This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Spotify Million Playlist Released for RecSys 2018, this dataset helps analyze short-term and sequential listening behavior. By, Avi Chawla - highly passionate about approaching and explaining datascience problems with intuition. Yelp Open Dataset Contains 8.6M reviews, but coverage is sparse and city-specific.
Watch highlights from expert talks covering datascience, machine learning, algorithmic accountability, and more. People from across the data world are coming together in New York for the Strata Data Conference. The future of data warehousing. Watch " Managing risk in machine learning.".
In 2017, we published “ How Companies Are Putting AI to Work Through DeepLearning ,” a report based on a survey we ran aiming to help leaders better understand how organizations are applying AI through deeplearning. We found companies were planning to use deeplearning over the next 12-18 months.
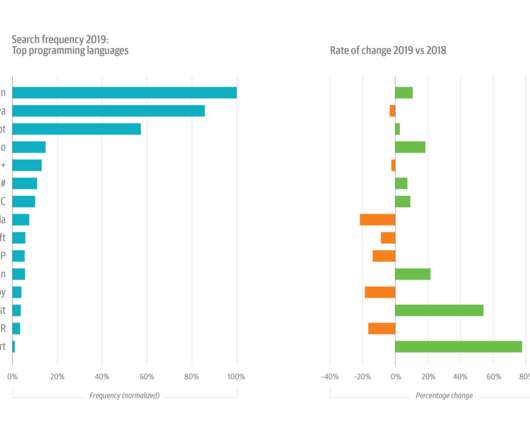
Growth is still strong for such a large topic, but usage slowed in 2018 (+13%) and cooled significantly in 2019, growing by just 7%. Within the data topic, however, ML+AI has gone from 22% of all usage to 26%. In 2019, as in 2018, Python was the most popular language on O’Reilly online learning. Security is surging.
Datascience has become an extremely rewarding career choice for people interested in extracting, manipulating, and generating insights out of large volumes of data. To fully leverage the power of datascience, scientists often need to obtain skills in databases, statistical programming tools, and data visualizations.
This is a good time to assess enterprise activities, as there are many indications a number of companies are already beginning to use machine learning. For example, in a July 2018 survey that drew more than 11,000 respondents, we found strong engagement among companies: 51% stated they already had machine learning models in production.
DeepLearning. Temporal data and time-series. Automation in datascience and big data. At the 2018 Strata Data London, data privacy and GDPR were big topics. In fact, our 2018 conference happened the same week GDPR came online. Text and Language processing and analysis.
Introduction In 2018, when we were contemplating whether AI would take over our jobs or not, OpenAI put us on the edge of believing that. Our way of working has completely changed after the inception of OpenAI’s ChatGPT in 2022. But is it a threat or a boon?
University can be a great way to learndatascience. Luckily, a few of them are willing to share datascience, machine learning and deeplearning materials online for everyone. However, many universities are very expensive, difficult to get admitted, or not geographically feasible.
The importance of datascience and machine learning continues to grow in business and beyond. I did my part this year to spread interest in datascience to more people. Below are my top 10 blog posts of 2018: Favorite DataScience Blogs, Podcasts and Newsletters. Click image to enlarge.
Many thanks to Addison-Wesley Professional for providing the permissions to excerpt “Natural Language Processing” from the book, DeepLearning Illustrated by Krohn , Beyleveld , and Bassens. The excerpt covers how to create word vectors and utilize them as an input into a deeplearning model. Introduction.
In a related post we discussed the Cold Start Problem in DataScience — how do you start to build a model when you have either no training data or no clear choice of model parameters. Workshop on Meta-Learning (MetaLearn 2018).
It is a high-level, multifaceted field that allows machines to iteratively learn and understand complex representations from images and videos to automate human visual tasks. How DeepLearning scales based on the amount of Data [Copyright: Andrew Ng ]. He currently works as a Data Scientist at Lowe’s Companies, Inc.
Language understanding benefits from every part of the fast-improving ABC of software: AI (freely available deeplearning libraries like PyText and language models like BERT ), big data (Hadoop, Spark, and Spark NLP ), and cloud (GPU's on demand and NLP-as-a-service from all the major cloud providers). IBM Watson NLU.
Niels Kasch , cofounder of Miner & Kasch , an AI and DataScience consulting firm, provides insight from a deeplearning session that occurred at the Maryland DataScience Conference. You may also remember UMBC from the miracle at the 2018 NCAA Tournament.) DeepLearning on Imagery and Text.
In deeplearning, as in typical neural network models, the method by which those adjustments to the model parameters are estimated ( i.e., for each of the edge weights between the network nodes) is called backpropagation. .”
In other words, using metadata about datascience work to generate code. In this case, code gets generated for data preparation, where so much of the “time and labor” in datascience work is concentrated. Scale the problem to handle complex data structures. BTW, videos for Rev2 are up: [link].
Watermarking is a term borrowed from the deeplearning security literature that often refers to putting special pixels into an image to trigger a desired outcome from your model. It seems entirely possible to do the same with customer or transactional data. Machine Learning 81.2 DZone (2018). ACM (2018).
Do you know what datascience is? Do you understand what data scientists do? Just so we’re on the same page, what is datascience? Here are my thoughts from 2014 on defining datascience as the intersection of software engineering and statistics , and a more recent post on defining datascience in 2018.
Their first challenge, the 2018 Call for Code Global Challenge , is a competition that asks developers to create solutions to reduce the deleterious impact of natural disasters on human lives, health, and wellbeing by improving the current state of natural disaster preparedness. Data is the Fuel; DataScience is the Engine.
