This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Some solutions provide read and write access to any type of source and information, advanced integration, security capabilities and metadata management that help achieve virtual and high-performance Data Services in real-time, cache or batch mode. How does Data Virtualization complement Data Warehousing and SOA Architectures?
In this blog, we will share with you in detail how Cloudera integrates core compute engines including Apache Hive and Apache Impala in Cloudera DataWarehouse with Iceberg. We will publish follow up blogs for other data services. Iceberg basics Iceberg is an open table format designed for large analytic workloads.
In this post, we are excited to summarize the features that the AWS Glue Data Catalog, AWS Glue crawler, and Lake Formation teams delivered in 2022. Whether you are a data platform builder, data engineer, data scientist, or any technology leader interested in data lake solutions, this post is for you.
We are pleased to announce that Cloudera has been named a Leader in the 2022 Gartner ® Magic Quadrant for Cloud Database Management Systems. Cloudera has long had the capabilities of a data lakehouse, if not the label. 4-Ready for modern data fabric architectures. 4-Ready for modern data fabric architectures.
Data architect Armando Vázquez identifies eight common types of data architects: Enterprise data architect: These data architects oversee an organization’s overall data architecture, defining data architecture strategy and designing and implementing architectures. Are data architects in demand?
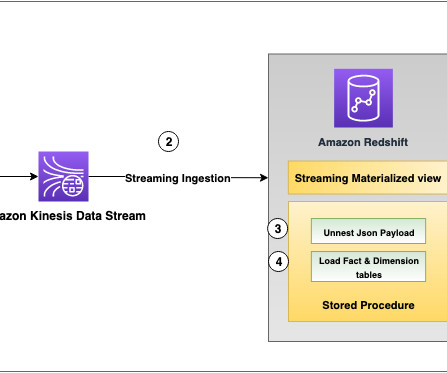
Amazon Redshift is a fully managed, scalable cloud datawarehouse that accelerates your time to insights with fast, easy, and secure analytics at scale. Tens of thousands of customers rely on Amazon Redshift to analyze exabytes of data and run complex analytical queries, making it the widely used cloud datawarehouse.
Many customers run big data workloads such as extract, transform, and load (ETL) on Apache Hive to create a datawarehouse on Hadoop. We split the solution into two primary components: generating Spark job metadata and running the SQL on Amazon EMR. The script generates a metadata JSON file for each step.
Data engineers use Apache Iceberg because it’s fast, efficient, and reliable at any scale and keeps records of how datasets change over time. Apache Iceberg offers integrations with popular data processing frameworks such as Apache Spark, Apache Flink, Apache Hive, Presto, and more.
These lakes power mission critical large scale data analytics, business intelligence (BI), and machine learning use cases, including enterprise datawarehouses. In recent years, the term “data lakehouse” was coined to describe this architectural pattern of tabular analytics over data in the data lake.
External data sharing gets strategic Data sharing between business partners is becoming far easier and much more cooperative, observes Mike Bechtel, chief futurist at business advisory firm Deloitte Consulting. The fabric, especially at the active metadata level, is important, Saibene notes.
Apache Iceberg is an open table format for very large analytic datasets, which captures metadata information on the state of datasets as they evolve and change over time. Iceberg has become very popular for its support for ACID transactions in data lakes and features like schema and partition evolution, time travel, and rollback.
Why does AI need an open data lakehouse architecture? from 2022 to 2026. Another IDC study showed that while 2/3 of respondents reported using AI-driven data analytics, most reported that less than half of the data under management is available for this type of analytics. All of this supports the use of AI.
These lakes power mission critical large scale data analytics, business intelligence (BI), and machine learning use cases, including enterprise datawarehouses. In recent years, the term “data lakehouse” was coined to describe this architectural pattern of tabular analytics over data in the data lake.
