This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With the big data revolution of recent years, predictive models are being rapidly integrated into more and more business processes. When business decisions are made based on bad models, the consequences can be severe. As machine learning advances globally, we can only expect the focus on model risk to continue to increase.
The excerpt covers how to create word vectors and utilize them as an input into a deep learning model. While the field of computational linguistics, or Natural Language Processing (NLP), has been around for decades, the increased interest in and use of deep learning models has also propelled applications of NLP forward within industry.
The company has been bundling various forms of automation into its Einstein brand since 2016. This year, however, Salesforce has accelerated its agenda, integrating much of its recent work with large language models (LLMs) and machine learning into a low-code tool called Einstein 1 Studio. This isn’t a new push for Salesforce.
While the phrase Artificial Intelligence has been around since the first human wondered if she could go further if she had access to entities with inorganic intelligence, it truly jumped the shark in 2016. trillion pictures in 2016. Most Deep Learning methods involve artificial neural networks, modeling how our bran works.
The transformation, which started in partnership with Microsoft in 2016, is also enabling LaLiga to expand its business by offering technology platforms and services to the sports and entertainment industry at large. It has also developed predictive models to detect trends, make predictions, and simulate results.
Currently, popular approaches include statistical methods, computational intelligence, and traditional symbolic AI. This feature hierarchy and the filters that model significance in the data, make it possible for the layers to learn from experience.
SCOTT Time series data are everywhere, but time series modeling is a fairly specialized area within statistics and data science. This post describes the bsts software package, which makes it easy to fit some fairly sophisticated time series models with just a few lines of R code. by STEVEN L. Forecasting (e.g.
Belcorp operates under a direct sales model in 14 countries. The second stage focused on building algorithms and models to predict and simulate intricate biological conditions, accelerate discoveries, reduce risks, and optimize the cost-benefit ratio of technological developments using AI solutions.
A big part of statistics, particularly for financial and econometric data, is analyzing time series, data that are autocorrelated over time. One of the most common ways of fitting time series models is to use either autoregressive (AR), moving average (MA) or both (ARMA). Chapter Introduction: Time Series and Autocorrelation.
As you may already know In-database Analytics (also known as Advanced Analytics) is available in SQL Server 2016. To simplify, “In-database Advanced Analytics”: you can run powerful statistical / predictive modelling (from R) inside SQL Server. Read the official definition here. Check Out SQL Latest Bits.
by TAMAN NARAYAN & SEN ZHAO A data scientist is often in possession of domain knowledge which she cannot easily apply to the structure of the model. On the one hand, basic statisticalmodels (e.g. On the other hand, sophisticated machine learning models are flexible in their form but not easy to control.
KUEHNEL, and ALI NASIRI AMINI In this post, we give a brief introduction to random effects models, and discuss some of their uses. Through simulation we illustrate issues with model fitting techniques that depend on matrix factorization. Random effects models are a useful tool for both exploratory analyses and prediction problems.
To develop the project, Fearless leveraged Smithsonian’s APIs to access a massive catalog of digital content, including 3D models, videos, podcasts, and imagery not available in the physical building in order to create an immersive, rich experience that rivals a walk-through.
Then in around 2016, I first started using VR hardware and from there I had two thoughts: first, that VR is going to be the most revolutionary technology of my lifetime; and second, that VR can make the process of data analysis and presentation much easier (especially in my job as an investment analyst).
As you may already know In-database Analytics (also known as Advanced Analytics) is available in SQL Server 2016. To simplify, “In-database Advanced Analytics”: you can run powerful statistical / predictive modelling (from R) inside SQL Server. Read the official definition here. Check Out SQL Latest Bits.
Meanwhile, many organizations also struggle with “late in the pipeline issues” on model deployment in production and related compliance. Having participated in several Foo Camps—and even co-chaired the Ed Foo series in 2016-17— most definitely, a Foo will turn your head around. Rinse, lather, repeat—probably each week.
You know the markets shake and the accompanying Swine Flu epidemic of 2015 and 2016, the Japanese tsunami and the Thailand floods in 2011 that shook up the high-tech value chain quite a bit, the great financial crisis and the accompanying H1N1 outbreak in 2008-2009, MERS and SARS before that in 2003. As the crisis evolved.
Our first data source says that on June 13, 2016 Microsoft bought LinkedIn , while the second – that Microsoft bought LinkedIn for $28.1 Beyond training, each and every AI system, be it based on symbolic rules or statisticalmodels, has to be evaluated, in the same way children take exams to graduate.
If $Y$ at that point is (statistically and practically) significantly better than our current operating point, and that point is deemed acceptable, we update the system parameters to this better value. Figure 2: Spreading measurements out makes estimates of model (slope of line) more accurate. And sometimes even if it is not[1].)
As a result, there has been a recent explosion in individual statistics that try to measure a player’s impact. This chapter will explore the numbers behind the numbers using ML and then creating an API to serve out the ML model. All of this will be done in the spirit of solving real-world problems in a real-world way. In Figure 6.1,
Decision Model and Notation (DMN) is an open industry standard, designed to be a common and standard bridge between what you need a business decision to do and the decision implementation for how it actually happens. Structural Principles TDM’s structural principles (1-7) are around the representation of tabular logic.
