This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The chief aim of data analytics is to apply statistical analysis and technologies on data to find trends and solve problems. Data analytics draws from a range of disciplines — including computer programming, mathematics, and statistics — to perform analysis on data in an effort to describe, predict, and improve performance.
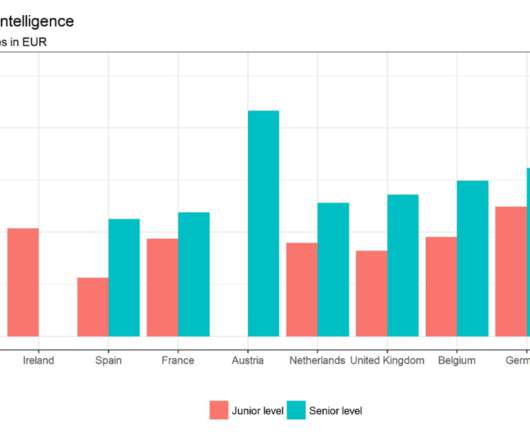
According to the US Bureau of Labor Statistics, demand for qualified business intelligence analysts and managers is expected to soar to 14% by 2026, with the overall need for data professionals to climb to 28% by the same year. The Bureau of Labor Statistics also states that in 2015, the annual median salary for BI analysts was $81,320.
Still, CIOs should not be too quick to consign the technologies and techniques touted during the honeymoon period (circa 2005-2015) of the Big Data Era to the dust bin of history. But many execs suffer from “data defeatism,” erroneously thinking that data value is dependent on having degrees in math, statistics, or machine learning.
Some of these ‘structures’ may include putting all the information; for instance, a structure could be about cars, placing them into tables that consist of makes, models, year of manufacture, and color. 17) “SQL Database Programming” (2015 Edition) By Chris Fehily. It is a must-read for understanding data warehouse design.
Get Rid of Blind Spots in StatisticalModels With Machine Learning. Data-related blind spots could also exist in your statisticalmodels. RiskSpan is a company that built a machine learning algorithm that can flag error-prone parts of a statisticalmodel and indicate which associated outputs may be unreliable.
For example, imagine a fantasy football site is considering displaying advanced player statistics. A ramp-up strategy may mitigate the risk of upsetting the site’s loyal users who perhaps have strong preferences for the current statistics that are shown. One reason to do ramp-up is to mitigate the risk of never before seen arms.
KUEHNEL, and ALI NASIRI AMINI In this post, we give a brief introduction to random effects models, and discuss some of their uses. Through simulation we illustrate issues with model fitting techniques that depend on matrix factorization. Random effects models are a useful tool for both exploratory analyses and prediction problems.
SCOTT Time series data are everywhere, but time series modeling is a fairly specialized area within statistics and data science. This post describes the bsts software package, which makes it easy to fit some fairly sophisticated time series models with just a few lines of R code. by STEVEN L. Forecasting (e.g.
Most Deep Learning methods involve artificial neural networks, modeling how our bran works. There are some who believe that anything modeled on the human brain, like Deep Learning, will be limited in it’s intelligence, that it will inherit the limits and flaws that our intelligence possesses. Yes, a silo but so much better than 2015.
Spreading the news Telecom provider AT&T began trialing RPA in 2015 to decrease the number of repetitive tasks, such as order entry, for its service delivery group. GPT-4 (Generative Pre-trained Transformer 4) is a multimodal large language model created by OpenAI, an AI research laboratory. Secure sponsorship.
You know the markets shake and the accompanying Swine Flu epidemic of 2015 and 2016, the Japanese tsunami and the Thailand floods in 2011 that shook up the high-tech value chain quite a bit, the great financial crisis and the accompanying H1N1 outbreak in 2008-2009, MERS and SARS before that in 2003. As the crisis evolved.
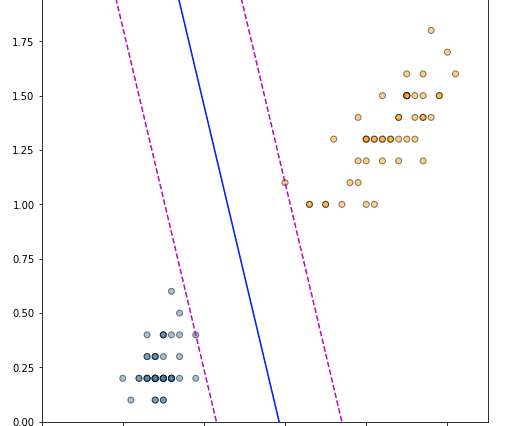
If $Y$ at that point is (statistically and practically) significantly better than our current operating point, and that point is deemed acceptable, we update the system parameters to this better value. Figure 2: Spreading measurements out makes estimates of model (slope of line) more accurate. And sometimes even if it is not[1].)
The field of AI includes planning and learning, natural language processing (NLP) and machine learning, as well as reasoning and perception, neural networks, economics, mathematics and statistics. Its training model is huge, consisting of many terabytes of text data. GPT is an LLM. GPT is open-source. OpenAI offers ChatGPT services.
Identification We now discuss formally the statistical problem of causal inference. We start by describing the problem using standard statistical notation. The choice of space $cal F$ (sometimes called the model ) and loss function $L$ explicitly defines the estimation problem. For a random sample of units, indexed by $i = 1.
To address these needs, a catalog should provide data samples and statistical profiles, lineage, lists of users and stewards, and tips on how the data should be interpreted. LinkedIn provides a good model. Prescriptive vs. Descriptive. This method is also slow, and the documentation often gets stale. The Bottom Line.
Banking, transportation, healthcare, retail, and real estate, all have seen the emergence of new business models fundamentally changing how customers use their services. Bridgespan Group estimated in 2015 that only 6% of nonprofits use data to drive improvements in their work.
