This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
If 2023 was the year of AI discovery and 2024 was that of AI experimentation, then 2025 will be the year that organisations seek to maximise AI-driven efficiencies and leverage AI for competitive advantage. Primary among these is the need to ensure the data that will power their AI strategies is fit for purpose.
Iceberg offers distinct advantages through its metadata layer over Parquet, such as improved data management, performance optimization, and integration with various query engines. Icebergs table format separates data files from metadata files, enabling efficient data modifications without full dataset rewrites.
The release of SAP Datasphere was launched and announced globally on March 8, 2023. Datasphere goes beyond the “big three” data usage end-user requirements (ease of discovery, access, and delivery) to include data orchestration (data ops and data transformations) and business data contextualization (semantics, metadata, catalog services).
Central to this is metadata management, a critical component for driving future success AI and ML need large amounts of accurate data for companies to get the most out of the technology. Let’s dive into what that looks like, what workarounds some IT teams use today, and why metadata management is the key to success.
Central to a transactional data lake are open table formats (OTFs) such as Apache Hudi , Apache Iceberg , and Delta Lake , which act as a metadata layer over columnar formats. Originally open sourced in November 2023 under the name OneTable, with contributions from amongst others OneHouse , it was licensed under Apache 2.0.
In this post, we are happy to summarize the results of our hard work in 2023 to improve and simplify data governance for customers. We announced our new features and capabilities during AWS re:Invent 2023, as is our custom every year. In 2023, we released several updates to AWS Glue crawlers. Bienvenue dans DataZone!
Amazon Q generative SQL for Amazon Redshift was launched in preview during AWS re:Invent 2023. It enables you to get insights faster without extensive knowledge of your organization’s complex database schema and metadata. It uses metadata from database schemas to improve the SQL query suggestions.
Now users seek methods that allow them to get even more relevant results through semantic understanding or even search through image visual similarities instead of textual search of metadata. We are excited about the OpenSearch Service features and enhancements we’ve added to that toolkit in 2023.
ANT 352 | [NEW LAUNCH] Amazon Q generative SQL in Amazon Redshift Query Editor SQL, the industry standard language for data analytics, often requires users to spend a lot of time understanding an organization’s complex metadata in order to write and carry out complex SQL queries for data insights.
My role was to talk about the trends and opportunities for 2023, for customers, SAP, and our partners. You lose the roots: the business context, the metadata, the connections, the hierarchies and security. This week I was in Dubai for the latest edition of the SAP Partner Innovation Meeting. Innovating Faster.
Since its release in January 2021, the OpenSearch project has released 14 versions through June 2023. In this post, we provide a review of all the exciting features releases in OpenSearch Service in the first half of 2023. In July 2023, we previewed support for a third collection type: vector search. in OpenSearch Service).
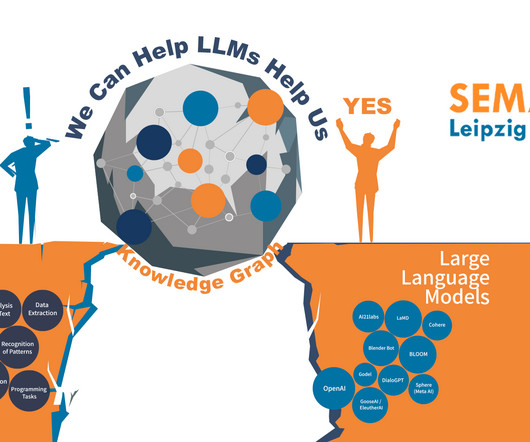
SEMANTiCS 2023 kicked off with a Pre-conference day that offered an awesome lineup of business and academia talks. Andreas Blumauer presenting his talk: Responsible AI and LLMs SEMANTiCS 2023 Andreas focused on how we can take the best of both worlds and work on responsible, explainable generative AI. Are LLMs Knowledgeable?
