
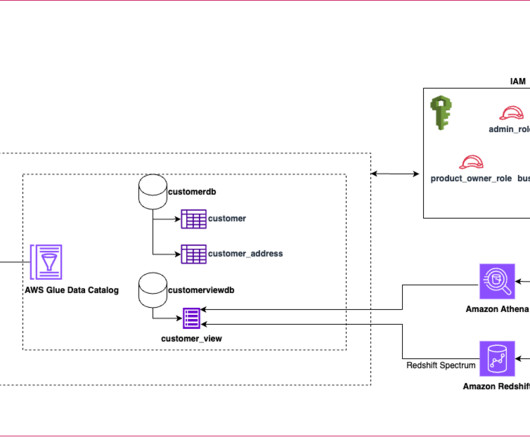
Query AWS Glue Data Catalog views using Amazon Athena and Amazon Redshift
AWS Big Data
AUGUST 8, 2024
Today’s data lakes are expanding across lines of business operating in diverse landscapes and using various engines to process and analyze data. Traditionally, SQL views have been used to define and share filtered data sets that meet the requirements of these lines of business for easier consumption. Choose Grant.























Let's personalize your content