This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Valuable for local business research, yet not optimal for large-scale generalizable models. Spotify Million Playlist Released for RecSys 2018, this dataset helps analyze short-term and sequential listening behavior. Yelp Open Dataset Contains 8.6M reviews, but coverage is sparse and city-specific.
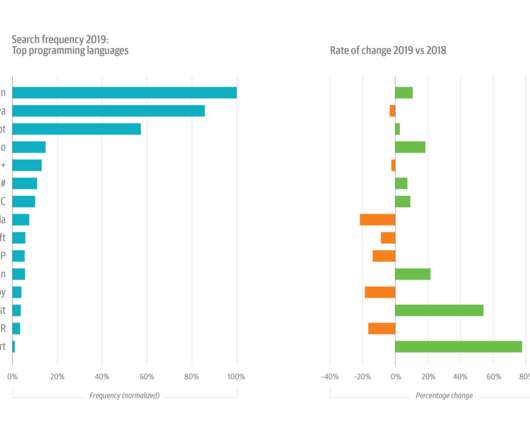
Growth is still strong for such a large topic, but usage slowed in 2018 (+13%) and cooled significantly in 2019, growing by just 7%. But sustained interest in cloud migrations—usage was up almost 10% in 2019, on top of 30% in 2018—gets at another important emerging trend. ML + AI are up, but passions have cooled. Security is surging.
This is a good time to assess enterprise activities, as there are many indications a number of companies are already beginning to use machine learning. For example, in a July 2018 survey that drew more than 11,000 respondents, we found strong engagement among companies: 51% stated they already had machine learning models in production.
Many thanks to Addison-Wesley Professional for providing the permissions to excerpt “Natural Language Processing” from the book, DeepLearning Illustrated by Krohn , Beyleveld , and Bassens. The excerpt covers how to create word vectors and utilize them as an input into a deeplearning model. Introduction.
Language understanding benefits from every part of the fast-improving ABC of software: AI (freely available deeplearning libraries like PyText and language models like BERT ), big data (Hadoop, Spark, and Spark NLP ), and cloud (GPU's on demand and NLP-as-a-service from all the major cloud providers). IBM Watson NLU.
So, you start by assuming a value for k and making random assumptions about the cluster means, and then iterate until you find the optimal set of clusters, based upon some evaluation metric. What is missing in the above discussion is the deeper set of unknowns in the learning process. This is the meta-learning phase.
All of my top blog posts of 2018 (most reads) are all related to data science, with posts that address the practice of data science, artificial intelligence and machine learning tools and methods that are commonly used and even a post on the problems with the Net Promoter Score claims.
If we cannot know that ( i.e., because it truly is unsupervised learning), then we would like to know at least that our final model is optimal (in some way) in explaining the data. This challenge is known as the cold-start problem ! In those intermediate steps it serves as an evaluation (or validation) metric.
SQL optimization provides helpful analogies, given how SQL queries get translated into query graphs internally , then the real smarts of a SQL engine work over that graph. Part of the back-end processing needs deeplearning (graph embedding) while other parts make use of reinforcement learning. AutoPandas: Origins.
LexisNexis has been playing with BERT, a family of natural language processing (NLP) models, since Google introduced it in 2018, as well as Chat GPT since its inception. We will pick the optimal LLM. We’ll take the optimal model to answer the question that the customer asks.” But the foray isn’t entirely new.
Data science tools are used for drilling down into complex data by extracting, processing, and analyzing structured or unstructured data to effectively generate useful information while combining computer science, statistics, predictive analytics, and deeplearning. The TIOBE index confirms that the popularity of Python is increasing.
2018) Simple meaningless data processing steps, may cause saliency methods to result in significant changes (Kindermans et al., Lately, however, there is very exciting research emerging around building concepts from first principles with the goal of optimizing the higher layers to be human-readable. Saliency Maps. Interpretable CNNs.
There are a large number of tools used in AI, including versions of search and mathematical optimization, logic, methods based on probability and economics, and many others. Likewise, 2018 was the year of virtual assistants: Alexa, Cortana, all of them have taken the consumers’ market by storm.
billion in 2018. It can also be used to analyze driver behaviors to optimize fuel stops, personal breaks and more. When it comes to fleet maintenance, big data can aid in monitoring vehicle handling and operation to optimize trips, preserve equipment and waylay potential breakdowns. Organizations have already realized this.