At AWS re:Invent 2023, we introduced more performance enhancements in query planning and execution such as enhanced bloom filters , query rewrites, and support for write operations in auto scaling. At AWS re:Invent 2023, we extended data sharing capabilities to launch multi-data warehouse writes in preview.
Predicts 2021: Data and Analytics Leaders Are Poised for Success but Risk an Uncertain Future : By 2023, 50% of chief digital officers in enterprises without a chief data officer (CDO) will need to become the de facto CDO to succeed. By 2023, ERP data will be the basis for 30% of AI-generated predictive analyses and forecasts.
So, KGF 2023 proved to be a breath of fresh air for anyone interested in topics like data mesh and data fabric , knowledge graphs, text analysis , large language model (LLM) integrations, retrieval augmented generation (RAG), chatbots, semantic data integration , and ontology building. Three presentations at the KGF 2023 proved it.
Generative AI is the biggest and hottest trend in AI (Artificial Intelligence) at the start of 2023. The latter is essential for Generative AI implementations. Love thy data: data are never perfect, but all the data may produce value, though not immediately.
Metadata management performs a critical role within the modern data management stack. However, as data volumes continue to grow, manual approaches to metadata management are sub-optimal and can result in missed opportunities. This puts into perspective the role of active metadata management. What is Active Metadata management?
I learned that fact from a comment in the audience on the second day of SEMANTICS 2023 – the European conference series focused on semantic technologies ever since 2005. Aidan Hogan at SEMANTiCS 2023. I didn’t either. What If ChatGPT Is the Killer App for the Semantic Web?
This means the data files in the data lake aren’t modified during the migration and all Apache Iceberg metadata files (manifests, manifest files, and table metadata files) are generated outside the purview of the data. In this method, the metadata are recreated in an isolated environment and colocated with the existing data files.
We’ve read many predictions for 2023 in the data field: they cover excellent topics like data mesh, observability, governance, lakehouses, LLMs, etc. Most data governance tools today start with the slow, waterfall building of metadata with data stewards and then hope to use that metadata to drive code that runs in production.
Join this session to learn how DIRECTV partnered with Alation to map their new dataverse, which includes Snowflake data sources (hubs), glossaries, enhanced metadata for metadata objects, lineage, and quality. They also recognized that to become 100% data- driven, first they had to become 100% metadata- driven.
Your business doesn’t stay still— and neither does the data landscape. While the next 12 months will no doubt contain many surprises, twists, and turns, one thing is certain. Data will continue passing through the veins of business industries and economies.
Apache Iceberg is an open table format for very large analytic datasets, which captures metadata information on the state of datasets as they evolve and change over time. Apache Iceberg addresses customer needs by capturing rich metadata information about the dataset at the time the individual data files are created.
Ehtisham Zaidi, Gartner’s VP of data management, and Robert Thanaraj, Gartner’s director of data management, gave an update on the fabric versus mesh debate in light of what they call the “active metadata era” we’re currently in. The active metadata helix Indeed, automation was on everyone’s minds. We couldn’t agree more.
The Common Crawl corpus contains petabytes of data, regularly collected since 2008, and contains raw webpage data, metadata extracts, and text extracts. Common Crawl data The Common Crawl raw dataset includes three types of data files: raw webpage data (WARC), metadata (WAT), and text extraction (WET).
In 2023, Onehouse announced an initiative to provide interoperability across table formats. Initially called Onetable, the project became Apache XTable in September 2024 and provides a lightweight translation layer to translate metadata between table formats without the need to duplicate or modify the data.
Files corresponding to a single day’s worth of data are placed under a prefix such as s3://my_bucket/logs/year=2023/month=06/day=01/. If the partition isn’t loaded into a partitioned table, when the application downloads the partition metadata, the application will not be aware of the S3 path that needs to be queried.
As noted in the Gartner Hype Cycle for Finance Data and Analytics Governance, 2023, “Through. The post My Understanding of the Gartner® Hype Cycle™ for Finance Data and Analytics Governance, 2023 appeared first on Data Management Blog - Data Integration and Modern Data Management Articles, Analysis and Information.