To speed up the self-service analytics and foster innovation based on data, a solution was needed to provide ways to allow any team to create data products on their own in a decentralized manner. To create and manage the data products, smava uses Amazon Redshift , a cloud datawarehouse.
Please help us keep our #1 position in 2022. In data warehousing, the data is extracted and transported from production database(s) into a datawarehouse for reporting and analysis. Best Data Modeling Solution (erwin Data Modeler). Read more about erwin® Data Modeler by Quest.
Bayerische Motoren Werke AG (BMW) is a motor vehicle manufacturer headquartered in Germany with 149,475 employees worldwide and the profit before tax in the financial year 2022 was € 23.5 Data providers and consumers are the two fundamental users of a CDH dataset. The difference lies in when and where data transformation takes place.
With Cloudera’s vision of hybrid data , enterprises adopting an open data lakehouse can easily get application interoperability and portability to and from on premises environments and any public cloud without worrying about data scaling. Why integrate Apache Iceberg with Cloudera Data Platform?
Gartner defines a data fabric as “a design concept that serves as an integrated layer of data and connecting processes. The data fabric architectural approach can simplify data access in an organization and facilitate self-service data consumption at scale. 2 “Exposing The Data Mesh Blind Side ” Forrester.
This is the promise of the modern data lakehouse architecture. analyst Sumit Pal, in “Exploring Lakehouse Architecture and Use Cases,” published January 11, 2022: “Data lakehouses integrate and unify the capabilities of datawarehouses and data lakes, aiming to support AI, BI, ML, and data engineering on a single platform.”
MetaBio, which received a 2022 CIO 100 Award , provides a single source for datasets in a unified format, enabling researchers to quickly extract information about various therapeutic functions without having to worry about how to prepare or find the data. At the data pipeline level, scientists use Apigee, Airflow, NiFi, and Kafka.
This view is used to identify patterns and trends in customer behavior, which can inform data-driven decisions to improve business outcomes. In 2022, AWS commissioned a study conducted by the American Productivity and Quality Center (APQC) to quantify the Business Value of Customer 360.
dbt is an open source, SQL-first templating engine that allows you to write repeatable and extensible data transforms in Python and SQL. dbt is predominantly used by datawarehouses (such as Amazon Redshift ) customers who are looking to keep their data transform logic separate from storage and engine.
A recent VentureBeat article , “4 AI trends: It’s all about scale in 2022 (so far),” highlighted the importance of scalability. But it isn’t just aggregating data for models. Data needs to be prepared and analyzed. Different data types need different types of analytics – real-time, streaming, operational, datawarehouses.
This leads to having data across many instances of datawarehouses and data lakes using a modern data architecture in separate AWS accounts. We recently announced the integration of Amazon Redshift data sharing with AWS Lake Formation. See Managing LF-Tags for metadata access control for more details.
June 2017: Dresner Advisory Services names Alation the #1 data catalog in its inaugural Data Catalog End-User Market Study. August 2017: Alation debuts as a leader in the Gartner MQ for Metadata Management Solutions. August 2018: Gartner names Alation a 2X Leader in the MQ for Metadata Management Solutions.
A modern data architecture enables companies to ingest virtually any type of data through automated pipelines into a data lake, which provides highly durable and cost-effective object storage at petabyte or exabyte scale. Metadata table s eliminate slow S3 file listing operations.
AWS contributed the Apache Iceberg integration with the AWS Glue Data Catalog , which enables you to use open-source data computation engines like Apache Spark with Iceberg on AWS Glue. In 2022, Amazon Athena announced support of Iceberg , enabling transaction queries on S3 objects. Choose Add database.
As a result, Pimblett now runs the organization’s datawarehouse, analytics, and business intelligence. Establishing a clear and unified approach to data. In a first test of the technology, he used Alation to catalog a subset of Very’s data held in an old Teradata database. We’re a Power BI shop,” he says. “I
The datawarehouse and analytical data stores moved to the cloud and disaggregated into the data mesh. Today, the brightest minds in our industry are targeting the massive proliferation of data volumes and the accompanying but hard-to-find value locked within all that data. Architectures became fabrics.