A transformer is a type of AI deeplearning model that was first introduced by Google in a research paper in 2017. ChatGPT was trained with 175 billion parameters; for comparison, GPT-2 was 1.5B (2019), Google’s LaMBDA was 137B (2021), and Google’s BERT was 0.3B (2018). What is ChatGPT? ChatGPT is a product of OpenAI.
Legacy data center networking technologies just aren’t optimized to support the ultra-low latencies and high reliability and scalability to match unprecedented volumes of data, network responsiveness, and security demands of this AI era,” says Manish Gulyani , Nokia’s CMO for Network Infrastructure.
Starting in 2018, the agency used agents, in the form of Raspberry PI computers running biologically-inspired neural networks and time series models, as the foundation of a cooperative network of sensors. These projects include those that simplify customer service and optimize employee workflows.
It’s important to note that machine learning for natural language got a big boost during the mid-2000’s as Google began to win international language translation competitions. The use cases for natural language have shifted dramatically over the past two years, after deeplearning techniques arose to the fore.
Most recently, she has served as EVP and chief customer and technology officer at Ameren, which she joined 2018 as SVP and chief digital and information officer before adding customer experience and operations in 2023. It has been around since the 1950s with machine learning. However, this advancement doesn’t come without risks.
That wasn’t a fluke either, as the 2019 numbers were four times higher than 2018. To create a productive, cost-effective analytics strategy that gets results, you need high performance hardware that’s optimized to work with the software you use. Just starting out with analytics?
O’Reilly Media published our analysis as free mini-books: The State of Machine Learning Adoption in the Enterprise (Aug 2018). The data types used in deeplearning are interesting. The data types used in deeplearning are interesting. One-fifth use reinforcement learning.
Humans likely not even notice the difference but modern deeplearning networks suffered a lot. But apparently, models trained on text from 2017 experience degraded performance on text written in 2018. Machine Learning requires lots and lots of relevant training data. We might expect that.
It’s the underlying engine that gives generative models the enhanced reasoning and deeplearning capabilities that traditional machine learning models lack. An open-source model, Google created BERT in 2018.
Lauren Holzbauer was an Insight Fellow in Summer 2018. Keras is an open source deeplearning API that was written in Python and runs on top of Tensorflow, so it’s a little more user-friendly and high-level than Tensorflow. We pass 3 parameters: loss, optimizer , and metrics. Check out the Keras documentation here.
. — Mike Barlow, author of “Learning to Love Data Science” (O’Reilly Media). And now, without further delay, we are excited to announce the winners of the 2018 Data Impact Awards, listed by award theme and category: Business Impact. Two weeks ago, we announced the finalists.
For the Fall 2018 session of the Insight Fellows Program in NYC, we launched a new partnership with Thinknum , a company that provides alternative data indexed from the web to institutional investors and corporations? Utilize information hidden away in online employee reviews. Yanxia Li earned her Ph.D.
Emphasizing data-driven decision-making in Aurora In 2018, the City of Aurora, Ill., The city hopes AI tools will help streamline administrative processes, automate routine tasks, and optimize resource allocation. Prototyping the smart San Antonio of the future In 2023, the City of San Antonio launched its Smarter Together initiative.
2018-06-21). For example, in the case of more recent deeplearning work, a complete explanation might be possible: it might also entail an incomprehensible number of parameters. Perhaps if machine learning were solely being used to optimize advertising or ecommerce, then Agile-ish notions could serve well enough.
and drop your deeplearning model resource footprint by 5-6 orders of magnitude and run it on devices that don’t even have batteries. The year 2018 was what Wall Street Journal called “ a global reckoning on data governance.” Machine learning is a subset of mathematical optimization.
As machine learning (ML) algorithms increase in popularity and the “black boxes” of neural networks in deeplearning (DL) become the industry standard, pulling out the demographic information and the user history responsible for each undesired rec becomes next to impossible to achieve.
So, we used a form of the Term Frequency-Inverse Document Frequency (TF/IDF) technique to identify and rank the top terms in this year’s Strata NY proposal topics—as well as those for 2018, 2017, and 2016. 2) is unchanged from Strata NY 2018, it’s up three places from Strata NY 2017—and eight places relative to 2016. 221) to 2019 (No.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content