This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Later in 2019, the researchers proposed the ALBERT (“A Lite BERT”) model for self-supervised learning of language representations, which shares the same architectural backbone as BERT. The post ALBERT Model for Self-Supervised Learning appeared first on Analytics Vidhya. The key […].
She is one of the eminent speakers at DataHack Summit 2019, where she will be talking about. The post Regime Shift Models – A Fascinating Use Case of Time Series Modeling appeared first on Analytics Vidhya. This article is written by Sonam Srivastava.
Chris Taggart explains the benefits of white box data and outlines the structural shifts that are moving the data world toward this model. Watch " Privacy, identity, and autonomy in the age of big data and AI.". --> Continue reading Highlights from the Strata Data Conference in London 2019. Watch " The enterprise data cloud.".
Apply fair and private models, white-hat and forensic model debugging, and common sense to protect machine learning models from malicious actors. Like many others, I’ve known for some time that machine learning models themselves could pose security risks. This is like a denial-of-service (DOS) attack on your model itself.
The new survey, which ran for a few weeks in December 2019, generated an enthusiastic 1,388 responses. This year, about 15% of respondent organizations are not doing anything with AI, down ~20% from our 2019 survey. It seems as if the experimental AI projects of 2019 have borne fruit. But what kind? Bottlenecks to AI adoption.
Not least is the broadening realization that ML models can fail. And that’s why model debugging, the art and science of understanding and fixing problems in ML models, is so critical to the future of ML. Because all ML models make mistakes, everyone who cares about ML should also care about model debugging. [1]
Watch “ Personalization of Spotify Home and TensorFlow “ TensorFlow Hub: The platform to share and discover pretrained models for TensorFlow. Mike Liang discusses TensorFlow Hub, a platform where developers can share and discover pretrained models and benefit from transfer learning.
Growth is still strong for such a large topic, but usage slowed in 2018 (+13%) and cooled significantly in 2019, growing by just 7%. But sustained interest in cloud migrations—usage was up almost 10% in 2019, on top of 30% in 2018—gets at another important emerging trend. Still cloud-y, but with a possibility of migration.
Machine learning needs to ensure privacy, both of the training data and the model, and needs to be fair and invulnerable to tampering. Continue reading Strata San Francisco, 2019: Opportunities and Risks. Shafi Goldwasser challenged developers to create “Safe ML” : machine learning that can’t be abused.
In this interview from O’Reilly Foo Camp 2019, Dean Wampler, head of evangelism at Anyscale.io, talks about moving AI and machine learning into real-time production environments. ’ or something like this, I need to know exactly what model was used and how it was trained. Are you prejudiced against me?’
In this interview from O’Reilly Foo Camp 2019, Eric Jonas, assistant professor at the University of Chicago, pierces the hype around artificial intelligence. Highlights from the interview include: Jonas argues that “AI is a lie”—meaning that our expectations far outsize the reality of what’s currently possible.
Companies successfully adopt machine learning either by building on existing data products and services, or by modernizing existing models and algorithms. For example, in a July 2018 survey that drew more than 11,000 respondents, we found strong engagement among companies: 51% stated they already had machine learning models in production.
When we started with generative AI and large language models, we leveraged what providers offered in the cloud. Now that we have a few AI use cases in production, were starting to dabble with in-house hosted, managed, small language models or domain-specific language models that dont need to sit in the cloud.
In this post, I’ll describe some of the key areas of interest and concern highlighted by respondents from Europe, while describing how some of these topics will be covered at the upcoming Strata Data conference in London (April 29 - May 2, 2019). Machine Learning model lifecycle management. Transportation and Logistics.
Once you have deployed your machine learning model into production, differences in real-world data will result in model drift. This guide defines model drift and how to identify it, and includes approaches to enable model training. So, retraining and redeploying will likely be required.
Instead of writing code with hard-coded algorithms and rules that always behave in a predictable manner, ML engineers collect a large number of examples of input and output pairs and use them as training data for their models. The model is produced by code, but it isn’t code; it’s an artifact of the code and the training data.
This article quotes an older market projection (from 2019) , which estimated “the global industrial IoT market could reach $14.2 Another dimension to this story, of course, is the Future of Work discussion, including creation of new job titles and roles, and the demise of older job titles and roles. trillion by 2030.”.
Paul Beswick, CIO of Marsh McLennan, served as a general strategy consultant for most of his 23 years at the firm but was tapped in 2019 to relaunch the risk, insurance, and consulting services powerhouse’s global digital practice. Gen AI is quite different because the models are pre-trained,” Beswick explains.
DataOps needs a directed graph-based workflow that contains all the data access, integration, model and visualization steps in the data analytic production process. ModelOps and MLOps fall under the umbrella of DataOps,with a specific focus on the automation of data science model development and deployment workflows.
SaaS is a software distribution model that offers a lot of agility and cost-effectiveness for companies, which is why it’s such a reliable option for numerous business models and industries. 2019 was a breakthrough year for the SaaS world in many ways. Instead, they have the option of utilizing various pricing structures.
When we create our machine learning models, a common task that falls on us is how to tune them. So that brings us to the quintessential question: Can we automate this process?
In this interview from O’Reilly Foo Camp 2019, Hands-On Unsupervised Learning Using Python author Ankur Patel discusses the challenges and opportunities in making machine learning and AI accessible and financially viable for enterprise applications. Then you have pre-trained models you can do transfer learning with.
From obscurity to ubiquity, the rise of large language models (LLMs) is a testament to rapid technological advancement. Just a few short years ago, models like GPT-1 (2018) and GPT-2 (2019) barely registered a blip on anyone’s tech radar. We paused the activities and got to work modeling the costs.