By contrast, traditional BI platforms are designed to support modular development of IT-produced analytic content, specialized tools and skills, and significant upfront data modeling, coupled with a predefined metadata layer, is required to access their analytic capabilities. Answer: Better than every other vendor?
Machine learning engineers take massive datasets and use statistical methods to create algorithms that are trained to find patterns and uncover key insights in data mining projects. It advances the scalability of ML in real-world applications by using algorithms to improve model performance and reproducibility. Where they are deployed.
The base skills you need to master to conduct analysis in Excel include: Modeling design principles Common functions and formulas Excel Tables Pivot Tables & Pivot Charts Charts & Graphs Learning the above is an entry point and is the start of one’s journey working with and analyzing data. The beauty of Modern Excel is two-fold.
Support Vector Machines (SVMs) are supervised learning models with a wide range of applications in text classification (Joachims, 1998), image recognition (Decoste and Schölkopf, 2002), image segmentation (Barghout, 2015), anomaly detection (Schölkopf et al., 1999) and more. References. Barghout, L. Pedrycz & S.-M. Rouveirol (Eds.),
Statistical power is traditionally given in terms of a probability function, but often a more intuitive way of describing power is by stating the expected precision of our estimates. This is a quantity that is easily interpretable and summarizes nicely the statistical power of the experiment.
Also, clearly there’s no “one size fits all” educational model for data science. Laura Noren, who runs the Data Science Community Newsletter , presented her NYU postdoc research at JuptyerCon 2018, comparing infrastructure models for data science in research and education. Joel Grus (2015). Pedro Domingos (2015).
A data fabric has the same model but it adds a set of capabilities that continuously monitor the whole landscape, and continuously update the intelligent part that infers insight as new data is discovered and/or added. This was not statistic and we have not really explored this in any greater detail since. I suspect we should.
Our mental model has not shifted enough to the existing reality. AND you can have analysis of your risk in almost real time to get an early read and in a few days with statistical significance! So do the 7 things above, but ensure you have a clearly articulated Digital Marketing & Measurement Model. Got your own?
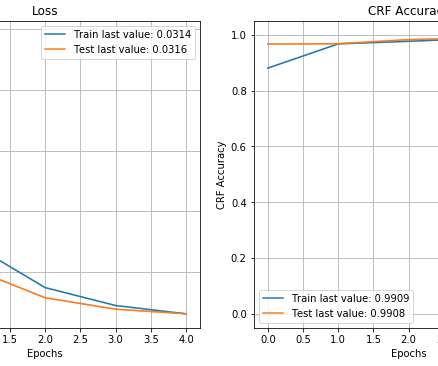
In this blog post we present the Named Entity Recognition problem and show how a BiLSTM-CRF model can be fitted using a freely available annotated corpus and Keras. The model achieves relatively high accuracy and all data and code is freely available in the article. How to build a statistical Named Entity Recognition (NER) model.
Recall from my previous blog post that all financial models are at the mercy of the Trinity of Errors , namely: errors in model specifications, errors in model parameter estimates, and errors resulting from the failure of a model to adapt to structural changes in its environment.
This trend is prevalent in the US, UK and further afield, with the former’s Bureau of Labour Statistics reporting that three of the jobs with the highest forecast growth level are wind turbine technician, registered nurse, and solar technician.
From 2000 to 2015, I had some success [5] with designing and implementing Data Warehouse architectures much like the following: As a lot of my work then was in Insurance or related fields, the Analytical Repositories tended to be Actuarial Databases and / or Exposure Management Databases, developed in collaboration with such teams.
Diving into examples of building and deploying ML models at The New York Times including the descriptive topic modeling-oriented Readerscope (audience insights engine), a prediction model regarding who was likely to subscribe/cancel their subscription, as well as prescriptive example via recommendations of highly curated editorial content.
1) What Is A Misleading Statistic? 2) Are Statistics Reliable? 3) Misleading Statistics Examples In Real Life. 4) How Can Statistics Be Misleading. 5) How To Avoid & Identify The Misuse Of Statistics? If all this is true, what is the problem with statistics? What Is A Misleading Statistic?
Interpretation of our machine learning model suggests buying $50k in building coverage and $100k in warehouse content coverage, as the latter significantly boosts predicted flood claim payouts. When exploring river and coastal flooding for the USA on a city level, river flooding area had a drastic increase starting from 2015.
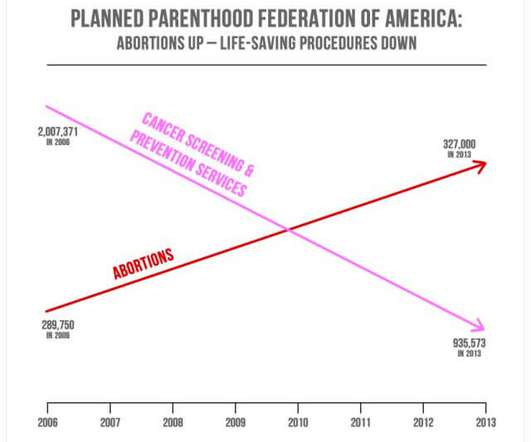
From political issues to sports statistics and the recent report you received on the ROI of your company blog, the internet as well as informational reports are flooded with examples of misleading data visualization. If you want to go deeper into the topic, take a look at our misleading statistics blog post. Correlating Causation.
5: What-if Analysis Models. allow for smart elements like modeling. Strategy 5: What-if Analysis Models. Building on the thought above, if you create exploratory environments it can be exceedingly accretive to decision-making if we build in what-if type models. 2: If Complex, Focus! 3: Venn Diagrams FTW! That’s the key.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content