This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
— VizWiz ‘Avengers’ characters’ appearances over time How the ‘Avengers’ Line-up Has Changed Over the Years — Wall Street Journal Multiple Income Households Flowingdata / Nathan Yau The Corruption Perceptions Index 2023 Week 35 | Power BI: Create a Faceted Instance Chart — Workout Wednesday / Meagan Longoria The post Chart (..)
Since its release in January 2021, the OpenSearch project has released 14 versions through June 2023. In this post, we provide a review of all the exciting features releases in OpenSearch Service in the first half of 2023. In July 2023, we previewed support for a third collection type: vector search.
Update your-iceberg-storage-blog in the following configuration with the bucket that you created to test this example. S3FileIO", "spark.sql.catalog.dev.warehouse":"s3://<your-iceberg-storage-blog>/iceberg/", "spark.sql.catalog.dev.s3.write.tags.write-tag-name":"created", write.tags.write-tag-name and s3.delete.tags.delete-tag-name
An in-place migration can be performed in either of two ways: Using add_files : This procedure adds existing data files to an existing Iceberg table with a new snapshot that includes the files. Unlike migrate or snapshot, add_files can import files from a specific partition or partitions and doesn’t create a new Iceberg table.
Whenever there is an update to the Iceberg table, a new snapshot of the table is created, and the metadata pointer points to the current table metadata file. At the top of the hierarchy is the metadata file, which stores information about the table’s schema, partition information, and snapshots. Choose Advanced options.
Smarten is pleased to announce that its Smarten Augmented Analytics solution is included as a Representative Vendor in the Market Guide for Augmented Analytics Published October 2, 2023 (ID G00780764). The Smarten Cloud Software-as-a-Service offering includes all of these features and is available for free evaluation.
To activate the automatic compaction process, add a new record to the existing Iceberg table using a Spark insert: spark.sql(""" Insert into dev.db.sensor_data_iceberg_format values(999123, 86, 'PASS', timestamp'2023-07-26 12:50:25') """) Navigate to the Amazon EMR console to check the cluster steps. impl":"org.apache.iceberg.aws.s3.S3FileIO",
Overview This blog post describes support for materialized views for the Iceberg table format. Create Iceberg materialized view For the examples in this blog, we will use three tables from the TPC-DS dataset as our base tables: store_sales, customer and date_dim. Both full and incremental rebuild of the materialized view are supported.
For this blog our “primary” workgroup is using Athena engine version 3. Create an S3 bucket to store the table data We create a new S3 bucket to save the data for the table: On the Amazon S3 console, create an S3 bucket with unique name (for this post, we use iceberg-athena-lakeformation-blog ). Choose Save.
In 2023, the FBI received a record number of 880,418 complaints with potential losses exceeding USD 12.5 When a cyberattack strikes, the ransomware code gathers information about target networks and key resources such as databases, critical files, snapshots and backups. Today, cybercrime is good business.
This post is designed to be implemented for a real customer use case, where you get full snapshot data on a daily basis. Run the AWS Glue job Confirm if you see the employee dataset in the path s3://scd-blog-landing/dataset/employee/. You can download the dataset and open it in a code editor such as VS Code.
This blog takes you on a journey into the world of Uber’s analytics and the critical role that Presto, the open source SQL query engine, plays in driving their success. They ingest data in snapshots from operational systems. The post Unleashing the power of Presto: The Uber case study appeared first on IBM Blog.
In 2023, AWS announced the upcoming deprecation of Data Pipeline , one of the core services used by Langley. However, it wasn’t created with multi-tenancy in mind and therefore it didn’t provide the robustness and the appropriate level of isolation to guard each tenant from impacting others on the shared platform.
In fact, according to the Identity Theft Resource Center (ITRC) Annual Data Breach Report , there were 2,365 cyber attacks in 2023 with more than 300 million victims, and a 72% increase in data breaches since 2021. The post Empower Your Cyber Defenders with Real-Time Analytics appeared first on Cloudera Blog.
Amazon Relational Database Service (Amazon RDS) for MySQL zero-ETL integration with Amazon Redshift was announced in preview at AWS re:Invent 2023 for Amazon RDS for MySQL version 8.0.28 The following is an example command: aws s3 cp 's3://redshift-blogs/zero-etl-integration/data/tickit'.
Here is a snapshot of some current results: We continued making progress towards our goal of net-zero operational greenhouse gas (GHG) emissions by 2030, underscored by energy conservation; use of renewable energy; and GHG emissions reduction. Also through year-end 2021, we reduced operational GHG emissions by 61.6%
Malicious actors came out swinging at the start of 2023, and they aren’t slowing down any time soon. Efficiently identifying the most recent clean snapshot (the point just before the malware intrusion and data compromise). Data breaches increased by 156% between Q1 and Q2 alone. Take MGM Resorts and Caesars Entertainment as examples.
According to Laminar research, more than 75% of organizations experienced a cloud data breach in 2023, which speaks for itself. Yet, managing this diverse environment creates challenges for the security, privacy and governance teams charged with protecting data. Unfortunately, the evidence shows we’re not doing a good job!
In fact, according to the Identity Theft Resource Center (ITRC) Annual Data Breach Report , there were 2,365 cyber attacks in 2023 with more than 300 million victims, and a 72% increase in data breaches since 2021. Today, cyber defenders face an unprecedented set of challenges as they work to secure and protect their organizations.
Although this provides immediate consistency and simplifies reads (because readers only access the latest snapshot of the data), it can become costly and slow for write-heavy workloads due to the need for frequent rewrites. xlarge using Amazon Linux 2023 running on one of those private subnets where you will launch the data simulator.
The first version of Talk to Your Graph (or TTYG for short) was released in 2023 and it was my baby. Introduction Since I became the product manager of GraphDB , I was expected to stop writing code but I couldnt help it. Its certainly unorthodox but I strongly believe this makes the product better.
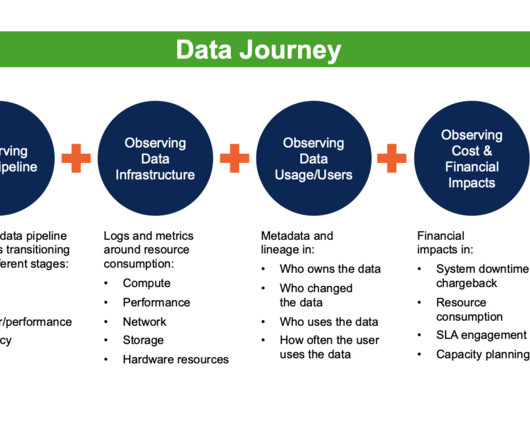
On 20 July 2023, Gartner released the article “ Innovation Insight: Data Observability Enables Proactive Data Quality ” by Melody Chien. Data Lineage, a form of static analysis , is like a snapshot or a historical record describing data assets at a specific time.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content