While we’ve seen traces of this in 2019, it’s in 2020 that computer vision will make a significant mark in both the consumer and business world. Already in our shortlist of tech buzzwords 2019, artificial intelligence is on the front scene for next year again. Artificial Intelligence (AI). Connected Retail. Hyperautomation.
Azure Machine Learning is an environment to help with all the aspects of data science from data cleaning to model training to deployment. Azure Machine Learning now has a new web interface and it just got support for the R programming language. Python support has been available for a while. Visual Studio Online.
Paul Beswick, CIO of Marsh McLellan, served as a general strategy consultant for most of his 23 years at the firm but was tapped in 2019 to relaunch the risk, insurance, and consulting services powerhouse’s global digital practice. Gen AI is quite different because the models are pre-trained,” Beswick explains.
Big data is vital for helping SEO companies identify and rectify inefficiencies in their models. Local businesses need to rely heavily on SEO in 2019. The post 5 Ways Local SEO Companies Are Optimizing Their Models With Big Data appeared first on SmartData Collective. Familiarity with local slang and trends.
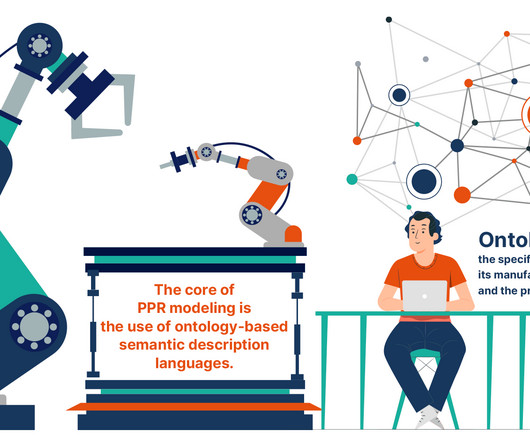
In the ever-evolving field of automation, the need for sophisticated models to efficiently describe and manage complex tasks has never been greater. This blog post delves into the PPR modeling paradigm, highlighting its significance and application in robot-based automation. What is the PPR Modeling Paradigm?
In 2019, I was asked to write the Foreword for the book “ Graph Algorithms: Practical Examples in Apache Spark and Neo4j “ , by Mark Needham and Amy E. And this: perhaps the most powerful node in a graph model for real-world use cases might be “context”. How does one express “context” in a data model?
Improvements in documentation, ease-of-use, and its production-ready implementation of key deep learning models, combined with speed, scalability, and accuracy has made Spark NLP a viable option for enterprises needing an NLP library. Related content : “Lessons learned building natural language processing systems in health care”.
2019 was a particularly major year for the business intelligence industry. Marketers determine customer responses or purchases and set up cross-sell opportunities, whereas bankers use it to generate a credit score – the number generated by a predictive model that incorporates all of the data relevant to a person’s creditworthiness.
At times it may seem Machine Learning can be done these days without a sound statistical background but those people are not really understanding the different nuances. Code written to make it easier does not negate the need for an in-depth understanding of the problem.
After developing a machine learning model, you need a place to run your model and serve predictions. If your company is in the early stage of its AI journey or has budget constraints, you may struggle to find a deployment system for your model. Also, a column in the dataset indicates if each flight had arrived on time or late.
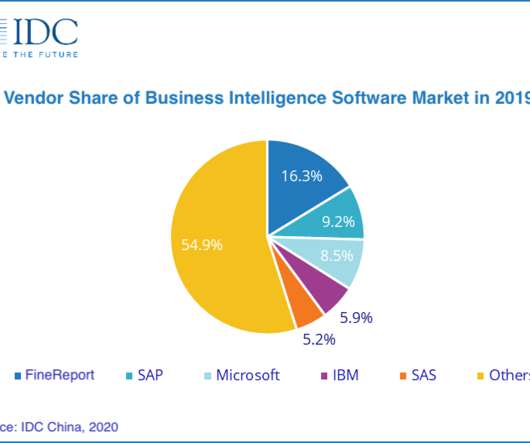
According to “IDC Semiannual Software Tracker for the Second Half of 2019”, the scale of China’s business intelligence software market reached US$490 million in 2019, with a year-on-year increase of 22.6%. In terms of deployment models, in 2019, traditional deployment models accounted for 82.7% billion U.S.
Gartner included data fabrics in their top ten trends for data and analytics in 2019. Data fabrics provide reusable services that span data integration, access, transformation, modeling, visualization, governance, and delivery. From an industry perspective, the topic of data fabrics is on fire. What is a Data Fabric?
The ISACA announced an updated version of COBIT in 2018, ditching the version number and naming it COBIT 2019. COBIT 2019 was introduced to build governance strategies that are more flexible and collaborative and that address new and changing technology.
From 2013 with the first deep learning model to successfully learn a policy directly from pixel input using reinforcement learning to the OpenAI Dexterity project in 2019, we live in an exciting moment in RL research. In the last few years, we’ve seen a lot of breakthroughs in reinforcement learning (RL).
Since 5G networks began rolling out commercially in 2019, telecom carriers have faced a wide range of new challenges: managing high-velocity workloads, reducing infrastructure costs, and adopting AI and automation. As with many industries, the future of telecommunications lies in AI and automation.
Recently, AI researchers from IBM open sourced AI Explainability 360, a new toolkit of state-of-the-art algorithms that support the interpretability and explainability of machine learning models.
Getting trained neural networks to be deployed in applications and services can pose challenges for infrastructure managers. Challenges like multiple frameworks, underutilized infrastructure and lack of standard implementations can even cause AI projects to fail. This blog explores how to navigate these challenges.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content