This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The new survey, which ran for a few weeks in December 2019, generated an enthusiastic 1,388 responses. Supervised learning is the most popular ML technique among mature AI adopters, while deeplearning is the most popular technique among organizations that are still evaluating AI. But what kind?
Apply fair and private models, white-hat and forensic model debugging, and common sense to protect machine learningmodels from malicious actors. Like many others, I’ve known for some time that machine learningmodels themselves could pose security risks.
Not least is the broadening realization that ML models can fail. And that’s why model debugging, the art and science of understanding and fixing problems in ML models, is so critical to the future of ML. Because all ML models make mistakes, everyone who cares about ML should also care about model debugging. [1]
Companies successfully adopt machine learning either by building on existing data products and services, or by modernizing existing models and algorithms. I will highlight the results of a recent survey on machine learning adoption, and along the way describe recent trends in data and machine learning (ML) within companies.
Deeplearningmodels are revolutionizing the business and technology world with jaw-dropping performances in one application area after another. Read this post on some of the numerous composite technologies which allow deeplearning its complex nonlinearity.
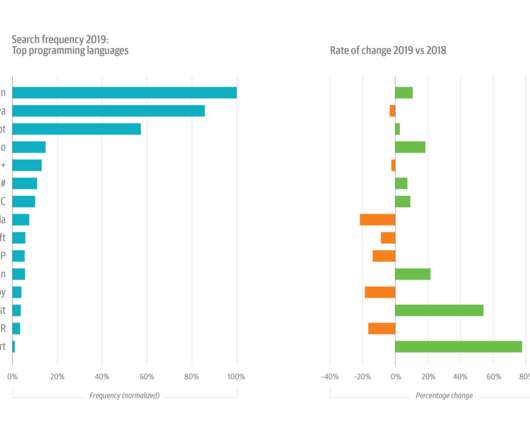
Growth is still strong for such a large topic, but usage slowed in 2018 (+13%) and cooled significantly in 2019, growing by just 7%. But sustained interest in cloud migrations—usage was up almost 10% in 2019, on top of 30% in 2018—gets at another important emerging trend. Still cloud-y, but with a possibility of migration.
In this post, I demonstrate how deeplearning can be used to significantly improve upon earlier methods, with an emphasis on classifying short sequences as being human, viral, or bacterial. As I discovered, deeplearning is a powerful tool for short sequence classification and is likely to be useful in many other applications as well.
Getting trained neural networks to be deployed in applications and services can pose challenges for infrastructure managers. Challenges like multiple frameworks, underutilized infrastructure and lack of standard implementations can even cause AI projects to fail. This blog explores how to navigate these challenges.
In this post, I’ll describe some of the key areas of interest and concern highlighted by respondents from Europe, while describing how some of these topics will be covered at the upcoming Strata Data conference in London (April 29 - May 2, 2019). Machine Learningmodel lifecycle management. DeepLearning.
Improvements in documentation, ease-of-use, and its production-ready implementation of key deeplearningmodels, combined with speed, scalability, and accuracy has made Spark NLP a viable option for enterprises needing an NLP library. A three-part series on “Comparing production-grade NLP libraries”.
DataOps needs a directed graph-based workflow that contains all the data access, integration, model and visualization steps in the data analytic production process. ModelOps and MLOps fall under the umbrella of DataOps,with a specific focus on the automation of data science model development and deployment workflows.
Beyond that, we recommend setting up the appropriate data management and engineering framework including infrastructure, harmonization, governance, toolset strategy, automation, and operating model. It is also important to have a strong test and learn culture to encourage rapid experimentation. What differentiates Fractal Analytics?
Instead of writing code with hard-coded algorithms and rules that always behave in a predictable manner, ML engineers collect a large number of examples of input and output pairs and use them as training data for their models. The model is produced by code, but it isn’t code; it’s an artifact of the code and the training data.
Big data is vital for helping SEO companies identify and rectify inefficiencies in their models. There are a number of deeplearning tools that evaluate social media activity. Local businesses need to rely heavily on SEO in 2019. Deeplearning and other big data tools will be essential in the year is moving forward.
In the last few years, we’ve seen a lot of breakthroughs in reinforcement learning (RL). From 2013 with the first deeplearningmodel to successfully learn a policy directly from pixel input using reinforcement learning to the OpenAI Dexterity project in 2019, we live in an exciting moment in RL research.
While we’ve seen traces of this in 2019, it’s in 2020 that computer vision will make a significant mark in both the consumer and business world. Already in our shortlist of tech buzzwords 2019, artificial intelligence is on the front scene for next year again. Artificial Intelligence (AI). Connected Retail. Hyperautomation.
A Data Scientist : Organizations who show how they improved analytics, delivered new actionable intelligence, or designed systems for distributed deeplearning and artificial intelligence to the organization’s business and customers. Stay tuned for March 19, 2019 as the winners are unveiled at the Luminaries dinner in Barcelona.
Recently, researchers from the Google Brain team published a paper proposing a new method called Concept Activation Vectors (CAVs) that takes a new angle to the interpretability of deeplearningmodels.
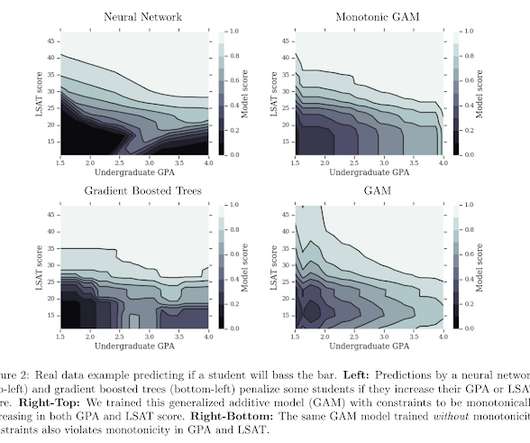
by TAMAN NARAYAN & SEN ZHAO A data scientist is often in possession of domain knowledge which she cannot easily apply to the structure of the model. On the one hand, basic statistical models (e.g. On the other hand, sophisticated machine learningmodels are flexible in their form but not easy to control.