Typically, causal inference in data science is framed in probabilistic terms, where there is statistical uncertainty in the outcomes as well as model uncertainty about the true causal mechanism connecting inputs and outputs. We are all familiar with linear and logistic regression models.
The Definition and Evolution of the Citizen Data Scientist Role The world-renowned technology research firm, Gartner, first introduced the concept of the Citizen Data Scientist in 2016. Since then, the idea has grown in popularity, and the role has grown in importance and prominence. ‘To Who is a Citizen Data Scientist ?
Citizen Analysts create and generate data models and use sophisticated analytics that are supported by easy-to-use interactive BI dashboards. By definition, Citizen Analysts are not data scientists, or professional analysts or IT staff. ’ Clearly, Citizen Analysts are here to stay!
Gartner revamped the BI and Analytics Magic Quadrant in 2016 to reflect the mainstreaming of this market disruption. Not sure about that, but Sisense is well suited for easily harmonizing, combining and modeling many different, complex and large data sets for fast interactive analysis. Answer: Better than every other vendor?
This data set contains the percentage of votes that were cast in each state for the Democratic Party candidate in each presidential election from 1932 to 2016. Using the summarize() function to calculate summary statistics for the presidentialElections data frame. For more information, see the pscl package reference manual , or use ?
A data fabric has the same model but it adds a set of capabilities that continuously monitor the whole landscape, and continuously update the intelligent part that infers insight as new data is discovered and/or added. This was not statistic and we have not really explored this in any greater detail since. I suspect we should.
In fact, the world-renowned technology research firm, Gartner, first introduced the concept in 2016. Gartner defines a citizen data scientist as, ‘ a person who creates or generates models that leverage predictive or prescriptive analytics, but whose primary job function is outside of the field of statistics and analytics.’
Also, clearly there’s no “one size fits all” educational model for data science. Laura Noren, who runs the Data Science Community Newsletter , presented her NYU postdoc research at JuptyerCon 2018, comparing infrastructure models for data science in research and education. Jake Vanderplas (2016). Chris Albon (2018). Think Stats.
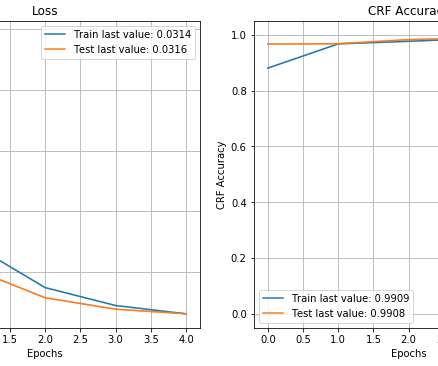
In this blog post we present the Named Entity Recognition problem and show how a BiLSTM-CRF model can be fitted using a freely available annotated corpus and Keras. The model achieves relatively high accuracy and all data and code is freely available in the article. How to build a statistical Named Entity Recognition (NER) model.
Before the advent of broadcast media and mass culture, individuals’ mental models of the world were generated locally, along with their sense of reality and what they considered ground truth. ” Reality Decentralized. What has happened? Reality has once again become decentralized.
Bonus #2: The Askers-Pukers Business Model. Econsultancy/Lynchpin provides this description in the report: "There were 960 respondents to our research request, which took the form of a global online survey fielded in May and June 2016. Ok, maybe statisticalmodeling smells like an analytical skill. Bottom-line.
Recall from my previous blog post that all financial models are at the mercy of the Trinity of Errors , namely: errors in model specifications, errors in model parameter estimates, and errors resulting from the failure of a model to adapt to structural changes in its environment.
1) What Is A Misleading Statistic? 2) Are Statistics Reliable? 3) Misleading Statistics Examples In Real Life. 4) How Can Statistics Be Misleading. 5) How To Avoid & Identify The Misuse Of Statistics? If all this is true, what is the problem with statistics? What Is A Misleading Statistic?
It was lately revised and updated in January 2016. With a very strong practical focus “Analytics in a Big Data World” starts by providing the readers with the basic nomenclature, the analytics process model, and its relation to other relevant disciplines, such as statistics, machine learning, and artificial intelligence.
In 2016, the technology research firmGartnercoined the term citizen data scientist, defining it as a person who creates or generates models that leverage predictive or prescriptive analytics, but whose primary job function is outside of the field of statistics and analytics.
In 2016, the technology research firm, Gartner, coined the term Citizen Data Scientist, and defined it as a person who creates or generates models that leverage predictive or prescriptive analytics, but whose primary job function is outside of the field of statistics and analytics.
5: What-if Analysis Models. allow for smart elements like modeling. Strategy 5: What-if Analysis Models. Building on the thought above, if you create exploratory environments it can be exceedingly accretive to decision-making if we build in what-if type models. 2: If Complex, Focus! 3: Venn Diagrams FTW! That’s the key.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content