Among the tasks necessary for internal and external compliance is the ability to report on the metadata of an AI model. Metadata includes details specific to an AI model such as: The AI model’s creation (when it was created, who created it, etc.) Learn more about IBM watsonx 1.
July brings summer vacations, holiday gatherings, and for the first time in two years, the return of the Massachusetts Institute of Technology (MIT) Chief Data Officer symposium as an in-person event. A key area of focus for the symposium this year was the design and deployment of modern data platforms. What is a data fabric?
Spoiler alert: data fabric and data mesh are independent design concepts that are, in fact, quite complementary. Data fabric has captured most of the limelight; it focuses on the technologies required to support metadata-driven use cases across hybrid and multi-cloud environments. Gartner on Data Fabric.
Thousands of customers rely on Amazon Redshift to build datawarehouses to accelerate time to insights with fast, simple, and secure analytics at scale and analyze data from terabytes to petabytes by running complex analytical queries. Data loading is one of the key aspects of maintaining a datawarehouse.
CSP was recently recognized as a leader in the 2022 GigaOm Radar for Streaming Data Platforms report. The DevOps/app dev team wants to know how data flows between such entities and understand the key performance metrics (KPMs) of these entities. Meet Laila, a very opinionated practitioner of Cloudera Stream Processing.
Log in to the Cloudera DataWarehouse service as DWAdmin. Go to the virtual warehouse tab, locate the Virtual Warehouse on which you want to enable this feature, and click “edit.” Log in to the datawarehouse service as DWAdmin. Log in to the datawarehouse service as DWAdmin.
This confirms that the opening statement has reached the top of organizations and that the consideration and development of a data culture should be anchored in the data strategy. Global survey This study was based on the findings of a worldwide online survey conducted in July and August 2022.
They took their centralized architecture and are creating a decentralized, cloud-native and domain-centric data environment. The Snowflake Data Cloud serves as their central repository for data and analytics, and their Alation data catalog now provides the metadata management capabilities to all data citizens.
Athena supports reading native Delta tables and therefore we can read the data successfully even though the Data Catalog shows only a single array column. If you need the individual column-level metadata to be available in the Data Catalog, run an AWS Glue crawler periodically to keep the AWS Glue metadata updated.
According to Entrepreneur , Gartner predicts, “through 2022, only 20% of organizations investing in information governance will succeed in scaling governance for digital business.” This survey result shows that organizations need a method to help them implement Data Governance at scale. Two problems arise.
Using bad data, or the incorrect data can generate devastating results. between 2022 and 2029. And the rise in data valuation has been compared to that of oil during the 19th century. The comparison makes sense because, like petroleum, data has enormous potential. This is where a reverse ETL process is needed.
According to our recent State of Cloud Data Security Report 2023 , 77% of organizations experienced a cloud data breach in 2022. That’s particularly concerning considering that 60% of worldwide corporate data was stored in the cloud during that same period.
Internet Explorer 11 on Windows 10 support will end June 2022. While it has many advantages, it’s not built to be a transactional reporting tool for day-to-day ad hoc analysis or easy drilling into data details. Java Applets support has ended on all modern browsers. Chrome: September 2015. FireFox: September 2018. Hubble Equivalent.
Using bad data, or the incorrect data can generate devastating results. between 2022 and 2029. And the rise in data valuation has been compared to that of oil during the 19th century. The comparison makes sense because, like petroleum, data has enormous potential. This is where a reverse ETL process is needed.
This integrated solution helps you unlock your enterprise data and gain actionable insights so you can act decisively in an uncertain and quickly changing world. was released in the first quarter of 2022. Seamless Integration with Cloud DataWarehouse Targets. Cloud data replication. Extend or Create New View.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content