This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
These fleshed-out web applications are representative end products of datascience work. Ines Montani of Explosion wrote How front-end development can improve datascience in 2016, and, five years later, those words still ring true. This is fortunate, because few data scientists are web developers on the side.
With the year coming to a close, many look back at the headlines that made major waves in technology and big data – from Spark to Hadoop to trends in datascience – the list could go on and on. Venky Ganti, CTO & Co-Founder: Data sprawl will finally hit its threshold.
We wrote the first version because, after talking with hundreds of people at the 2016 Strata Hadoop World Conference, very few easily understood what we discussed at our booth and conference session. I spent much time de-categorizing DataOps: we are not discussing ETL, Data Lake, or DataScience. Why should I care?
But according to the UK’s Turing Institute, a national center for datascience and AI, the predictive tools made little to no difference. In March 2016, Microsoft learned that using Twitter interactions as training data for machine learning algorithms can have dismaying results.
It’s giving companies an opportunity to rethink how they interact with customers, connect with supply chains, and drive internal operational efficiencies. I joined Baxter as CIO in 2011, and in 2016 I was presented with the opportunity to join my first public company board. How did that opportunity come about?
From 2016 to 2022, the company went from processing a payments volume of $354 billion to $1.36 The fourth is called the merchant, consumer, and developer experience layer, which includes the web interface, mobile applications, and APIs that allow customers to use PayPal’s service interactively and programmatically. trillion last year.
While the phrase Artificial Intelligence has been around since the first human wondered if she could go further if she had access to entities with inorganic intelligence, it truly jumped the shark in 2016. trillion pictures in 2016. One key thing that stymied my efforts, and likely your ML efforts, in 2016 was Identity.
Furthermore, datascience modeling, which is also largely manual, requires specialist skills that are in short supply at time when insights from advanced analytics must be pervasive to fuel digital business transformation. It will transform how users interact with data, and how they consume and act on insights.
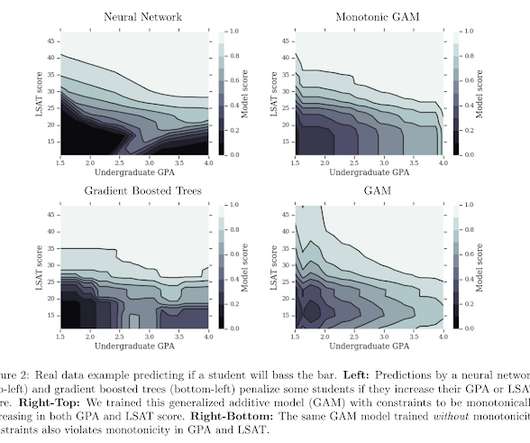
TF Lattice offers semantic regularizers that can be applied to models of varying complexity, from simple Generalized Additive Models, to flexible fully interacting models called lattices, to deep models that mix in arbitrary TF and Keras layers. The drawback of GAMs is that they do not allow feature interactions.
Paco Nathan ‘s latest monthly article covers Sci Foo as well as why datascience leaders should rethink hiring and training priorities for their datascience teams. In this episode I’ll cover themes from Sci Foo and important takeaways that datascience teams should be tracking. Introduction.
These business users have adopted business intelligence and advanced analytical tools to gather and analyze data from varied data sources and use that analysis to identify the root cause of problems, identify opportunities, solve problems and share crucial data to support business decisions.
The Definition and Evolution of the Citizen Data Scientist Role The world-renowned technology research firm, Gartner, first introduced the concept of the Citizen Data Scientist in 2016. Citizen Data Scientist candidates may also be IT team members who are interested in datascience.
The first project we did used NLP for finance contracts (this was 2016). I get to interact with really amazing people and because the signal to noise ratio is so high, they interact back. By random chance, we were looking for technical help in Finance and a research lab was looking for meaningful projects.
In Paco Nathan ‘s latest column, he explores the theme of “learning datascience” by diving into education programs, learning materials, educational approaches, as well as perceptions about education. He is also the Co-Chair of the upcoming DataScience Leaders Summit, Rev. Learning DataScience.
The reason they can do this is simple: the tools provided for this purpose are designed for human interaction. Ask a question about a point in time without the need for specific dates: How many silk blouses were sold during Christmas season in 2016 vs. 2018? They know how to search for something on Google and get the results they need.
What is a Citizen Data Scientist, What is Their Role, What are the Benefits of Citizen Data Scientists…and More! The term, ‘Citizen Data Scientist’ has been around for a number of years. In fact, the world-renowned technology research firm, Gartner, first introduced the concept in 2016.
A few things: Tackle bias not just in your data, but also be aware it can result from how the data is interpreted, used, or interacted with by users Lean into open source tools and datascience. Chet successfully took Apigee public before the company was acquired by Google in 2016. Chet earned his B.S.
Special thanks to Addison-Wesley Professional for permission to excerpt the following “Manipulating data with dplyr” chapter from the book, Programming Skills for DataScience: Start Writing Code to Wrangle, Analyze, and Visualize Data with R. Data scientists spend countless hours wrangling data.
Eighty percent of this problem is collecting the data and then transforming the data. The other 20 percent is ML- and datascience–related tasks like finding the right model, doing EDA, and feature engineering. Gathering the Data. there is a list of data sources to extract and transform. In Figure 6.1,
Gartner revamped the BI and Analytics Magic Quadrant in 2016 to reflect the mainstreaming of this market disruption. Not sure about that, but Sisense is well suited for easily harmonizing, combining and modeling many different, complex and large data sets for fast interactive analysis. Answer: Better than every other vendor?
Data scientists and researchers require an extensive array of techniques, packages, and tools to accelerate core work flow tasks including prepping, processing, and analyzing data. Utilizing NLP helps researchers and data scientists complete core tasks faster. Interactive bokeh plot of two-dimensional word-vector data.
However, if we experiment with both parameters at the same time we will learn something about interactions between these system parameters. Interactions between parameters in different YouTube recommendation subsystems definitely exist, but important interactions and quadratic effects seem relatively rare. 17:263-287, 2016. [10]
Often our data can be stored or visualized as a table like the one shown below. Column "a" is an advertiser id, "b" is a web site, and "c" is the 'interaction' of columns "a" and "b". $y$ Now for the $j$th row of data we define the index of the feature "a" as $I_a(j) in {1, 2,, mbox{#advertisers} }$. hi-fly-airlines 123.com
The need for interaction – complex decision making systems often rely on Human–Autonomy Teaming (HAT), where the outcome is produced by joint efforts of one or more humans and one or more autonomous agents. 2016) for an example of this technique (LIME). Toy example to present intuition for LIME from Ribeiro (2016).
As data scientists, machine learning engineers, and AI practitioners, we should be aware of the behaviors of the models we build and check them for biases toward certain attributes, such as race or sex. Want to advance your career in DataScience and Artificial Intelligence? Feel free to get in touch.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content