This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Not least is the broadening realization that ML models can fail. And that’s why model debugging, the art and science of understanding and fixing problems in ML models, is so critical to the future of ML. Because all ML models make mistakes, everyone who cares about ML should also care about model debugging. [1]
In 2013, actually, with SPARQL 1.1. Ontotext Platform allows you to define a simple model of your data – or to generate it from your pre-existent ontology. This model would contain a number of objects such as Report, Drone, Inspection, Building, etc. Visualization tools and data access. SPARQL federation.
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. Lakehouse allows you to use preferred analytics engines and AI models of your choice with consistent governance across all your data.
Nowadays, terms like ‘Data Analytics,’ ‘Data Visualization,’ and ‘Big Data’ have become quite popular. A 2013 survey conducted by the IBM’s Institute of Business Value and the University of Oxford showed that 71% of the financial service firms had already adopted analytics and big data. The Underlying Concept.
Think your customers will pay more for data visualizations in your application? But today, dashboards and visualizations have become table stakes. Five years ago they may have. Discover which features will differentiate your application and maximize the ROI of your embedded analytics. Brought to you by Logi Analytics.
For these reasons, we have applied semantic data integration and produced a coherent knowledge graph covering all Bulgarian elections from 2013 to the present day. One can explore that data in GraphDB Workbench using its search, graph traversal and visualization facilities. Easily accessible linked open elections data. The road ahead.
The excerpt covers how to create word vectors and utilize them as an input into a deep learning model. While the field of computational linguistics, or Natural Language Processing (NLP), has been around for decades, the increased interest in and use of deep learning models has also propelled applications of NLP forward within industry.
This was the first paper to introduce the “Alluvial Diagram” and used this new visualisation to visually represent the change in a large and complex network structure over time. Mapping shifting hierarchical and regional tendencies in an urban network through alluvial diagrams (2013). Visualizing changes in nationally averaged PM2.5
What if there were a free, globally accessible, and open framework that could help your team map attacks, visualize strengths and weaknesses in your environment, and understand where you can strengthen controls to protect critical assets against attackers? In fact, it has been available since 2013.
It’s been a long time since I wrote an article on Tabular Model. In this article, I want to show you how to connect to your Tabular Model database and use it as the underlying model for either Pivot Table, Pivot Chart, or Power View. Connecting to Tabular Model in Excel. i.e. Pivot Table, Pivot Chart or Power View.
It’s been a long time since I wrote an article on Tabular Model. In this article, I want to show you how to connect to your Tabular Model database and use it as the underlying model for either Pivot Table, Pivot Chart, or Power View. Connecting to Tabular Model in Excel. i.e. Pivot Table, Pivot Chart or Power View.
This post is about standard GA reports, but the standard cart/checkout funnel visualization in GA is value deficient. It will be the same in 2013. Even if you never get into the mess of attribution modeling and all that other craziness, you are much smarter by just analyzing the data, and implications, from at this report.
Amazon Redshift ML makes it easy for data analysts and database developers to create, train, and apply machine learning (ML) models using familiar SQL commands in Amazon Redshift. Simply use SQL statements to create and train SageMaker ML models using your Redshift data and then use these models to make predictions.
As a result, many organizations are able to join external data to their own data in real time to forecast business impacts, predict supply and demand , apply models, and aggregate to predict the spread of the virus. This builds reusable artifacts that power ad hoc analysis, and also serves that data into reporting to send to teams and models.
In 2013, Amazon Web Services revolutionized the data warehousing industry by launching Amazon Redshift , the first fully-managed, petabyte-scale, enterprise-grade cloud data warehouse. Amazon Redshift made it simple and cost-effective to efficiently analyze large volumes of data using existing business intelligence tools.
licensed, open-source search and analytics suite, comprising OpenSearch (a search, analytics engine, and vector database), OpenSearch Dashboards (a visualization and utility user interface), and plugins that provide advanced capabilities like enterprise-grade security, anomaly detection, observability, alerting, and much more.
Source: Montreal Mayoral Election 2013, nicolas.kruchten.com. For example, you might compare the specifications of various computer or car models (comparing specs across a range of products). Another example is the badges generated for members of the Data Visualization Society. Ternary Bubble Graph. Ternary Contour Graph.
Containers have increased in popularity and adoption ever since the release of Docker in 2013, an open-source platform for building, deploying and managing containerized applications. Gartner predicts that 90% of global enterprises will use containerized applications and one in five apps will run in containers by 2026, as CIO reported.
And he explained that the leap to visual-based data discovery put analytics in the hands of data experts working in different lines of business, rather than in IT, where bottlenecks could previously occur, and reporting could take much longer. Kongregate has been using Periscope Data since 2013.
The tradeoff is that you’d have to follow Spark’s programming model and you wouldn’t have the same amount of control as if you built the infrastructure yourself. Presto, which was open-sourced in 2013 and predates the rise of Spark SQL, became popular due to its reliance on the SQL standard to query large amounts of data.
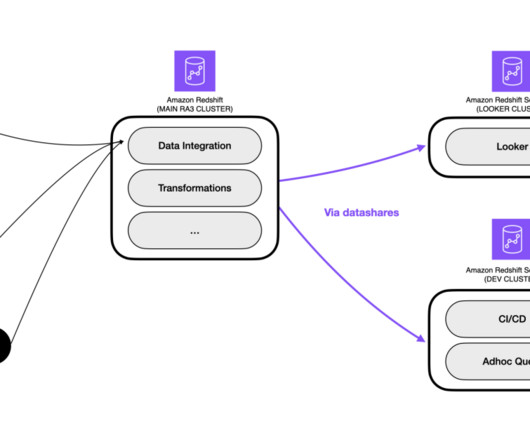
Amazon Redshift data sharing enables you to evolve your Amazon Redshift deployment architectures into a hub-and-spoke or data mesh model to better meet performance SLAs, provide workload isolation, perform cross-group analytics, and onboard new use cases, all without the complexity of data movement and data copies.