While the revolution of deeplearning now impacts our daily lives, these networks are expensive. Approaches in transfer learning promise to ease this burden by enabling the re-use of trained models -- and this hands-on tutorial will walk you through a transfer learning technique you can run on your laptop.
A transformer is a type of AI deeplearningmodel that was first introduced by Google in a research paper in 2017. Five years later, transformer architecture has evolved to create powerful models such as ChatGPT. Meanwhile, however, many other labs have been developing their own generative AI models.
We’ve been working on this for over a decade, including transformer-based deeplearning,” says Shivananda. An example of the impact of AI can be seen from 2019 to 2022, when the company’s loss rate reduced by almost half, in part thanks to advances in algorithms and AI technology.
As OpenAI’s exclusive cloud provider it will see additional revenue for its Azure services, as one of OpenAI’s biggest costs is providing the computing capacity to train and run its AI models. The deal, announced by OpenAI and Microsoft on Jan. Additionally, it may not always be able to understand or respond to certain inputs correctly.”
When training a neural network in deeplearning, its performance on processing new data is key. Improving the model's ability to generalize relies on preventing overfitting using these important methods.
Anyone working on non-trivial deeplearningmodels in Pytorch such as industrial researchers, Ph.D. The models we're talking about here might be taking you multiple days to train or even weeks or months. Who is this guide for? students, academics, etc.
Paco Nathan ‘s latest article covers program synthesis, AutoPandas, model-driven data queries, and more. See also: Caroline Lemieux’s slides for that NeurIPS talk, and Rohan Bavishi’s video from the RISE Summer Retreat 2019. Introduction. Welcome back to our monthly burst of themespotting and conference summaries.
Generative Adversarial Networks are driving important new technologies in deeplearning methods. With so much to learn, these two videos will help you jump into your exploration with GANs and the mathematics behind the modelling.
Those numbers represent the projected growth of chatbot interactions among banking customers between 2019 to 2023 and the cost savings from 862 hours less of work by support personnel, according to research by Juniper Research. In business, when a trend is forecast to grow by more than 3000% and generate cost savings of $7.3
BANGALORE, May 14, 2019. BRIDGEi2i is pleased to host Alex Smola – VP & Distinguished Scientist at AWS for an informative and hands-on learning session on Computer Vision GluconCV & D2L.ai on 18th May 2019 at the BRIDGEi2i auditorium. For more details on the meetup, please click here. About Alex Smola.
We have configured the default Compute Environment in Domino to include all of the packages, libraries, models, and data you’ll need for this tutorial. That nlp variable is now your gateway to all things spaCy and loaded with the en_core_web_sm small model for English. deeplearning on edge devices. Getting Started.
Derek Driggs, a machine learning researcher at the University of Cambridge, together with his colleagues, published a paper in Nature Machine Intelligence that explored the use of deeplearningmodels for diagnosing the virus. The paper determined the technique not fit for clinical use.
With multiple technologies involved, even deeplearning algorithms can’t do the trick. 2019 witnessed record-breaking AI funding, and it’s mostly possible because, over the years, decision making has […]. The domain of AI and data science so far has created significant value in the technological landscape.
If you want to learn more about self-service BI tools, you can take a look at this review: 5 Most Popular Business Intelligence (BI) Tools in 2019 , to understand your own needs and then choose the tool that is right for you. Of course, other BI tools such as Power BI and Qlikview also have their own advantages. From Google.
This week on KDnuggets: Beyond Word Embedding: Key Ideas in Document Embedding; The problem with metrics is a big problem for AI; Activation maps for deeplearningmodels in a few lines of code; There is No Such Thing as a Free Lunch; 8 Paths to Getting a Machine Learning Job Interview; and much, much more.
Ludwig is a tool that allows people to build data-based deeplearningmodels to make predictions. In September 2019, Google decided to make it’s Differential Privacy Library available as an open-source tool. Here are some open-source options to consider.
In other words, structured data has a pre-defined data model , whereas unstructured data doesn’t. . It facilitates AI because, to be useful, many AI models require large amounts of data for training. DeepLearning, a subset of AI algorithms, typically requires large amounts of human annotated data to be useful.
O’Reilly Media published our analysis as free mini-books: The State of Machine Learning Adoption in the Enterprise (Aug 2018). Evolving Data Infrastructure: Tools and Best Practices for Advanced Analytics and AI (Jan 2019). AI Adoption in the Enterprise: How Companies Are Planning and Prioritizing AI Projects in Practice (Feb 2019).
It is pretty impressive just how much has changed in the enterprise machine learning and AI landscape. Thinking back to the conversations I had in late 2019, early 2020, most of the mainstream organizations I was talking to, meaning not the Facebooks and the Googles of the world, had very similar machine learning and AI journeys.
ChatGPT e le hallucination sui casi giudiziari I progressi compiuti nel 2023 dai large language models (LLM) hanno suscitato un interesse diffuso per il potenziale di trasformazione dell’IA generativa in quasi tutti i settori. “Anche quando è la tecnologia ad automatizzare la discriminazione, la responsabilità ricade sul datore di lavoro”.
Also: Activation maps for deeplearningmodels in a few lines of code; The 4 Quadrants of Data Science Skills and 7 Principles for Creating a Viral Data Visualization; OpenAI Tried to Train AI Agents to Play Hide-And-Seek but Instead They Were Shocked by What They Learned; 10 Great Python Resources for Aspiring Data Scientists.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content