This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Welcome into the world of Transformers, the deeplearning model that has transformed Natural Language Processing (NLP) since its debut in 2017. These linguistic marvels, armed with self-attention mechanisms, revolutionize how machines understand language, from translating texts to analyzing sentiments.
Note: This article was originally published on May 29, 2017, and updated on July 24, 2020 Overview Neural Networks is one of the most. The post Understanding and coding Neural Networks From Scratch in Python and R appeared first on Analytics Vidhya.
In 2017, we published “ How Companies Are Putting AI to Work Through DeepLearning ,” a report based on a survey we ran aiming to help leaders better understand how organizations are applying AI through deeplearning. We found companies were planning to use deeplearning over the next 12-18 months.
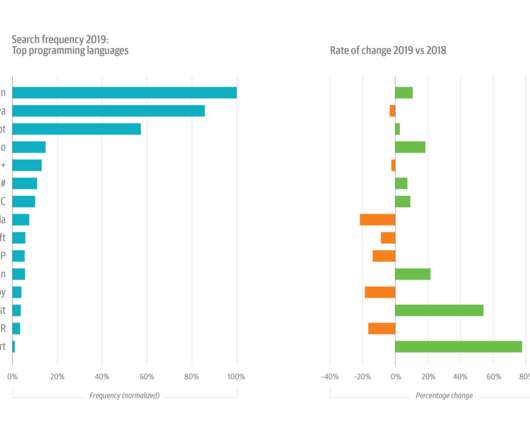
Up until 2017, the ML+AI topic had been amongst the fastest growing topics on the platform. In 2019, as in 2018, Python was the most popular language on O’Reilly online learning. After several years of steady climbing—and after outstripping Java in 2017—Python-related interactions now comprise almost 10% of all usage.
AI Singapore is a national AI R&D program, launched in May 2017. AIAP in the beginning: Goals and challenges The AIAP started back in 2017 when I was tasked to build a team to do 100 AI projects. To do that, I needed to hire AI engineers.
Being Human in the Age of Artificial Intelligence” “An Introduction to Statistical Learning: with Applications in R” (7th printing; 2017 edition). Being Human in the Age of Artificial Intelligence” “An Introduction to Statistical Learning: with Applications in R” (7th printing; 2017 edition).
A team at Google Brain developed Transformers in 2017, and they are now replacing RNN models like long short-term memory(LSTM) as the model of choice for NLP […]. This article was published as a part of the Data Science Blogathon. The post Test your Data Science Skills on Transformers library appeared first on Analytics Vidhya.
An overview from a 2017 paper from Google lets us gauge how much tooling is still needed for model operations and testing. Machine learning engineers , data engineers, developers, and domain experts are critical to the success of ML projects. Becoming a machine learning company means investing in foundational technologies”.
Relevant job roles include machine learning engineer, deeplearning engineer, AI research scientist, NLP engineer, data scientists and analysts, AI product manager, AI consultant, AI systems architect, AI ethics and compliance analyst, among others.
They are (rightfully) getting the attention of a big portion of the deeplearning community and researchers in Natural Language Processing (NLP) since their introduction in 2017 by the Google Translation Team.
AI’s evolution: Machine learning, deeplearning, GenAI AI encompasses a suite of rapidly evolving technologies. It’s a journey that started in earnest during the early 2000s with machine learning (ML). Then came deeplearning in the 2010s, further enhancing perception capabilities in computer vision.
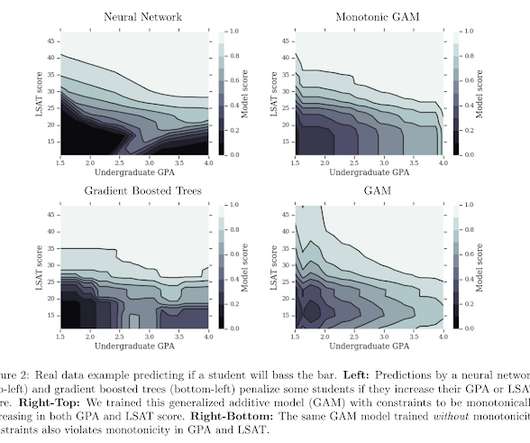
Monotonic Deep Lattice Networks Deeplearning is a powerful tool when we have an abundance of data to learn from. In this section, we extend the ideas of building monotonic GAMs and lattice models to construct monotonic deeplearning models. Other deeplearning models can also be written in this form.
