This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In June of 2020, Database Trends & Applications featured DataKitchen’s end-to-end DataOps platform for its ability to coordinate data teams, tools, and environments in the entire data analytics organization with features such as meta-orchestration , automated testing and monitoring , and continuous deployment : DataKitchen [link].
In addition to newer innovations, the practice borrows from model risk management, traditional model diagnostics, and software testing. Because ML models can react in very surprising ways to data they’ve never seen before, it’s safest to test all of your ML models with sensitivity analysis. [9] If so, have fun debugging! [1]
Amazon Redshift , launched in 2013, has undergone significant evolution since its inception, allowing customers to expand the horizons of data warehousing and SQL analytics. In internal tests, AI-driven scaling and optimizations showcased up to 10 times price-performance improvements for variable workloads.
Chapin shared that even though GE had embraced agile practices since 2013, the company still struggled with massive amounts of legacy systems. Don’t just run out and just buy a fancy new tool or hire that genius person who’s going to do everything.”. Success Requires Focus on Business Outcomes, Benchmarking.
In 2013, Amazon Web Services revolutionized the data warehousing industry by launching Amazon Redshift , the first fully-managed, petabyte-scale, enterprise-grade cloud data warehouse. Amazon Redshift made it simple and cost-effective to efficiently analyze large volumes of data using existing business intelligence tools.
In such cases, methods from statistical process control and operations research that rely primarily on numerical data are hard to adopt and necessitates a new approach to monitoring models in production. Step 4: Generate the test, train and noisy MNIST data sets. x_test = x_test.astype('float32') / 255.
In contrast, the decision tree classifies observations based on attribute splits learned from the statistical properties of the training data. Machine Learning-based detection – using statistical learning is another approach that is gaining popularity, mostly because it is less laborious. from imblearn.over_sampling import SMOTE.
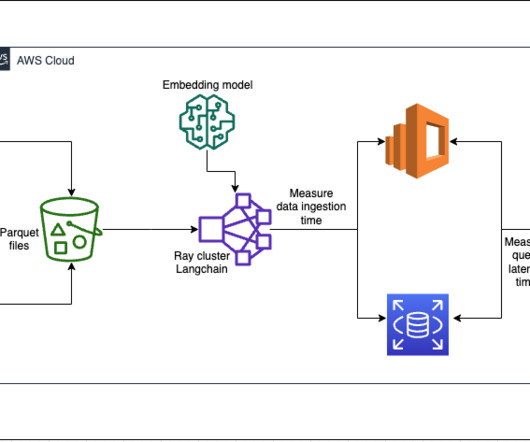
Ray cluster for ingestion and creating vector embeddings In our testing, we found that the GPUs make the biggest impact to performance when creating the embeddings. You will see the Ray dashboard and statistics of the jobs and cluster running. He entered the big data space in 2013 and continues to explore that area.
If $Y$ at that point is (statistically and practically) significantly better than our current operating point, and that point is deemed acceptable, we update the system parameters to this better value. e-handbook of statistical methods: Summary tables of useful fractional factorial designs , 2018 [3] Ulrike Groemping.
For example, you can calculate the average percentage of votes cast for Democratic Party candidates: # Compute summary statistics for the `presidentialElections` data frame average_votes <- summarize(. Using the summarize() function to calculate summary statistics for the presidentialElections data frame. Red notes are added.
Although it’s not perfect, [Note: These are statistical approximations, of course!] Note: A test set of 19,500 such analogies was developed by Tomas Mikolov and his colleagues in their 2013 word2vec paper. This test set is available at download.tensorflow.org/data/questions-words.txt.]. Example 11.6 Note: Mikolov, T.,
A “data scientist” might build a multistage processing pipeline in Python, design a hypothesis test, perform a regression analysis over data samples with R, design and implement an algorithm in Hadoop, or communicate the results of our analyses to other members of the organization in a clear and concise fashion. .”
In 2013, Robert Galbraith?—?an The most powerful approach for the first task is to use a ‘language model’ (LM), i.e. a statistical model of natural language. I tested several different flavors of BERT for use as synopsis classifiers before settling on the DistilBERT model from Hugging Face. an aspiring author?—?finished
Companies like Tableau (which raised over $250 million when it had its IPO in 2013) demonstrated an unmet need in the market. Advanced Analytics Some apps provide a unique value proposition through the development of advanced (and often proprietary) statistical models. Users’ varied needs require a shift in traditional BI thinking.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content