This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A/B testing is used widely in information technology companies to guide product development and improvements. For questions as disparate as website design and UI, prediction algorithms, or user flows within apps, live traffic tests help developers understand what works well for users and the business, and what doesn’t.
Another reason to use ramp-up is to test if a website's infrastructure can handle deploying a new arm to all of its users. The website wants to make sure they have the infrastructure to handle the feature while testing if engagement increases enough to justify the infrastructure. We offer two examples where this may be the case.
One way to check $f_theta$ is to gather test data and check whether the model fits the relationship between training and test data. This tests the model’s ability to distinguish what is common for each item between the two data sets (the underlying $theta$) and what is different (the draw from $f_theta$).
After forming the X and y variables, we split the data into training and test sets. 2015) for additional details. Next, we pick a sample that we want to get an explanation for, say the first sample from our test dataset (sample id 0). For sample 23 from the test set, the model is leaning towards a bad credit prediction.
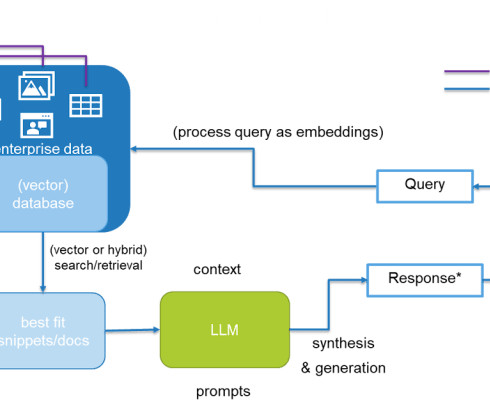
Search and knowledgediscovery technology is required for organizations to uncover, analyze, and utilize key data. Now, a new wave of AI generative AI (GenAI) is changing how forward-looking organizations approach search, knowledge management, and other forms of knowledgediscovery. How did we get here?
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













Let's personalize your content