DeepLIFT was recently proposed as a recursive prediction explanation method for deeplearning [8, 7]. Provides local explainability only No control over the concepts these maps pick Saliency maps produced by randomized networks are similar to that of the trained network (Adebayo et al., On to Concept Extraction and Building.
An important part of artificial intelligence comprises machine learning, and more specifically deeplearning – that trend promises more powerful and fast machine learning. billion in 2017 to $190.61 They indeed enable you to see what is happening at every moment and send alerts when something is off-trend.
The third layer, Cropin Intelligence, uses the company’s 22 prebuilt AI and deep-learning models to provide insights about crop detection, crop stage identification, yield estimation, irrigation scheduling, pest and disease prediction, nitrogen uptake, water stress detection, harvest date estimation, and change detection, among others.
Whether you are an aspiring or seasoned data professional, continuing to learn new data science skills is essential to staying relevant (being employed). Data Science/Analytics Tools, Technologies and Languages used in 2017. Looking ahead to 2018, data professionals are most interested in learningdeeplearning (41%).
It seems that “deeplearning” and GPUs fit well for AI/machine learning uses. China also has a reasonable path to doing so (Russia not so much), in line with the “Lots of data makes models strong” line of argument. I see no natural barriers to that trend, assuming it holds up on its own merits.
the OpenAI model on which ChatGPT is based, is an example of a transformer, a deeplearning technique developed by Google in 2017 to tackle problems in natural language processing. Others include BERT and PaLM from Google; and MT-NLG, which was co-developed by Microsoft and Nvidia.
Part of the back-end processing needs deeplearning (graph embedding) while other parts make use of reinforcement learning. For more background about program synthesis, check out “ Program Synthesis Explained ” by James Bornholt from 2015, as well as the more recent “ Program Synthesis in 2017-18 ” by Alex Polozov from 2018.
Lilly Translate uses NLP and deeplearning language models trained with life sciences and Lilly content to provide real-time translation of Word, Excel, PowerPoint, and text for users and systems.
A transformer is a type of AI deeplearning model that was first introduced by Google in a research paper in 2017. ChatGPT is a product of OpenAI. It’s only one example of generative AI. GPT stands for generative pre-trained transformer.
Tomorrow Sleep was launched in 2017 as a sleep system startup and ventured on to create online content in 2018. eBay then decided to employ Phrasee – an AI-powered copywriting tool that uses natural language generation and deeplearning. Tomorrow Sleep Achieved 10,000% Increase in Web Traffic.
In 2017, The Economist declared that data, rather than oil, had become the world’s most valuable resource. Derek Driggs, a machine learning researcher at the University of Cambridge, together with his colleagues, published a paper in Nature Machine Intelligence that explored the use of deeplearning models for diagnosing the virus.
It’s important to note that machine learning for natural language got a big boost during the mid-2000’s as Google began to win international language translation competitions. The use cases for natural language have shifted dramatically over the past two years, after deeplearning techniques arose to the fore.
The Future of Life Institute hosted a conference in Asilomar in Jan 2017 with just such a purpose. The entire list of videos is well worth watching, prioritize the individual ones: Beneficial AI 2017. Intro to Machine Learning. Machine Learning. DeepLearning. This is not the future, it is Nov 2017.
Selon la firme PwC Canada , les sommes investies ont dépassé les 800 millions de dollars entre 2017 et 2021, dont 500 millions du gouvernement fédéral. Artificial Intelligence, DeepLearning Les investissements gouvernementaux ont aussi contribué à mettre l’IA québécoise en orbite.
