
In 2013, Robert Galbraith?—?an The AIgent was built with BERT, Google’s state-of-the-art language model. In this article, I will discuss the construction of the AIgent, from data collection to model assembly. More relevant to the AIgent is Google’s BERT model, a task-agnostic (i.e. an aspiring author?—?finished
Companies like Tableau (which raised over $250 million when it had its IPO in 2013) demonstrated an unmet need in the market. These licensing terms are critical: Perpetual license vs subscription: Subscription is a pay-as-you-go model that provides flexibility as you evaluate a vendor. Their dashboards were visually stunning.
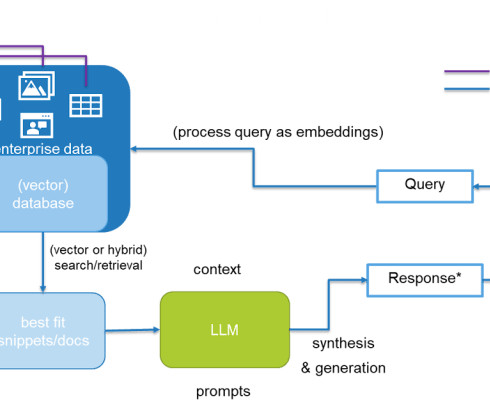
The combination of AI and search enables new levels of enterprise intelligence, with technologies such as natural language processing (NLP), machine learning (ML)-based relevancy, vector/semantic search, and large language models (LLMs) helping organizations finally unlock the value of unanalyzed data.
Its low-cost storage model makes it economically feasible to store vast amounts of historical data for extended periods of time. In this post, we walk through the following steps to set up and test this integration: Create an S3 bucket. He has been focusing in the big data analytics space since 2013. Amazon EMR 7.2.0
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content