DGIQ is June 5-9, 2023, at the Catamaran Resort Hotel and Spa in San Diego, just steps away from the Mission Bay beach. He’ll share how “metadata normalization” played a key role in the journey to automation, the steps required to automate data governance processes, and why a data catalog was critical to the project’s success.
Google, which invented Transformers, knows better than anyone that Transformer-based models destroy metadata, unless you do a lot of special engineering. We can’t say for certain that it was implemented with RAG, but it clearly follows the pattern. But Google has the best search engine in the world.
I assert that through 2027, three-quarters of enterprises will be engaged in data intelligence initiatives to increase trust in their data by leveraging metadata to understand how, when and where data is used in their organization, and by whom. Collibra also announced the acquisition of Husprey in 2023 for its SQL data notebook functionality.
Denodo remains a specialist data management software provider and in September 2023 announced that it had received a $336 million investment from asset management firm TPG.
In 2023, AWS announced general availability for Apache Iceberg, Apache Hudi, and Linux Foundation Delta Lake in Amazon Athena for Apache Spark , which removes the need to install a separate connector or associated dependencies and manage versions, and simplifies the configuration steps required to use these frameworks.
You can use the Ontotext Metadata Studio (OMDS) to integrate any NER model and apply it to your documents to extract the entities you are interested in. There is no silver bullet: LLMs still need human validation and there does not seem to be one best model as weve seen that Llama-70b and GPT-4o perform differently on different tasks.
Iceberg tables store metadata in manifest files. As the number of data files increase, the amount of metadata stored in these manifest files also increases, leading to longer query planning time. The query runtime also increases because it’s proportional to the number of data or metadata file read operations.
RIO is really great",date("2023-04-06"),2023)""") You can check the new snapshot is created after this append operation by querying the Iceberg snapshot: spark.sql("""SELECT * FROM dev.db.amazon_reviews_iceberg.snapshots""").show() The metadata file location can be fetched from the metadata log entries metatable as illustrated earlier.
2023 has been a break-out year for generative AI technology, as tools such as ChatGPT graduated from lab curiosity to household name. July 2023 Microsoft adds Copilot abilities to Dynamics 365 suite Microsoft will roll out its Copilot generative AI assistant across more of its products.
We’re excited to share that Gartner has recognized Cloudera as a Visionary among all vendors evaluated in the 2023 Gartner® Magic Quadrant for Cloud Database Management Systems. Download the complimentary 2023 Gartner Magic Quadrant for Cloud Database Management Systems report.
As more industries mature digitally and widely adopt AI and machine learning technologies, 2023 will be a pivotal year for organizations looking to deploy emerging tech solutions company-wide to fulfill business objectives. These features provide businesses with a common metadata, security, and governance model across all their data.
Currently, we have approximately 120,000 employees worldwide (as of March 2023), including group companies. As of November 2023, more than 200 projects and 37,000 users were onboarded. Provide and keep up to date with technical metadata for loaded data. Fujitsu Limited was established in Japan in 1935.
In this post, which is a matured version of my opening keynote at Ontotext’s Knowledge Graph Forum 2023 , I will start with evidence about the impact of complexity on the growth and efficiency of big enterprises. In both cases, semantic metadata is the glue that turns knowledge graphs into hubs of data, metadata, and content.
Complete the following steps to set up an EC2 instance for installing Jenkins: Launch an EC2 instance with the latest Amazon Linux 2023 AMI. Launch an EC2 instance Note : Make sure to deploy the EC2 instance for hosting Jenkins in the same VPC as the OpenSearch domain.
But even as we remember 2023 as the year when generative AI went ballistic, AI and its ML (machine learning) sidekick have been quietly evolving over several years to yield eye-opening insights and problem-solving productivity for IT organizations. And rightly so.
However, even the most powerful systems can experience performance degradation if they encounter anti-patterns like grossly inaccurate table statistics, such as the row count metadata. This can have a significant impact on overall query performance.
We organize all of the trending information in your field so you don't have to. Join 42,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content