How we got here The most notable enabling technologies in generative AI are deeplearning, embeddings, transfer learning (all of which emerged in the early to mid-2000s), and neural net transformers (invented in 2017). One of the most important of such architectures, the “transformer,” was developed in 2017.
State-of-the-art pre-training for natural language processing with BERT Javed Qadrud-Din was an Insight Fellow in Fall 2017. He is currently a machine learning engineer at Casetext where he works on natural language processing for the legal industry. Prior to Insight, he was at IBM Watson.
With that said, recent advances in deeplearning methods have allowed models to improve to a point that is quickly approaching human precision on this difficult task. LSTMs and other recurrent neural networks RNNs are probably the most commonly used deeplearning models for NLP and with good reason. More advanced models.
Nel 2017, The Economist ha dichiarato [in inglese] che i dati, alla pari del petrolio, sono diventati la risorsa più preziosa del mondo e, da allora, questo stesso ritornello è stato ripetuto più volte. Le aziende di tutti i settori hanno investito e continuano a investire pesantemente in dati e analisi.
Humans likely not even notice the difference but modern deeplearning networks suffered a lot. But apparently, models trained on text from 2017 experience degraded performance on text written in 2018. Images off the web tend to frame the object in question. We might expect that.
The latter is particularly restricting, as it violates the prerequisite of many deeplearning methods for image classification?—?a In a narrower sense, meta-learning is a class of methods that “learn how to learn” by being “exposed to a large number of tasks” in training, then “tested in their ability to learn new tasks (Finn, 2017).”
Our analysis of ML- and AI-related data from the O’Reilly online learning platform indicates: Unsupervised learning surged in 2019, with usage up by 172%. Deeplearning cooled slightly in 2019, slipping 10% relative to 2018, but deeplearning still accounted for 22% of all AI/ML usage.
We find ways to improve machine learning so that it requires orders of magnitude more data, e.g., deeplearning with neural networks. See also the paper “ The Case for Open Metadata ” by Mandy Chessell (2017–04–21) at IBM UK for compelling perspectives about open metadata. In short, the virtuous cycle is growing.
So, we used a form of the Term Frequency-Inverse Document Frequency (TF/IDF) technique to identify and rank the top terms in this year’s Strata NY proposal topics—as well as those for 2018, 2017, and 2016. 2) is unchanged from Strata NY 2018, it’s up three places from Strata NY 2017—and eight places relative to 2016. 221) to 2019 (No.
The interest in interpretation of machine learning has been rapidly accelerating in the last decade. This can be attributed to the popularity that machine learning algorithms, and more specifically deeplearning, has been gaining in various domains. Methods for explaining DeepLearning. References.
Other good related papers include: “ Towards A Rigorous Science of Interpretable Machine Learning ”. Finale Doshi-Velez, Been Kim (2017-02-28) ; see also the Domino blog article about TCAV. Adrian Weller (2017-07-29). “ Here’s a video of an earlier version of her talk at NeurIPS 2017, and her related slides from ScaledML.
In Figure 1, you can see the results of the Harris corner detector applied to an image of Jessie Graff competing in the 2017 American Ninja Warrior Finals: Figure 1?—?Harris Harris corner detection applied to an image of Jessie Graff competing in the 2017 American Ninja Warrior Finals. Original image is on the left.
Our data shows that Chef and Puppet peaked in 2017, when Kubernetes started an almost exponential growth spurt, as Figure 4 shows. A backlash is only to be expected when deeplearning applications are used to justify arresting the wrong people , and when some police departments are comfortable using software with a 98% false positive rate.
Or Alex Honnold, who free solo climbed El Capitan in Yosemite in June 2017 and lived to tell us about it. Fast forward to 2014, when I joined IBM as an associate partner in their Innovation Practice for Natural Resources, focusing on Cognitive (Watson IBMs version of AI and deeplearning models).
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content