What if there was a way to quantitatively measure whether your machine learning (ML) model reflects specific domain expertise or potential bias? TCAV “uses directional derivatives to quantify the degree to which a user-defined concept is important to a classification result” ( Kim et al 2018 ). MLConf 2018. Introduction.
2018) Simple meaningless data processing steps, may cause saliency methods to result in significant changes (Kindermans et al., DeepLIFT was recently proposed as a recursive prediction explanation method for deeplearning [8, 7]. This is an exciting and important area of datascience research. Saliency Maps.
This wasn’t about teaching deeplearning, but about maintaining infrastructure that doesn’t break when an AI tool plugs in.” AI amplifies the need for automation, and teams need to collaborate across domains: datascience, DevOps, and IT,” he says. Not just to plan, but to co-own and co-create success.”
Datascience teams in industry must work with lots of text, one of the top four categories of data used in machine learning. That’s excellent for supporting really interesting workflow integrations in datascience work. Usually it’s human-generated text, but not always.
The top three items are essentially “the devil you know” for firms which want to invest in datascience: data platform, integration, data prep. Data governance shows up as the fourth-most-popular kind of solution that enterprise teams were adopting or evaluating during 2019. More Policies Emerged” (2010-2018).
Paco Nathan covers recent research on data infrastructure as well as adoption of machine learning and AI in the enterprise. Welcome back to our monthly series about datascience! This month, the theme is not specifically about conference summaries; rather, it’s about a set of follow-up surveys from Strata Data attendees.
He is currently a machine learning engineer at Casetext where he works on natural language processing for the legal industry. In late 2018, Google open-sourced BERT, a powerful deeplearning algorithm for natural language processing. Prior to Insight, he was at IBM Watson.
It’s the underlying engine that gives generative models the enhanced reasoning and deeplearning capabilities that traditional machine learning models lack. A specific kind of foundation model known as a large language model (LLM) is trained on vast amounts of text data for NLP tasks.
Humans likely not even notice the difference but modern deeplearning networks suffered a lot. But apparently, models trained on text from 2017 experience degraded performance on text written in 2018. Machine Learning requires lots and lots of relevant training data. We might expect that.
For the Fall 2018 session of the Insight Fellows Program in NYC, we launched a new partnership with Thinknum , a company that provides alternative data indexed from the web to institutional investors and corporations? Utilize information hidden away in online employee reviews.
It was deeply gratifying to see so many organizations deploying the tools and techniques of datascience and advanced analytics to solve difficult and important problems. I predict that next year’s competition will be even more amazing as we continue pushing the frontiers of datascience forward. Societal Impact:
Further, deeplearning methods are built on the foundation of signal processing. The post Building a Speaker Recognition Model appeared first on DataScience Blog by Domino. While more advanced models for speaker verification exist, this blog will form a basis of speech signal processing. References: [1] [link]. [2]
Our analysis of ML- and AI-related data from the O’Reilly online learning platform indicates: Unsupervised learning surged in 2019, with usage up by 172%. Deeplearning cooled slightly in 2019, slipping 10% relative to 2018, but deeplearning still accounted for 22% of all AI/ML usage.
Will a network trained with fake data be able to generalize to the real world? Lauren Holzbauer was an Insight Fellow in Summer 2018. Keras is an open source deeplearning API that was written in Python and runs on top of Tensorflow, so it’s a little more user-friendly and high-level than Tensorflow.
Paco Nathan presented, “DataScience, Past & Future” , at Rev. At Rev’s “ DataScience, Past & Future” , Paco Nathan covered contextual insight into some common impactful themes over the decades that also provided a “lens” help data scientists, researchers, and leaders consider the future.
The lens of reductionism and an overemphasis on engineering becomes an Achilles heel for datascience work. Instead, consider a “full stack” tracing from the point of data collection all the way out through inference. Machine learning model interpretability. 2018-06-21). back to the structure of the dataset.
As machine learning (ML) algorithms increase in popularity and the “black boxes” of neural networks in deeplearning (DL) become the industry standard, pulling out the demographic information and the user history responsible for each undesired rec becomes next to impossible to achieve.
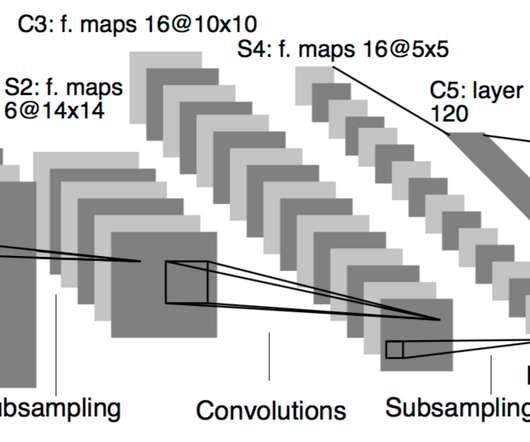
Lauren Holzbauer was an Insight Fellow in Summer 2018. Since CNNs are no longer built this way, we won’t go into any further detail here (but you can read about them here: "Key DeepLearning Architectures: LeNet-5" and of course in the original paper ). Let’s use our ninja skills to figure out what CNNs are really doing.
Machine learning, artificial intelligence, data engineering, and architecture are driving the data space. The Strata Data Conferences helped chronicle the birth of big data, as well as the emergence of datascience, streaming, and machine learning (ML) as disruptive phenomena. 221) to 2019 (No.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content