At one of our recent Friday #BIWisdom tweetchats, we talked about the findings in our 2013 Wisdom of Crowds® Collaborative Business Intelligence Market Study, which led to an insightful conversation about why some organizations haven’t adopted collaborative BI technologies and why some adopted it but failed to achieve the anticipated value.
I’ve been teaching data science since 2008 privately for employers – exec staff, investors, IT teams, and the data teams I’ve led – and since 2013, for industry professionals in general. Also, clearly there’s no “one size fits all” educational model for data science. The Berkeley model addresses large university needs in the US.
In compliance with the EU market transparency regulation (( Regulation EU No 5 43/2013 of 14 June 2013 on submission and publication of data in electricity markets ), ENTSO-E is doing a great job of collecting electricity market data (generation, transmission, consumption, balancing, congestion, outages, etc.)
Mobile apps have the characteristics that “good BI” should have: agile, visual, interactive and intuitive. Some tweeted that perhaps we should apply the mobile app model to business intelligence. Unfortunately this seldom occurs.
Experiments, Parameters and Models At Youtube, the relationships between system parameters and metrics often seem simple — straight-line models sometimes fit our data well. That is true generally, not just in these experiments — spreading measurements out is generally better, if the straight-line model is a priori correct.
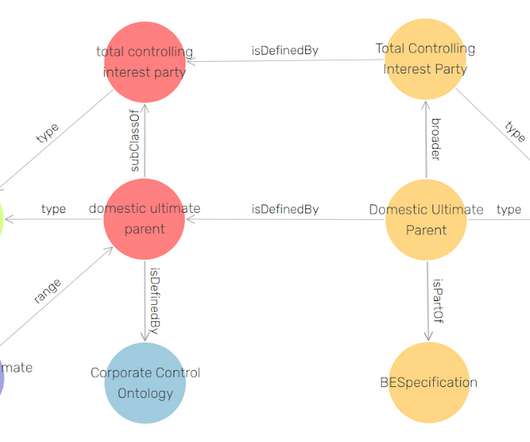
The Financial Industry Business Ontology (FIBO) is a conceptual model of the financial industry that has been developed by the Enterprise Data Management Council (EDMC). FIBO-DM is an Enterprise Data Model available as SAP PowerDesigner Conceptual and Logical Data Models. Query language W3C Recommendation 21 March 2013.
Amazon strategically went with the pricing model of ‘on-demand’, allowing developers to pay only as-per their computational needs. 2013: Google launches Google Compute Engine (IaaS), its own version of EC2. Microsoft also releases Power BI, a data visualization and business intelligence tool.
Special thanks to Addison-Wesley Professional for permission to excerpt the following “Manipulating data with dplyr” chapter from the book, Programming Skills for Data Science: Start Writing Code to Wrangle, Analyze, and Visualize Data with R. While this grouping is not visually apparent (i.e., Introduction.
Avoid complex visualizations – they get in the way! My goal is that you'll learn a set of filters you'll use as you think about the best ways to create your stories, however you choose to tell them with whatever visual output you most love. Avoid complex visualizations – they get in the way!
One that reflects the customer expectations of 2013. Or Ford (it is amazing that in 2013, for such an expensive product, it looks so… 2005). Go buy a simple A/B testing tool ( Visual Website Optimizer , Optimizely ), go crazy optimizing every little thing to take money from the people who want to give it to you!
Innocent: Passionate Copy and Heart-warming Visual Design. ~ Innocent: Passionate Copy and Heart-warming Visual Design. AAA's visual experience is substantially better than MetLife. You can't try the dress on, but this data helps you understand if it will look on you just like it does on the model.
Gain Attribution Modeling Savvy. You can also search for other stuff, like custom reports or attribution models. Ignore the eminently useless Reverse Goal Path report (I don't even know why this is still in GA after years of uselessness) and Funnel Visualization (almost totally useless in context of almost all Goals).
Diving into examples of building and deploying ML models at The New York Times including the descriptive topic modeling-oriented Readerscope (audience insights engine), a prediction model regarding who was likely to subscribe/cancel their subscription, as well as prescriptive example via recommendations of highly curated editorial content.
See step four in the process for creating your Digital Marketing and Measurement Model.]. This recommendation also valuable for companies that have very unique business models, or face other unusual circumstances (geographic, size, amount of innovation, and many others). See Page 269. :). So how can you use your own data?
Plus, there is an expectation that tools be visually appealing to boot. In the past, data visualizations were a powerful way to differentiate a software application. Companies like Tableau (which raised over $250 million when it had its IPO in 2013) demonstrated an unmet need in the market. It’s all about context.
In 2013, Robert Galbraith?—?an The AIgent was built with BERT, Google’s state-of-the-art language model. In this article, I will discuss the construction of the AIgent, from data collection to model assembly. More relevant to the AIgent is Google’s BERT model, a task-agnostic (i.e. an aspiring author?—?finished
Founded in 2013, Databricks initially gained prominence for its cloud-based Apache Spark services, aimed at enhancing big data processing and creating an alternative to MapReduce. In 2013, the project was donated to the Apache Software Foundation. Databricks Assistant can be used to generate code, provide help and troubleshoot errors.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content