This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The risk of data breaches will not decrease in 2021. Data breaches and security risks happen all the time. One bad breach and you are potentially risking your business in the hands of hackers. In this blog post, we discuss the key statistics and prevention measures that can help you better protect your business in 2021.
This provides a great amount of benefit, but it also exposes institutions to greater risk and consequent exposure to operational losses. The stakes in managing model risk are at an all-time high, but luckily automated machine learning provides an effective way to reduce these risks. What is a model?
Fraud remains a major risk for banks, and is only set to increase as people become more open with their data. According to Financial Regulation News, banks lost $2.2bn to fraud throughout 2016, as revealed by the most recently collated statistics. Minimizing fraudulent behavior.
After a marginal increase in 2015, another steep rise happened in 2016 through 2017 before the volume decreased in 2018 and rose in 2019, and dropped again in 2020. They can use AI and data-driven cybersecurity technology to address these risks. By 2012, there was a marginal increase, then the numbers rose steeply in 2014. In summary.
While the phrase Artificial Intelligence has been around since the first human wondered if she could go further if she had access to entities with inorganic intelligence, it truly jumped the shark in 2016. trillion pictures in 2016. One key thing that stymied my efforts, and likely your ML efforts, in 2016 was Identity.
KPMG, for example, built its first interactive chatbot in 2016. KPMG calculates a score for an employee’s risk of attrition, tries to identify a reason for that, and then suggests a remediation. More recently, they’ve been exploring the use of interactive chatbots to check the pulse of employee sentiment at work.
Finally, our goal is to diminish consumer risk evaluation periods by 80% without compromising the safety of our products.” It’s worth noting that each initiative carried its own unique complexity, such as varying data sizes, data variety, statistical and computational models, and data mining processing requirements.
It is even more essential now that supply chains are empowered with a high standard of data and analytics sophistication to be able to cost-effectively serve the company’s purpose and combat risks at the same time. You know, Chief Risk Officers, for example, will no longer be confined to the credit industry. Anushruti: Perfect.
Bread-and-butter competencies like technology integration/implementation, IT cloud architecture, and risk/security management were most often called by CIO respondents as most in demand. Internal talent is gold, and we’re making sure our current employees find places to grow and modernize their skill sets.”
Having participated in several Foo Camps—and even co-chaired the Ed Foo series in 2016-17— most definitely, a Foo will turn your head around. The probabilistic nature changes the risks and process required. They tend to use less machine learning, but more advanced statistical practices, since the outcomes (government policies, etc.)
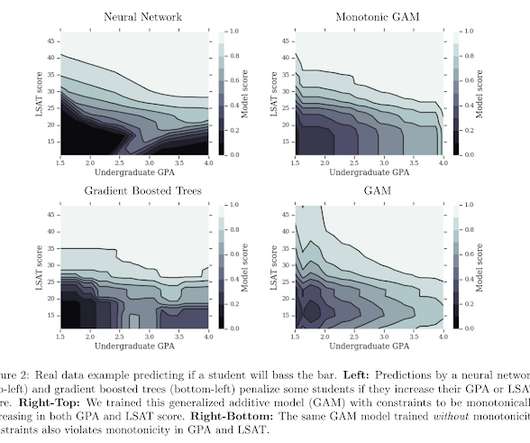
On the one hand, basic statistical models (e.g. In our case, it turns out that the monotonicity regularizer allows us to increase the number of knots without incurring much risk of overfitting there are fewer ways for the model to go wrong. linear regression, trees) can be too rigid in their functional forms. Pfeifer, J., Voevodski, K.,
If $Y$ at that point is (statistically and practically) significantly better than our current operating point, and that point is deemed acceptable, we update the system parameters to this better value. And we can keep repeating this approach, relying on intuition and luck.
Gartner revamped the BI and Analytics Magic Quadrant in 2016 to reflect the mainstreaming of this market disruption. The risk of switching existing system of record reporting that is working may be higher than the benefit, so the 45% of you maintaining these systems makes sense, but increasing users and content?
In fact, the world-renowned technology research firm, Gartner, first introduced the concept in 2016. Gartner defines a citizen data scientist as, ‘ a person who creates or generates models that leverage predictive or prescriptive analytics, but whose primary job function is outside of the field of statistics and analytics.’
What are the projected risks for companies that fall behind for internal training in data science? Jake Vanderplas (2016). How do options such as mentoring programs fit into this picture, both for organizations and for the individuals involved? In business terms, why does this matter ? Machine Learning with Python Cookbook.
– We did some early work a few years ago that look at the career path of a CDO – see from 2016 Build Your Career Path to the Chief Data Officer Role. This was not statistic and we have not really explored this in any greater detail since. 2016) though I have followed the topic in retail and CPG for years.
We develop an ordinary least squares (OLS) linear regression model of equity returns using Statsmodels, a Python statistical package, to illustrate these three error types. CI theory was developed around 1937 by Jerzy Neyman, a mathematician and one of the principal architects of modern statistics.
1) What Is A Misleading Statistic? 2) Are Statistics Reliable? 3) Misleading Statistics Examples In Real Life. 4) How Can Statistics Be Misleading. 5) How To Avoid & Identify The Misuse Of Statistics? If all this is true, what is the problem with statistics? What Is A Misleading Statistic?
The book has three main ideas: The biggest risk your company faces is investing a lot of time and resources into building something that the market doesn’t want. It was lately revised and updated in January 2016. Product/market fit is THE most important factor to get right.
We know, statistically, that doubling down on an 11 is a good (and common) strategy in blackjack. The quality of the decision is based on known information and an informed risk assessment, while chance involves hidden information and the stochasticity of the world. We saw this after the 2016 U.S.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content